Aviso de fim do suporte: em 31 de maio de 2026, AWS encerrará o suporte para AWS Panorama. Depois de 31 de maio de 2026, você não poderá mais acessar o AWS Panorama console ou os AWS Panorama recursos. Para obter mais informações, consulte AWS Panorama Fim do suporte.
As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Modelos de visão computacional
Um modelo de visão computacional é um programa de software treinado para detectar objetos em imagens. Um modelo aprende a reconhecer um conjunto de objetos analisando primeiro as imagens desses objetos por meio de treinamento. Um modelo de visão computacional usa uma imagem como entrada e gera informações sobre os objetos que detecta, como tipo de objeto e sua localização. O AWS Panorama oferece suporte a modelos de visão computacional criados com PyTorch MXNet, Apache e. TensorFlow
nota
Para obter uma lista de modelos pré-criados que foram testados com o AWS Panorama, consulte Compatibilidade de modelos
Seções
Uso de modelos em código
Um modelo retorna um ou mais resultados, que podem incluir probabilidades de classes detectadas, informações de localização e outros dados. O exemplo a seguir mostra como executar inferência em uma imagem de um stream de vídeo e enviar a saída do modelo para uma função de processamento.
exemplo application.py
def process_media(self, stream): """Runs inference on a frame of video.""" image_data = preprocess(stream.image,self.MODEL_DIM) logger.debug('Image data: {}'.format(image_data)) # Run inference inference_start = time.time()inference_results = self.call({"data":image_data}, self.MODEL_NODE)# Log metrics inference_time = (time.time() - inference_start) * 1000 if inference_time > self.inference_time_max: self.inference_time_max = inference_time self.inference_time_ms += inference_time # Process results (classification)self.process_results(inference_results, stream)
O exemplo a seguir mostra uma função que processa resultados do modelo de classificação básico. O modelo de amostra retorna uma matriz de probabilidades, que é o primeiro e único valor na matriz de resultados.
exemplo application.py
def process_results(self, inference_results, stream): """Processes output tensors from a computer vision model and annotates a video frame.""" if inference_results is None: logger.warning("Inference results are None.") return max_results = 5 logger.debug('Inference results: {}'.format(inference_results)) class_tuple = inference_results[0] enum_vals = [(i, val) for i, val in enumerate(class_tuple[0])] sorted_vals = sorted(enum_vals, key=lambda tup: tup[1]) top_k = sorted_vals[::-1][:max_results] indexes = [tup[0] for tup in top_k] for j in range(max_results): label = 'Class [%s], with probability %.3f.'% (self.classes[indexes[j]], class_tuple[0][indexes[j]]) stream.add_label(label, 0.1, 0.1 + 0.1*j)
O código da aplicação encontra os valores com as maiores probabilidades e os mapeia para rótulos em um arquivo de recurso que é carregado durante a inicialização.
Criação de um modelo personalizado
Você pode usar modelos que você cria no PyTorch Apache MXNet e TensorFlow nos aplicativos do AWS Panorama. Como alternativa à criação e treinamento de modelos em SageMaker IA, você pode usar um modelo treinado ou criar e treinar seu próprio modelo com uma estrutura compatível e exportá-lo em um ambiente local ou na Amazon EC2.
nota
Para obter detalhes sobre as versões da estrutura e os formatos de arquivo suportados pelo SageMaker AI Neo, consulte Estruturas suportadas no Amazon SageMaker AI Developer Guide.
O repositório deste guia fornece um aplicativo de amostra que demonstra esse fluxo de trabalho para um modelo Keras em formato. TensorFlow SavedModel Ele usa TensorFlow 2 e pode ser executado localmente em um ambiente virtual ou em um contêiner Docker. O aplicativo de amostra também inclui modelos e scripts para criar o modelo em uma EC2 instância da Amazon.
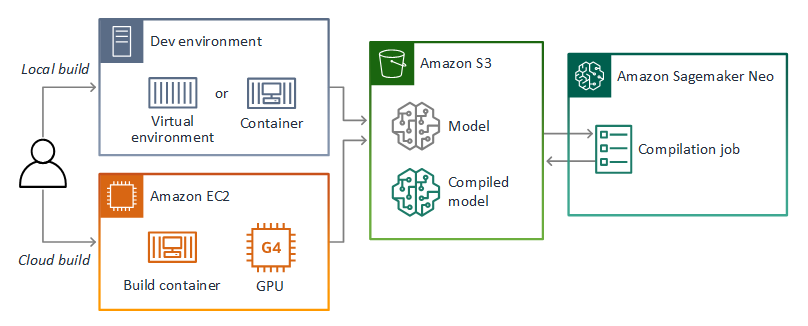
O AWS Panorama usa o SageMaker AI Neo para compilar modelos para uso no AWS Panorama Appliance. Para cada estrutura, use o formato compatível com o SageMaker AI Neo e empacote o modelo em um .tar.gz arquivo.
Para obter mais informações, consulte Compilar e implantar modelos com o Neo no Amazon SageMaker AI Developer Guide.
Empacotamento de um modelo
Um pacote de modelos abrange um descritor, uma configuração de pacote e um arquivo de modelos. Assim como em um pacote de imagem da aplicação, a configuração do pacote informa ao serviço AWS Panorama onde o modelo e o descritor estão armazenados no Amazon S3.
exemplo packages/123456789012-SQUEEZENET_PYTORCH-1.0/descriptor.json
{ "mlModelDescriptor": { "envelopeVersion": "2021-01-01", "framework": "PYTORCH", "frameworkVersion": "1.8", "precisionMode": "FP16", "inputs": [ { "name": "data", "shape": [ 1, 3, 224, 224 ] } ] } }
nota
Especifique somente a versão principal e secundária da versão da estrutura. Para obter uma lista das versões compatíveis PyTorch, do Apache MXNet e TensorFlow das versões, consulte Estruturas suportadas.
Para importar um modelo, use o comando import-raw-model da CLI da aplicação do AWS Panorama. Se você fizer alguma alteração no modelo ou em seu descritor, será necessário executar novamente esse comando para atualizar os ativos da aplicação. Para obter mais informações, consulte Alteração do modelo de visão computacional.
Para o esquema JSON do arquivo descritor, consulte assetDescriptor.schema.json
Modelos de treinamento
Ao treinar um modelo, use imagens do ambiente de destino ou de um ambiente de teste que se assemelhe muito ao ambiente de destino. Considere os seguintes fatores que podem afetar o desempenho do modelo:
-
Iluminação: a quantidade de luz refletida por um objeto determina a quantidade de detalhes que o modelo precisa analisar. Um modelo treinado com imagens de objetos bem iluminados pode não funcionar bem em um ambiente com pouca luz ou baixa retroiluminação.
-
Resolução: o tamanho da entrada de um modelo geralmente é fixado em uma resolução entre 224 e 512 pixels de largura em uma proporção quadrada. Antes de passar um quadro de vídeo para o modelo, você pode reduzi-lo ou cortá-lo para que ela caiba no tamanho necessário.
-
Distorção da imagem: a distância focal e o formato da lente da câmera podem fazer com que as imagens exibam distorção longe do centro do quadro. A posição de uma câmera também determina quais atributos de um objeto são visíveis. Por exemplo, uma câmera suspensa com lente grande angular mostrará a parte superior de um objeto quando ele estiver no centro do quadro e uma visão distorcida da lateral do objeto à medida que ele se afasta do centro.
Para resolver esses problemas, você pode pré-processar imagens antes de enviá-las ao modelo e treinar o modelo com uma variedade maior de imagens que refletem variações em ambientes do mundo real. Se um modelo precisar operar em situações de iluminação e com várias câmeras, você precisará de mais dados para o treinamento. Além de coletar mais imagens, você pode obter mais dados de treinamento criando variações de suas imagens existentes que estão distorcidas ou têm iluminação diferente.
