Amazon Redshift will no longer support the creation of new Python UDFs starting Patch 198.
Existing Python UDFs will continue to function until June 30, 2026. For more information, see the
blog post
Materialized views in Amazon Redshift
This section describes how to create and use materialized views in Amazon Redshift. A materialized view is a database object that stores the results of a query, which can be used to improve performance and efficiency.
In a data warehouse environment, applications often must perform complex queries on large tables. An example is SELECT statements that perform multi-table joins and aggregations on tables that contain billions of rows. Processing these queries can be expensive, in terms of system resources and the time it takes to compute the results.
Materialized views in Amazon Redshift provide a way to address these issues. A materialized view contains a precomputed result set, based on an SQL query over one or more base tables. You can issue SELECT statements to query a materialized view, in the same way that you can query other tables or views in the database. Amazon Redshift returns the precomputed results from the materialized view, without having to access the base tables at all. From the user standpoint, the query results are returned much faster compared to when retrieving the same data from the base tables.
Materialized views are especially useful for speeding up queries that are predictable and repeated. Instead of performing resource-intensive queries against large tables (such as aggregates or multiple joins), applications can query a materialized view and retrieve a precomputed result set. For example, consider the scenario where a set of queries is used to populate dashboards, such as Amazon Quick. This use case is ideal for a materialized view, because the queries are predictable and repeated over and over again.
You can define a materialized view in terms of other materialized views. Use materialized views on materialized views to expand the capability of materialized views. In this approach, an existing materialized view plays the same role as a base table for the query to retrieve data.
This approach is especially useful for reusing precomputed joins for different aggregate or GROUP BY options. For example, take a materialized view that joins customer information (containing millions of rows) with item order detail information (containing billions of rows). This is an expensive query to compute on demand repeatedly. You can use different GROUP BY options for the materialized views created on top of this materialized view and join with other tables. Doing this saves compute time otherwise used to run the expensive underlying join every time. The STV_MV_DEPS table shows the dependencies of a materialized view on other materialized views.
When you create a materialized view, Amazon Redshift runs the user-specified SQL statement to
gather the data from the base table or tables and stores the result set. The following
illustration provides an overview of the materialized view tickets_mv that an
SQL query defines by using two base tables, events and
sales.
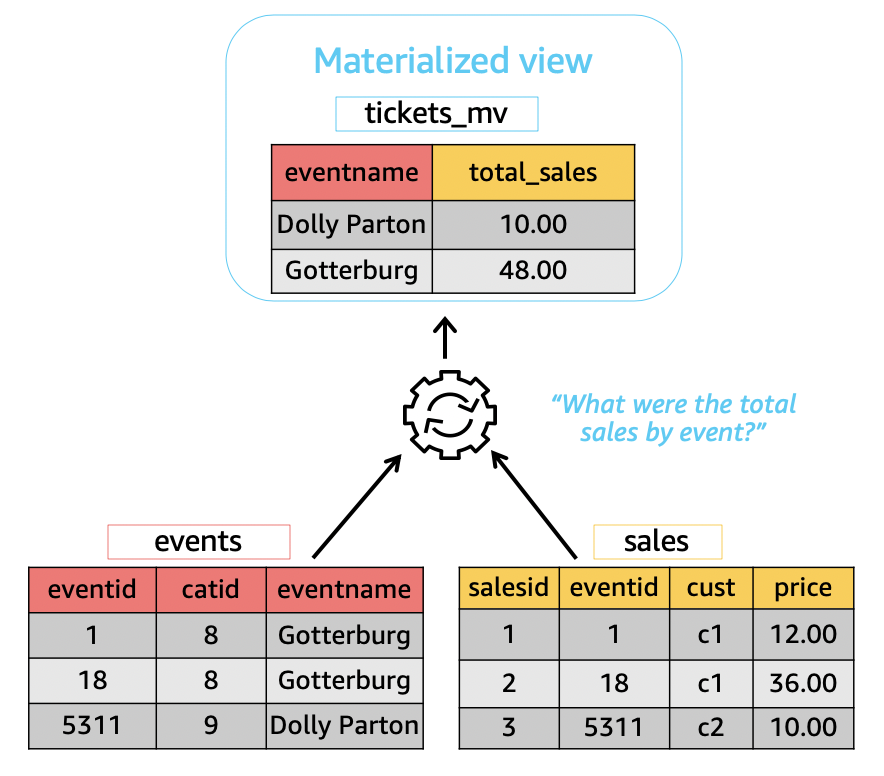
You can then use these materialized views in queries to speed them up. In addition, Amazon Redshift can automatically rewrite these queries to use materialized views, even when the query doesn't explicitly reference a materialized view. Automatic rewrite of queries is especially powerful in enhancing performance when you can't change your queries to use materialized views.
To update the data in the materialized view, you can use the REFRESH MATERIALIZED VIEW statement at any time to manually refresh materialized views. Amazon Redshift identifies changes that have taken place in the base table or tables, and then applies those changes to the materialized view. Because automatic rewriting of queries requires materialized views to be up to date, as a materialized view owner, make sure to refresh materialized views whenever a base table changes.
Amazon Redshift provides a few ways to keep materialized views up to date for automatic rewriting. You can configure materialized views with the automatic refresh option to refresh materialized views when base tables of materialized views are updated. This autorefresh operation runs at a time when cluster resources are available to minimize disruptions to other workloads. Because the scheduling of autorefresh is workload-dependent, you can have more control over when Amazon Redshift refreshes your materialized views. You can schedule a materialized view refresh job by using Amazon Redshift scheduler API and console integration. For more information about query scheduling, see Scheduling a query on the Amazon Redshift console.
Doing this is especially useful when there is a service level agreement (SLA) requirement for up-to-date data from a materialized view. You can also manually refresh any materialized views that you can autorefresh. For information on how to create materialized views, see CREATE MATERIALIZED VIEW.
You can issue SELECT statements to query a materialized view. For information on how to query materialized views, see Materialized view queries. The result set eventually becomes stale when data is inserted, updated, and deleted in the base tables. You can refresh the materialized view at any time to update it with the latest changes from the base tables. For information on how to refresh materialized views, see REFRESH MATERIALIZED VIEW.
For details about SQL commands used to create and manage materialized views, see the following command topics:
For information about system tables and views to monitor materialized views, see the following topics:
