As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Ciclo de vida do incidente no Incident Manager
AWS Systems Manager Incident Manager fornece uma step-by-step estrutura baseada nas melhores práticas para identificar e reagir a incidentes, como interrupções no serviço ou ameaças à segurança. O foco principal do Incident Manager é ajudar a restaurar os serviços ou aplicativos afetados ao normal o mais rápido possível por meio de uma solução completa de gerenciamento do ciclo de vida de incidentes.
Conforme ilustrado na ilustração a seguir, o Incident Manager fornece ferramentas e melhores práticas para cada fase do ciclo de vida do incidente:
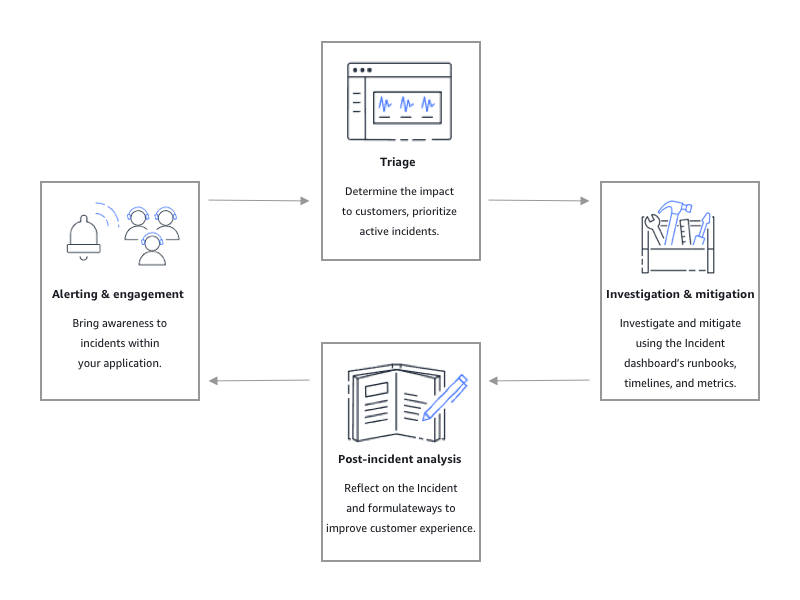
Alertas e engajamento
A fase de alerta e engajamento do ciclo de vida do incidente visa conscientizar sobre incidentes nos aplicativos e serviços. Essa fase começa antes que um incidente seja detectado e exige uma compreensão profunda dos aplicativos. Você pode usar CloudWatchas métricas da Amazon para monitorar dados sobre o desempenho de seus aplicativos ou usar EventBridge a Amazon para agregar alertas de diferentes fontes, aplicativos e serviços. Depois de configurar o monitoramento de seus aplicativos, você pode começar a alertar sobre métricas que fogem da norma histórica. Para saber mais sobre como monitorar as práticas recomendadas, consulte Monitoramento.
Para oferecer suporte aos respondentes no diagnóstico de incidentes, ative o atributo Descobertas no Incident Manager. As descobertas são informações sobre AWS CodeDeploy implantações e atualizações de AWS CloudFormation pilha que ocorreram na época de um incidente. Ter essas informações economiza tempo na avaliação de possíveis causas, o que pode reduzir o tempo médio de recuperação (MTTR) de um incidente.
Agora que você monitora incidentes nos aplicativos, é possível definir um plano de resposta a incidentes para usar durante incidentes. Para saber mais sobre como criar planos de resposta, consulte Criação e configuração de planos de resposta no Incident Manager. EventBridge Os eventos ou CloudWatch alarmes da Amazon podem criar automaticamente um incidente usando planos de resposta como modelo. Para saber mais sobre como criar incidentes, consulte Criação automática ou manual de incidentes no Gerenciador de incidentes.
Os planos de resposta lançam os respectivos planos de escalonamento e planos de engajamento para envolver os primeiros a responder no incidente. Para obter mais informações sobre como configurar planos de escalonamento, consulte Criar um plano de escalação. Simultaneamente, o Amazon Q Developer em aplicativos de bate-papo notifica os respondentes usando um canal de bate-papo que os direciona para a página de detalhes do incidente. Usando o canal de chat e os detalhes do incidente, a equipe pode se comunicar e fazer a triagem de um incidente. Para obter mais informações sobre configuração de canais de chat no Incident Manager, consulte Tarefa 2: Criar um canal de bate-papo no Amazon Q Developer em aplicativos de bate-papo.
Triagem
A triagem é quando os respondentes tentam determinar o impacto nos clientes. A visualização dos detalhes do incidente no console do Incident Manager fornece aos respondentes cronogramas e métricas para ajudar a avaliar o incidente. A avaliação do impacto de um incidente também estabelece as bases para o tempo de resposta, resolução e comunicação do incidente. Os respondentes priorizam os incidentes usando classificações de impacto de 1 (crítico) a 5 (sem impacto).
Sua organização pode definir o escopo exato de cada classificação de impacto da maneira que preferir. A tabela a seguir fornece exemplos de como normalmente é definido cada nível de impacto.
| Código de impacto | Nome do impacto | Escopo definido por amostra |
|---|---|---|
1 |
Critical |
Falha total do aplicativo que afeta a maioria dos clientes. |
2 |
High |
Falha total do aplicativo que afeta uma parte dos clientes. |
3 |
Medium |
Falha parcial do aplicativo que afeta o cliente. |
4 |
Low |
Falhas intermitentes que têm impacto limitado nos clientes. |
5 |
No Impact |
Os clientes não estão sendo afetados no exato momento, mas é necessária uma ação urgente para evitar um impacto. |
Investigação e mitigação
A visualização de detalhes do incidente fornece à equipe runbooks, cronogramas e métricas. Para ver como você pode lidar com um incidente, consulte os Visualizando detalhes do incidente no console.
Os runbooks geralmente fornecem etapas de investigação e podem extrair dados ou tentar as soluções mais comuns automaticamente. Os runbooks também fornecem etapas claras e reproduzíveis, que sua equipe já tenha achado útil ao mitigar incidentes. A guia runbook foca na etapa atual do runbook e mostra as etapas anteriores e as próximas.
O Incident Manager faz uma integração com o Systems Manager Automation para criar runbooks. Use runbooks para:
-
Gerencie instâncias e AWS recursos
-
Executar scripts automaticamente
-
Gerenciar AWS CloudFormation recursos
Para obter mais informações sobre as ações de automação, consulte Referência de ações do Systems Manager Automation no Guia do usuário do AWS Systems Manager .
A guia Cronograma mostra quais ações foram tomadas. A linha do tempo registra cada um com um carimbo de data/hora e detalhes criados automaticamente. Para adicionar eventos personalizados à linha do tempo, consulte a seção Linha do tempo na página Detalhes do incidente deste guia do usuário.
A guia Diagnóstico mostra métricas preenchidas automaticamente e métricas adicionadas manualmente. Essa visualização fornece informações valiosas sobre as atividades do aplicativo durante um incidente.
A guia Engajamentos permite adicionar mais contatos ao incidente e ajuda a fornecer os recursos para que o contato envolvido se atualize rapidamente depois de acionado. Os contatos são engajados seguindo os planos de escalonamento ou planos de engajamento pessoal definidos.
Pelo canal de chat, é possível interagir diretamente com o incidente e com outros respondentes da sua equipe. Usando o Amazon Q Developer em aplicativos de bate-papo, você pode configurar canais de bate-papo em. Slack, Microsoft Teamse o Amazon Chime. Em Slack and Microsoft Teams canais, os respondentes podem interagir com incidentes diretamente do canal de ssm-incidents bate-papo usando vários comandos. Para obter mais informações, consulte Como interagir pelo canal de chat.
Análise pós-incidente
O Incident Manager fornece toda a estrutura para refletir sobre um incidente, tomar as medidas necessárias para evitar que o incidente ocorra novamente no futuro e para melhorar as atividades gerais de resposta a incidentes. Entre as melhorias estão:
-
Alterações nos aplicativos envolvidos em um incidente. Sua equipe pode usar esse tempo para melhorar o sistema e torná-lo mais tolerante a falhas.
-
Mudanças no plano de resposta a incidentes. Reserve um tempo para incorporar as lições aprendidas.
-
Mudanças nos runbooks. Sua equipe pode se aprofundar nas etapas necessárias para a resolução e nas etapas que podem automatizar.
-
Alterações nos alertas. Depois de um incidente, sua equipe pode ter notado pontos críticos nas métricas que podem ser usados para alertar a equipe muito antes sobre um incidente.
O Incident Manager facilita essas possíveis melhorias aplicando um questionário de análise pós-incidente e itens de ação junto com o cronograma do incidente. Para saber mais sobre as melhorias por meio de análise, consulte Como realizar uma análise pós-incidente no Incident Manager.
