As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Emule matrizes PL/SQL associativas Oracle no Amazon Aurora PostgreSQL e no Amazon RDS for PostgreSQL
Rajkumar Raghuwanshi, Bhanu Ganesh Gudivada e Sachin Khanna, da Amazon Web Services
Resumo
Esse padrão descreve como emular matrizes PL/SQL associativas Oracle com posições de índice vazias nos ambientes Amazon Aurora PostgreSQL e Amazon RDS for PostgreSQL
Fornecemos uma alternativa do PostgreSQL ao aws_oracle_ext uso de funções para lidar com posições de índice vazias ao migrar um banco de dados Oracle. Esse padrão usa uma coluna adicional para armazenar as posições do índice e mantém o tratamento de matrizes esparsas pela Oracle, ao mesmo tempo em que incorpora recursos nativos do PostgreSQL.
Oracle
No Oracle, as coleções podem ser inicializadas como vazias e preenchidas usando o método EXTEND collection, que acrescenta NULL elementos à matriz. Ao trabalhar com matrizes PL/SQL associativas indexadas porPLS_INTEGER, o EXTEND método adiciona NULL elementos sequencialmente, mas os elementos também podem ser inicializados em posições de índice não sequenciais. Qualquer posição de índice que não seja inicializada explicitamente permanece vazia.
Essa flexibilidade permite estruturas de matriz esparsas nas quais os elementos podem ser preenchidos em posições arbitrárias. Ao iterar por meio de coleções usando FOR LOOP com FIRST e LAST limites, somente os elementos inicializados (com NULL ou com um valor definido) são processados, enquanto as posições vazias são ignoradas.
PostgreSQL (Amazon Aurora e Amazon RDS)
O PostgreSQL manipula valores vazios de forma diferente dos valores. NULL Ele armazena valores vazios como entidades distintas que usam um byte de armazenamento. Quando uma matriz tem valores vazios, o PostgreSQL atribui posições de índice sequenciais da mesma forma que valores não vazios. Mas a indexação sequencial requer processamento adicional porque o sistema deve percorrer todas as posições indexadas, incluindo as vazias. Isso torna a criação tradicional de matrizes ineficiente para conjuntos de dados esparsos.
AWS Schema Conversion Tool
O AWS Schema Conversion Tool (AWS SCT) normalmente lida com Oracle-to-PostgreSQL migrações usando aws_oracle_ext funções. Nesse padrão, propomos uma abordagem alternativa que usa recursos nativos do PostgreSQL, que combina os tipos de matriz do PostgreSQL com uma coluna adicional para armazenar as posições do índice. O sistema pode então iterar por meio de matrizes usando apenas a coluna de índice.
Pré-requisitos e limitações
Pré-requisitos
Um ativo Conta da AWS.
Um usuário AWS Identity and Access Management (IAM) com permissões de administrador.
Uma instância compatível com o Amazon RDS ou o Aurora PostgreSQL.
Uma compreensão básica dos bancos de dados relacionais.
Limitações
Alguns Serviços da AWS não estão disponíveis em todos Regiões da AWS. Para ver a disponibilidade da região, consulte Serviços da AWS por região
. Para endpoints específicos, consulte a página de endpoints e cotas do serviço e escolha o link para o serviço.
Versões do produto
Esse padrão foi testado com as seguintes versões:
Amazon Aurora PostgreSQL 13.3
Amazon RDS para PostgreSQL 13.3
AWS SCT 1.0.674
Oracle 12c EE 12.2
Arquitetura
Pilha de tecnologia de origem
Banco de dados on-premises da Oracle
Pilha de tecnologias de destino
Amazon Aurora PostgreSQL
Amazon RDS para PostgreSQL
Arquitetura de destino
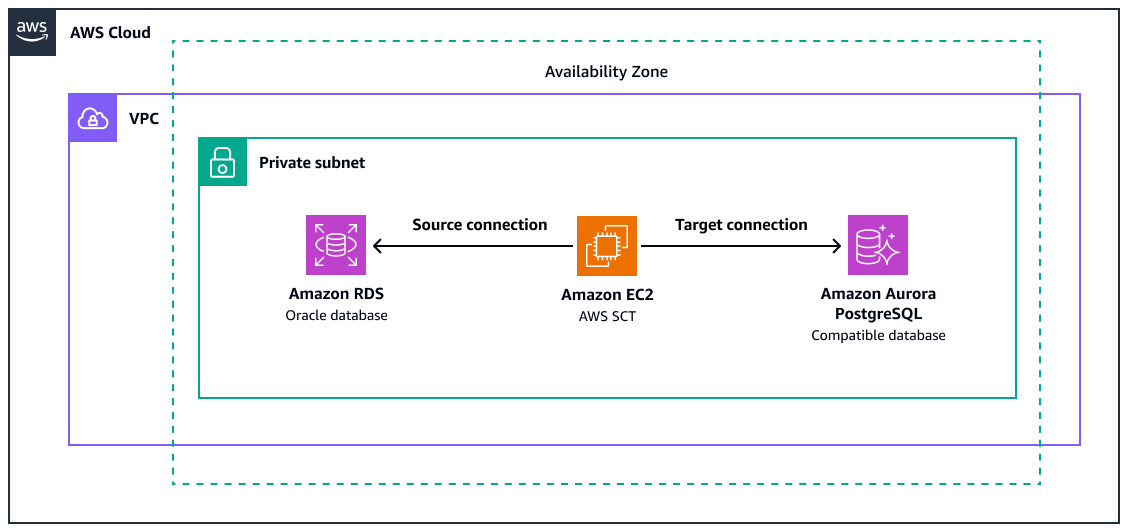
O diagrama mostra o seguinte:
Uma instância de banco de dados de origem do Amazon RDS for Oracle
Uma EC2 instância da Amazon AWS SCT para converter funções Oracle para o equivalente do PostgreSQL
Um banco de dados de destino compatível com o Amazon Aurora PostgreSQL
Ferramentas
Serviços da AWS
O Amazon Aurora é um mecanismo de banco de dados relacional totalmente gerenciado criado para a nuvem e compatível com o MySQL e o PostgreSQL.
O Amazon Aurora Edição Compatível com PostgreSQL é um mecanismo de banco de dados relacional totalmente gerenciado e compatível com ACID que ajuda você a configurar, operar e escalar implantações do PostgreSQL.
O Amazon Elastic Compute Cloud (Amazon EC2) fornece capacidade de computação escalável no. Nuvem AWS Você poderá iniciar quantos servidores virtuais precisar e escalá-los na vertical rapidamente.
O Amazon Relational Database Service (Amazon RDS) ajuda você a configurar, operar e escalar um banco de dados relacional no. Nuvem AWS
O Amazon Relational Database Service (Amazon RDS) para Oracle ajuda você a configurar, operar e escalar um banco de dados relacional Oracle no. Nuvem AWS
O Amazon Relational Database Service (Amazon RDS) para PostgreSQL ajuda você a configurar, operar e escalar um banco de dados relacional PostgreSQL no. Nuvem AWS
AWS Schema Conversion Tool (AWS SCT) oferece suporte a migrações heterogêneas de bancos de dados convertendo automaticamente o esquema do banco de dados de origem e a maior parte do código personalizado em um formato compatível com o banco de dados de destino.
Outras ferramentas
O Oracle SQL Developer
é um ambiente de desenvolvimento integrado que simplifica o desenvolvimento e o gerenciamento de bancos de dados Oracle em implantações tradicionais e baseadas em nuvem. O pgAdmin
é uma ferramenta de gerenciamento de código aberto para PostgreSQL. Ele fornece uma interface gráfica que ajuda você a criar, manter e usar objetos de banco de dados. Nesse padrão, o pgAdmin se conecta à instância do banco de dados RDS for PostgreSQL e consulta os dados. Como alternativa, você pode usar o cliente de linha de comando psql.
Práticas recomendadas
Limites do conjunto de dados de teste e cenários periféricos.
Considere implementar o tratamento de erros para condições de out-of-bounds índice.
Otimize as consultas para evitar a digitalização de conjuntos de dados esparsos.
Épicos
| Tarefa | Descrição | Habilidades necessárias |
|---|---|---|
Crie um PL/SQL bloco de origem no Oracle. | Crie um PL/SQL bloco de origem no Oracle que use a seguinte matriz associativa:
| DBA |
Execute o PL/SQL quarteirão. | Execute o PL/SQL bloco de origem no Oracle. Se houver lacunas entre os valores de índice de uma matriz associativa, nenhum dado será armazenado nessas lacunas. Isso permite que o loop Oracle itere somente pelas posições do índice. | DBA |
Revise a saída. | Cinco elementos foram inseridos na matriz (
| DBA |
| Tarefa | Descrição | Habilidades necessárias |
|---|---|---|
Crie um PL/pgSQL bloco de destino no PostgreSQL. | Crie um PL/pgSQL bloco de destino no PostgreSQL que use a seguinte matriz associativa:
| DBA |
Execute o PL/pgSQL quarteirão. | Execute o PL/pgSQL bloco de destino no PostgreSQL. Se houver lacunas entre os valores de índice de uma matriz associativa, nenhum dado será armazenado nessas lacunas. Isso permite que o loop Oracle itere somente pelas posições do índice. | DBA |
Revise a saída. | O comprimento da matriz é maior que 5 porque
| DBA |
| Tarefa | Descrição | Habilidades necessárias |
|---|---|---|
Crie um PL/pgSQL bloco de destino com uma matriz e um tipo definido pelo usuário. | Para otimizar o desempenho e combinar a funcionalidade da Oracle, podemos criar um tipo definido pelo usuário que armazena as posições do índice e os dados correspondentes. Essa abordagem reduz iterações desnecessárias ao manter associações diretas entre índices e valores.
| DBA |
Execute o PL/pgSQL quarteirão. | Execute o PL/pgSQL bloco alvo. Se houver lacunas entre os valores de índice de uma matriz associativa, nenhum dado será armazenado nessas lacunas. Isso permite que o loop Oracle itere somente pelas posições do índice. | DBA |
Revise a saída. | Conforme mostrado na saída a seguir, o tipo definido pelo usuário armazena somente elementos de dados preenchidos, o que significa que o comprimento da matriz corresponde ao número de valores. Como resultado,
| DBA |
Recursos relacionados
AWS documentação
Outra documentação
