Soluções de streaming de dados: exemplos
Cenário 1: oferta de Internet com base na localização
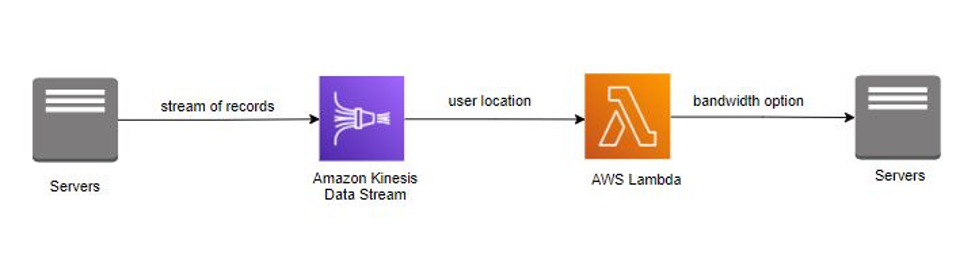
A empresa InternetProvider fornece serviços de Internet com uma variedade de opções de largura de banda para usuários em todo o mundo. Quando um usuário se cadastra na Internet, a empresa InternetProvider fornece a ele diferentes opções de largura de banda com base na localização geográfica. Devido a esses requisitos, a empresa InternetProvider implementou o Amazon Kinesis Data Streams para consumir detalhes e localização do usuário. Os detalhes do usuário e a localização são enriquecidos com diferentes opções de largura de banda antes da publicação de volta na aplicação. O AWS Lambda
Processar fluxos de dados com o AWS Lambda
Amazon Kinesis Data Streams
O Amazon Kinesis Data Streams
Ao implementar uma solução com o Kinesis Data Streams, você cria aplicações de processamento de dados personalizadas conhecidas como aplicações do Kinesis Data Streams. Uma aplicação típica do Kinesis Data Streams lê dados de um fluxo do Kinesis como registros de dados.
Os dados colocados no Kinesis Data Streams têm a garantia de ser altamente disponíveis e elásticos, além de estarem disponíveis em milissegundos. É possível adicionar continuamente vários tipos de dados como clickstreams, logs de aplicações e mídia social a um fluxo do Kinesis de centenas de milhares de fontes. Em segundos, os dados estarão disponíveis para suas aplicações do Kinesis
O Amazon Kinesis Data Streams é um serviço de dados de streaming totalmente gerenciado. Ele gerencia infraestrutura, armazenamento, redes e configuração necessários para transmitir seus dados no nível da sua taxa de transferência de dados.
Enviar dados ao Amazon Kinesis Data Streams
Há várias maneiras de enviar dados ao Kinesis Data Streams, oferecendo flexibilidade nos designs de suas soluções.
-
Você pode escrever código usando um dos AWS SDKs
que são compatíveis com várias linguagens populares. -
É possível usar o Amazon Kinesis Agent, uma ferramenta para enviar dados ao Kinesis Data Streams.
A Amazon Kinesis Producer Library (KPL) simplifica o desenvolvimento de aplicações do produtor, permitindo que os desenvolvedores obtenham alta taxa de transferência de gravação para um ou mais Kinesis Data Streams.
A KPL é uma biblioteca fácil de usar e altamente configurável que você instala em seus hosts. Ela atua como um intermediário entre o código da sua aplicação de produtor e as ações da API do Kinesis Streams. Para obter mais informações sobre a KPL e sua capacidade de produzir eventos de forma síncrona e assíncrona com exemplos de código, consulte Gravar no Kinesis Data Streams usando a KPL.
Existem duas operações diferentes na API do Kinesis Data Streams que adicionam dados a um fluxo: PutRecords e PutRecord. A operação PutRecords envia vários registros ao seu fluxo por solicitação HTTP, enquanto PutRecord envia um registro por solicitação HTTP. Para obter maior taxa de transferência para a maioria das aplicações, use PutRecords.
Para obter mais informações sobre essas APIs, consulte Adicionar dados a um fluxo. Os detalhes de cada operação de API podem ser encontrados na Referência de API do Amazon Kinesis Data Streams.
Processar dados no Amazon Kinesis Data Streams
Para ler e processar dados dos fluxos do Kinesis, você precisa criar uma aplicação de consumidor. Existem várias maneiras de criar consumidores para o Kinesis Data Streams. Algumas dessas abordagens incluem o uso do Amazon Kinesis Data Analytics
As aplicações de consumidor para o Kinesis Data Streams podem ser desenvolvidas com o uso da KCL, que ajuda você a consumir e processar dados do Kinesis Data Streams. A KCL se encarrega de muitas das tarefas complexas associadas à computação distribuída, como balanceamento de carga em várias instâncias, resposta a falhas de instância, definição de pontos de verificação de registros processados e reação à reestilhaçamento. A KCL permite que você se concentre em escrever a lógica de processamento de registro. Para obter mais informações sobre como criar sua própria aplicação de KCL, consulte Usar a biblioteca de cliente do Kinesis.
Você pode assinar funções do Lambda para ler automaticamente lotes de registros do fluxo do Kinesis e processá-los se os registros forem detectados no fluxo. O AWS Lambda pesquisa periodicamente o fluxo (uma vez por segundo) em busca de novos registros e, ao detectas novos registros, invoca a função do Lambda transmitindo os novos registros como parâmetros. A função do Lambda só é executada quando novos registros são detectados. É possível mapear uma função do Lambda para um consumidor de taxa de transferência compartilhada (iterador padrão)
Você pode criar um consumidor que use um recurso chamado distribuição avançada quando você precisa de uma taxa de transferência dedicada que não rivalize com outros consumidores que estejam recebendo dados do fluxo. Esse recurso permite que consumidores recebam registros de um fluxo com taxa de transferência de até 2 MB de dados por segundo por estilhaço.
Na maioria dos casos, é necessário usar o Kinesis Data Analytics, a KCL, o AWS Glue ou o AWS Lambda para processar dados de um fluxo. No entanto, se preferir, você pode criar uma aplicação de consumidor desde o início usando a API do Kinesis Data Streams. A API do Kinesis Data Streams fornece os métodos GetShardIterator e GetRecords para recuperar dados de um fluxo.
Nesse modelo de extração, seu código extrai dados diretamente dos estilhaços do fluxo. Para obter mais informações sobre como criar sua própria aplicação de consumidor usando a API, consulte Desenvolver consumidores personalizados com taxa de transferência compartilhada usando o AWS SDK for Java. Detalhes sobre a API podem ser encontrados na Referência de API do Amazon Kinesis Data Streams.
Processar fluxos de dados com AWS Lambda
O AWS Lambda
O AWS Lambda integra-se nativamente com o Amazon Kinesis Data Streams. As complexidades de pesquisa, ponto de verificação e tratamento de erros são abstraídas quando você usa essa integração nativa. Isso permite que o código de função do Lambda se concentre no processamento da lógica de negócios.
É possível mapear uma função do Lambda para um consumidor de taxa de transferência compartilhada (iterador padrão) ou para um consumidor de taxa de transferência dedicada com distribuição avançada. Com um iterador padrão, o Lambda sonda cada estilhaço no fluxo do Kinesis em busca de registros que usem o protocolo HTTP. Para minimizar a latência e maximizar a taxa de transferência de leitura, é possível criar um consumidor de fluxo de dados com distribuição avançada. Os consumidores de fluxo nessa arquitetura obtêm uma conexão dedicada a cada estilhaço sem competir com outras aplicações que estejam lendo no mesmo fluxo. O Amazon Kinesis Data Streams envia registros ao Lambda por HTTP/2.
Por padrão, o AWS Lambda invoca sua função assim que os registros estão disponíveis no fluxo. Para armazenar em buffer os registros para cenários de lote, você pode implementar uma janela de lote por até cinco minutos na fonte do evento. Se a sua função retornar um erro, o Lambda tentará executar novamente o lote até que o processamento seja bem-sucedido ou os dados expirem.
Resumo
A empresa InternetProvider utilizou o Amazon Kinesis Data Streams para transmitir detalhes e localização do usuário. O fluxo de registro foi consumido pelo AWS Lambda para enriquecer os dados com opções de largura de banda armazenadas na biblioteca da função. Após o enriquecimento, o AWS Lambda publicou as opções de largura de banda de volta para a aplicação. O Amazon Kinesis Data Streams e o AWS Lambda administraram o provisionamento e o gerenciamento de servidores, permitindo que a empresa InternetProvider se concentrasse mais no desenvolvimento de aplicações de negócios.
