As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Implantar modelos para inferência em tempo real
Importante
Políticas personalizadas do IAM que permitem que o Amazon SageMaker SageMaker Studio ou o Amazon Studio Classic criem SageMaker recursos da Amazon também devem conceder permissões para adicionar tags a esses recursos. A permissão para adicionar tags aos recursos é necessária porque o Studio e o Studio Classic marcam automaticamente todos os recursos que eles criam. Se uma política do IAM permitir que o Studio e o Studio Classic criem recursos, mas não permitisse a marcação, erros AccessDenied "" podem ocorrer ao tentar criar recursos. Para obter mais informações, consulte Forneça permissões para marcar recursos de SageMaker IA.
AWS políticas gerenciadas para Amazon SageMaker AIque dão permissões para criar SageMaker recursos já incluem permissões para adicionar tags ao criar esses recursos.
Há várias opções para implantar um modelo usando serviços de hospedagem de SageMaker IA. Você pode implantar interativamente um modelo com o SageMaker Studio. Ou você pode implantar programaticamente um modelo usando um AWS SDK, como o SDK do Python ou o SDK SageMaker for Python (Boto3). Você também pode implantar usando AWS CLI o.
Antes de começar
Antes de implantar um modelo de SageMaker IA, localize e anote o seguinte:
-
O Região da AWS local onde seu bucket do Amazon S3 está localizado
-
O caminho do URI do Amazon S3 em que os artefatos do modelo são armazenados
-
O papel do IAM para a SageMaker IA
-
O caminho de registro do URI do Docker Amazon ECR para a imagem personalizada que contém o código de inferência ou a estrutura e a versão de uma imagem Docker integrada que é suportada e por AWS
Para obter uma lista dos Serviços da AWS disponíveis em cada um Região da AWS, consulte Mapas de regiões e redes de borda
Importante
O bucket do S3 em que os artefatos do modelo são armazenados deve estar na mesma Região da AWS do modelo que você está criando.
Utilização compartilhada de recursos com vários modelos
Você pode implantar um ou mais modelos em um endpoint com a Amazon SageMaker AI. Quando vários modelos compartilham um endpoint, eles utilizam em conjunto os recursos que estão hospedados lá, como instâncias de computação de ML e aceleradores. CPUs A maneira mais flexível de implantar vários modelos em um endpoint é definir cada modelo como um componente de inferência.
Componentes de inferência
Um componente de inferência é um objeto de hospedagem de SageMaker IA que você pode usar para implantar um modelo em um endpoint. Nas configurações do componente de inferência, você especifica o modelo, o endpoint e como o modelo utiliza os recursos que o endpoint hospeda. Para especificar o modelo, você pode especificar um objeto do modelo de SageMaker IA ou especificar diretamente os artefatos e a imagem do modelo.
Nas configurações, você pode otimizar a utilização de recursos, adaptando a forma como os núcleos de CPU, os aceleradores e a memória necessária são alocados ao modelo. Você pode implantar vários componentes de inferência em um endpoint onde cada componente de inferência contém um modelo e as necessidades de utilização de recursos desse modelo.
Depois de implantar um componente de inferência, você pode invocar diretamente o modelo associado ao usar a InvokeEndpoint ação na SageMaker API.
Os componentes de inferência fornecem os seguintes benefícios:
- Flexibilidade
-
O componente de inferência desacopla os detalhes da hospedagem do modelo do próprio endpoint. Isso fornece mais flexibilidade e controle sobre como os modelos são hospedados e servidos com um endpoint. Você pode hospedar vários modelos na mesma infraestrutura e adicionar ou remover modelos de um endpoint conforme necessário. Você pode atualizar cada modelo de forma independente.
- Escalabilidade
-
Você pode especificar quantas cópias de cada modelo hospedar e definir um número mínimo de cópias para garantir que o modelo seja carregado na quantidade necessária para atender às solicitações. Você pode reduzir a escala horizontalmente de qualquer cópia do componente de inferência até zero, o que abre espaço para aumentar a escala verticalmente de outra cópia.
SageMaker A IA empacota seus modelos como componentes de inferência quando você os implanta usando:
-
SageMaker Estúdio clássico.
-
O SDK do SageMaker Python para implantar um objeto Model (onde você define o tipo de endpoint).
EndpointType.INFERENCE_COMPONENT_BASED -
O AWS SDK para Python (Boto3) para definir
InferenceComponentobjetos que você implanta em um endpoint.
Implemente modelos com o SageMaker Studio
Conclua as etapas a seguir para criar e implantar seu modelo de forma interativa por meio do SageMaker Studio. Para obter mais informações sobre como configurar o Studio, consulte a documentação do Studio. Para obter mais orientações sobre vários cenários de implantação, consulte o blog Package e implante modelos clássicos de ML de forma fácil LLMs com o Amazon SageMaker AI —
Preparar artefatos e permissões
Conclua esta seção antes de criar um modelo no SageMaker Studio.
Você tem duas opções para trazer os artefatos e criar um modelo no Studio:
-
Você pode trazer um arquivo
tar.gzpré-empacotado que deve incluir os artefatos do modelo, qualquer código de inferência personalizado e todas as dependências listadas em um arquivorequirements.txt. -
SageMaker A IA pode empacotar seus artefatos para você. Você só precisa trazer os artefatos do modelo bruto e todas as dependências em um
requirements.txtarquivo, e a SageMaker IA pode fornecer o código de inferência padrão para você (ou você pode substituir o código padrão pelo seu próprio código de inferência personalizado). SageMaker A IA oferece suporte a essa opção para as seguintes estruturas: PyTorch, XGBoost.
Além de trazer seu modelo, sua função AWS Identity and Access Management (IAM) e um contêiner Docker (ou estrutura e versão desejadas para as quais a SageMaker IA tem um contêiner pré-construído), você também deve conceder permissões para criar e implantar modelos por meio do SageMaker AI Studio.
Você deve ter a AmazonSageMakerFullAccesspolítica anexada à sua função do IAM para poder acessar a SageMaker IA e outros serviços relevantes. Para ver os preços dos tipos de instância no Studio, você também deve anexar a AWS PriceListServiceFullAccesspolítica (ou, se não quiser anexar toda a política, mais especificamente, a pricing:GetProducts ação).
Se optar por carregar os artefatos do modelo ao criar um modelo (ou carregar um arquivo de amostra de carga útil para recomendações de inferência), você deverá criar um bucket do Amazon S3. O nome do bucket deve ser prefixado pela palavra SageMaker AI. Capitalizações alternativas de SageMaker IA também são aceitáveis: Sagemaker ou. sagemaker
Recomendamos usar a convenção de nomenclatura do bucket sagemaker-{. Esse bucket é usado para armazenar os artefatos que você carrega.Region}-{accountID}
Depois de criar o bucket, anexe a seguinte política de CORS (compartilhamento de recursos de origem cruzada) ao bucket:
[ { "AllowedHeaders": ["*"], "ExposeHeaders": ["Etag"], "AllowedMethods": ["PUT", "POST"], "AllowedOrigins": ['https://*.sagemaker.aws'], } ]
Você pode anexar uma política de CORS a um bucket do Amazon S3 usando qualquer um dos seguintes métodos:
-
Por meio da página Editar compartilhamento de recursos entre origens (CORS)
no console do Amazon S3 -
Usando a API do Amazon S3 PutBucketCors
-
Usando o put-bucket-cors AWS CLI comando:
aws s3api put-bucket-cors --bucket="..." --cors-configuration="..."
Criar um modelo implantável
Nesta etapa, você cria uma versão implantável do seu modelo em SageMaker IA fornecendo seus artefatos junto com especificações adicionais, como o contêiner e a estrutura desejados, qualquer código de inferência personalizado e configurações de rede.
Crie um modelo implantável no SageMaker Studio fazendo o seguinte:
-
Abra o aplicativo SageMaker Studio.
-
No painel de navegação à esquerda, selecione Modelos.
-
Escolha a guia Modelos implantáveis.
-
Na página Modelos implantáveis, escolha Criar.
-
Na página Criar modelo implantável, no campo Nome do modelo, insira um nome para o modelo.
Há várias outras seções para você preencher na página Criar modelo implantável.
A seção de Definição de contêiner se parece com a seguinte captura de tela:
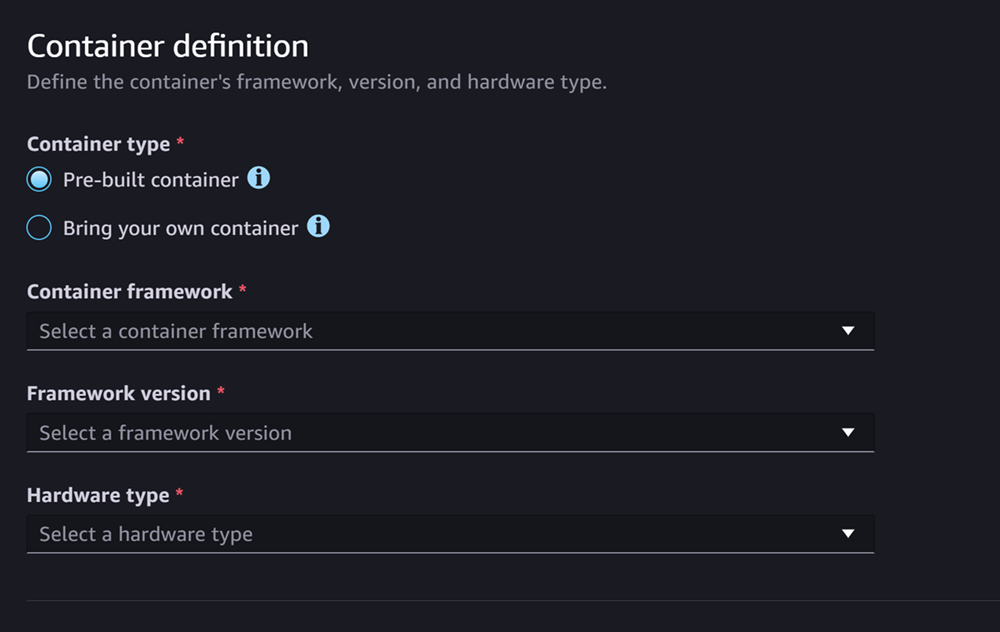
Na seção Definição de contêiner, faça o seguinte:
-
Em Tipo de contêiner, selecione Contêiner pré-construído se quiser usar um contêiner gerenciado por SageMaker IA ou selecione Traga seu próprio contêiner se você tiver seu próprio contêiner.
-
Se você selecionou Contêiner pré-construído, selecione o Framework do contêiner, a Versão do framework e o Tipo de hardware que gostaria de usar.
-
Se você selecionou Traga um contêiner próprio, insira um caminho do Amazon ECR em Caminho do ECR até a imagem do contêiner.
Em seguida, preencha a seção Artefatos, que se parece com a seguinte captura de tela:

Para a seção Artefatos, faça o seguinte:
-
Se você estiver usando uma das estruturas que a SageMaker IA suporta para empacotar artefatos de modelo (PyTorch ou XGBoost), então, para Artifacts, você pode escolher a opção Carregar artefatos. Com essa opção, você pode simplesmente especificar seus artefatos de modelo bruto, qualquer código de inferência personalizado que você tenha e seu arquivo requirements.txt, e a SageMaker IA cuida do empacotamento do arquivo para você. Faça o seguinte:
-
Em Artefatos, selecione Carregar artefatos para continuar fornecendo os arquivos. Caso contrário, se você já tiver um arquivo
tar.gzque contém os arquivos de modelo, o código de inferência e o arquivorequirements.txt, selecione Inserir URI do S3 para artefatos pré-empacotados. -
Se você optar por fazer o upload de seus artefatos, então, para o bucket S3, insira o caminho do Amazon S3 até um bucket onde você SageMaker gostaria que a IA armazenasse seus artefatos depois de empacotá-los para você. Depois, execute as seguintes etapas:
-
Em Carregar artefatos do modelo, carregue os arquivos de modelo.
-
Para Código de inferência, selecione Usar código de inferência padrão se quiser usar o código padrão que a SageMaker IA fornece para servir inferência. Caso contrário, selecione Carregar código de inferência personalizado para usar um código de inferência próprio.
-
Em Carregar requirements.txt, carregue um arquivo de texto que liste todas as dependências que você deseja instalar no runtime.
-
-
Se você não estiver usando uma estrutura compatível com SageMaker IA para empacotar artefatos do modelo, o Studio mostra a opção de artefatos pré-empacotados e você deve fornecer todos os seus artefatos já empacotados como um arquivo.
tar.gzFaça o seguinte:-
Em Artefatos pré-empacotados, selecione Inserir URI do S3 para artefatos de modelo pré-empacotados se você já tiver carregado o arquivo
tar.gzpara o Amazon S3. Selecione Carregar artefatos de modelo pré-empacotados se quiser carregar seu arquivo diretamente para a IA. SageMaker -
Se você selecionou Inserir URI do S3 para artefatos de modelo pré-empacotados, insira o caminho do Amazon S3 até o arquivo para o URI do S3. Caso contrário, selecione e carregue o arquivo a partir da máquina local.
-
A próxima seção é Segurança, que é semelhante à seguinte captura de tela:
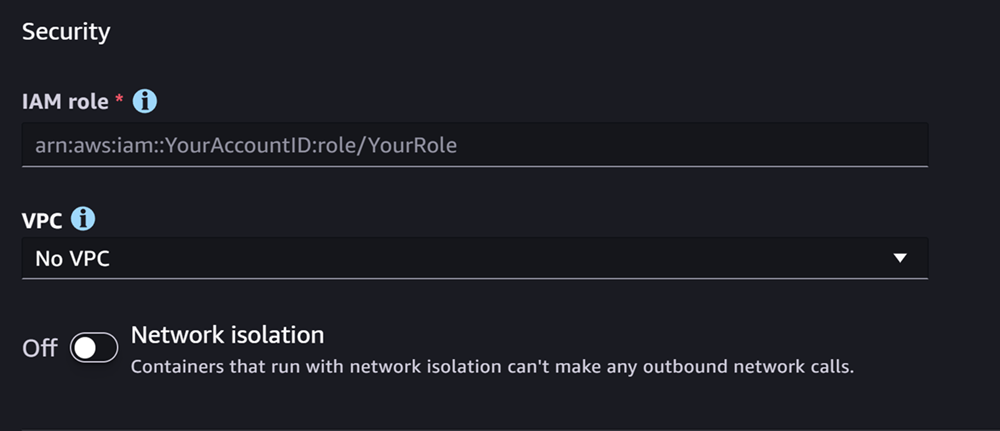
Na seção Segurança, faça o seguinte:
-
Em Perfil do IAM, insira o ARN para um perfil do IAM.
-
(Opcional) Em Nuvem privada virtual (VPC), você pode selecionar uma Amazon VPC para armazenar a configuração e os artefatos do modelo.
-
(Opcional) Ative o botão Isolamento de rede se quiser restringir o acesso do container à internet.
Por fim, você pode preencher opcionalmente a seção Opções avançadas, que se parece com a seguinte captura de tela:

(Opcional) Na seção Opções avançadas, faça o seguinte:
-
Ative a opção Recomendações de instância personalizada se quiser executar um trabalho do Amazon SageMaker Inference Recommender em seu modelo após sua criação. O Inference Recommender é um recurso que fornece os tipos de instância recomendados para otimizar o desempenho e o custo da inferência. Você pode ver essas recomendações de instância ao se preparar para implantar o modelo.
-
Em Adicionar variáveis de ambiente, insira variáveis de ambiente para o contêiner como pares de chave-valor.
-
Em Tags, insira todas as tags como pares de chave-valor.
-
Depois de concluir a configuração do modelo e do contêiner, escolha Criar modelo implantável.
Agora você deve ter um modelo no SageMaker Studio pronto para implantação.
Implantar o modelo
Por fim, você implanta o modelo que configurou na etapa anterior em um endpoint HTTPS. Você pode implantar um único modelo ou vários modelos no endpoint.
Compatibilidade de modelo e endpoint
Antes de implantar um modelo em um endpoint, o modelo e o endpoint devem ser compatíveis e ter os mesmos valores para as seguintes configurações:
-
O perfil do IAM
-
A Amazon VPC, incluindo suas sub-redes e grupos de segurança
-
O isolamento da rede (habilitado ou desabilitado)
O Studio impede que você implante modelos em endpoints incompatíveis das seguintes maneiras:
-
Se você tentar implantar um modelo em um novo endpoint, a SageMaker IA configura o endpoint com configurações iniciais compatíveis. Se você quebrar a compatibilidade ao alterar essas configurações, o Studio mostrará um alerta e impedirá a implantação.
-
Se você tentar implantar em um endpoint existente e ele for incompatível, o Studio mostrará um alerta e impedirá a implantação.
-
Se você tentar adicionar vários modelos a uma implantação, o Studio impede a implantação de modelos incompatíveis entre si.
Quando o Studio mostra o alerta sobre a incompatibilidade do modelo e do endpoint, você pode escolher Visualizar detalhes no alerta para ver quais configurações são incompatíveis.
Uma forma de implantar um modelo é fazer o seguinte no Studio:
-
Abra o aplicativo SageMaker Studio.
-
No painel de navegação à esquerda, selecione Modelos.
-
Na página Modelos, selecione um ou mais modelos na lista de modelos de SageMaker IA.
-
Escolha Implantar.
-
Em Nome do endpoint, abra o menu suspenso. Você pode selecionar um endpoint existente ou criar um endpoint novo no qual você implanta o modelo.
-
Em Tipo de instância, selecione o tipo de instância que você deseja usar para o endpoint. Se você executou anteriormente um trabalho do Inference Recommender para o modelo, os tipos de instância recomendados aparecerão na lista sob o título Recomendado. Caso contrário, você verá algumas Instâncias em potencial que podem ser adequadas para o modelo.
Compatibilidade do tipo de instância para JumpStart
Se você estiver implantando um JumpStart modelo, o Studio mostra apenas os tipos de instância compatíveis com o modelo.
-
Em Contagem inicial de instâncias, insira o número inicial de instâncias que você gostaria de provisionar para o endpoint.
-
Em Contagem máxima de instâncias, especifique o número máximo de instâncias que o endpoint pode provisionar ao aumentar a escala verticalmente para acomodar um aumento no tráfego.
-
Se o modelo que você está implantando for um dos mais usados no hub JumpStart LLMs de modelos, a opção Configurações alternativas aparecerá após os campos tipo de instância e contagem de instâncias.
Para os mais populares JumpStart LLMs, AWS tem tipos de instância pré-comparados para otimizar em termos de custo ou desempenho. Esses dados podem ajudar você a decidir qual tipo de instância usar para implantar o LLM. Escolha Configurações alternativas para abrir uma caixa de diálogo que contém os dados pré-comparados. O painel é semelhante à seguinte captura de tela:

Na caixa Configurações alternativas, faça o seguinte:
-
Selecione um tipo de instância. Você pode escolher Custo por hora ou Melhor desempenho para ver os tipos de instância que otimizam o custo ou o desempenho para o modelo especificado. Você também pode escolher Outras instâncias compatíveis para ver uma lista de outros tipos de instância compatíveis com o JumpStart modelo. Observe que selecionar um tipo de instância aqui substitui qualquer seleção de instância anterior especificada na Etapa 6.
-
(Opcional) Ative a opção Personalizar a configuração selecionada para especificar Número máximo (o número máximo de tokens que você deseja permitir, que é a soma dos tokens de entrada e a saída gerada pelo modelo), Tamanho máximo do token de entrada (o número máximo de tokens que você deseja permitir para a entrada de cada solicitação) e Máximo de solicitações simultâneas (o número máximo de solicitações que o modelo pode processar por vez).
-
Escolha Selecionar para confirmar o tipo de instância e as configurações.
-
-
O campo Modelo já deve estar preenchido com o nome do dos modelos que você está implantando. Você pode escolher Adicionar modelo para adicionar mais modelos à implantação. Para cada modelo adicionado, preencha os seguintes campos:
-
Em Número de núcleos de CPU, insira os núcleos de CPU que você gostaria de dedicar ao uso do modelo.
-
Em Número mínimo de cópias, insira o número mínimo de cópias do modelo que você deseja hospedar no endpoint a qualquer momento.
-
Em Memória mínima da CPU (MB), insira a quantidade mínima de memória (em MB) exigida pelo modelo.
-
Em Memória máxima da CPU (MB), insira a quantidade máxima de memória (em MB) que você gostaria de permitir que o modelo usasse.
-
-
(Opcional) Em Opções avançadas, faça o seguinte:
-
Para a função IAM, use a função de execução padrão do SageMaker AI IAM ou especifique sua própria função que tenha as permissões de que você precisa. Observe que esse perfil do IAM deve ser o mesmo que você especificou ao criar o modelo implantável.
-
Para a Nuvem Privada Virtual (VPC), você pode especificar uma VPC na qual deseja hospedar o endpoint.
-
Em Chave KMS de criptografia, selecione uma AWS KMS chave para criptografar dados no volume de armazenamento anexado à instância de computação de ML que hospeda o endpoint.
-
Ative o botão Habilitar isolamento de rede para restringir o acesso do contêiner à internet.
-
Em Configuração de tempo limite, insira valores para os campos Tempo limite para baixar dados do modelo (segundos) e Tempo limite de verificação de integridade de inicialização do contêiner (segundos). Esses valores determinam a quantidade máxima de tempo que a SageMaker IA permite para baixar o modelo para o contêiner e inicializá-lo, respectivamente.
-
Em Tags, insira todas as tags como pares de chave-valor.
nota
SageMaker A IA configura a função do IAM, a VPC e as configurações de isolamento de rede com valores iniciais compatíveis com o modelo que você está implantando. Se você quebrar a compatibilidade ao alterar essas configurações, o Studio mostrará um alerta e impedirá a implantação.
-
Após configurar as opções, a página deve ter a aparência da seguinte captura de tela:

Depois de configurar sua implantação, escolha Implantar para criar o endpoint e implantar o modelo.
Implante modelos com o Python SDKs
Usando o SDK do SageMaker Python, você pode criar seu modelo de duas maneiras. A primeira é criar um objeto de modelo a partir da classe Model ou ModelBuilder. Se usar a classe Model para criar seu objeto Model, você precisará especificar o pacote do modelo ou o código de inferência (dependendo do servidor do modelo), scripts para lidar com a serialização e desserialização de dados entre o cliente e o servidor e quaisquer dependências a serem carregadas no Amazon S3 para consumo. A segunda maneira de criar seu modelo é usar o ModelBuilder para o qual você fornece artefatos de modelo ou código de inferência. O ModelBuilder captura automaticamente as dependências, infere as funções de serialização e desserialização necessárias e empacota as dependências para criar o objeto Model. Para obter mais informações sobre o ModelBuilder, consulte Crie um modelo na Amazon SageMaker AI com ModelBuilder.
A seção a seguir descreve os dois métodos para criar o modelo e implantar o objeto de modelo.
Configurar
Os exemplos a seguir preparam o processo de implantação do modelo. Eles importam as bibliotecas necessárias e definem a URL do S3 que localiza os artefatos do modelo.
exemplo URL de artefato de modelo
O código a seguir cria um exemplo de URL do Amazon S3. A URL localiza os artefatos de modelo para um modelo pré-treinado em um bucket do Amazon S3.
# Create a variable w/ the model S3 URL # The name of your S3 bucket: s3_bucket = "amzn-s3-demo-bucket" # The directory within your S3 bucket your model is stored in: bucket_prefix = "sagemaker/model/path" # The file name of your model artifact: model_filename = "my-model-artifact.tar.gz" # Relative S3 path: model_s3_key = f"{bucket_prefix}/"+model_filename # Combine bucket name, model file name, and relate S3 path to create S3 model URL: model_url = f"s3://{s3_bucket}/{model_s3_key}"
A URL completa do Amazon S3 é armazenada na variável model_url, que é usada nos exemplos a seguir.
Visão geral
Há várias maneiras de implantar modelos com o SDK do SageMaker Python ou o SDK for Python (Boto3). As seções a seguir resumem as etapas que você conclui para várias abordagens possíveis. Essas etapas são demonstradas pelos exemplos a seguir.
Configurar
Os exemplos a seguir configuram os recursos necessários para implantar um modelo em um endpoint.
Implantar
Os exemplos a seguir implantam um modelo em um endpoint.
Implemente modelos com o AWS CLI
Você pode implantar um modelo em um endpoint usando o. AWS CLI
Visão geral
Ao implantar um modelo com o AWS CLI, você pode implantá-lo com ou sem o uso de um componente de inferência. As seguintes seções resumem os comandos que você executa para ambas as abordagens: Esses comandos são demonstrados pelos exemplos a seguir.
Configurar
Os exemplos a seguir configuram os recursos necessários para implantar um modelo em um endpoint.
Implantar
Os exemplos a seguir implantam um modelo em um endpoint.
