Create an image classification job (Single Label)
Use an Amazon SageMaker Ground Truth image classification labeling task when you need workers to classify
images using predefined labels that you specify. Workers are shown images and are asked to
choose one label for each image. You can create an image classification labeling job using
the Ground Truth section of the Amazon SageMaker AI console or the CreateLabelingJob operation.
Important
For this task type, if you create your own manifest file, use
"source-ref" to identify the location of each image file in Amazon S3 that
you want labeled. For more information, see Input data.
Create an Image Classification Labeling Job (Console)
You can follow the instructions Create a Labeling Job (Console) to learn how to create a image classification labeling job in the SageMaker AI console. In Step 10, choose Image from the Task category drop down menu, and choose Image Classification (Single Label) as the task type.
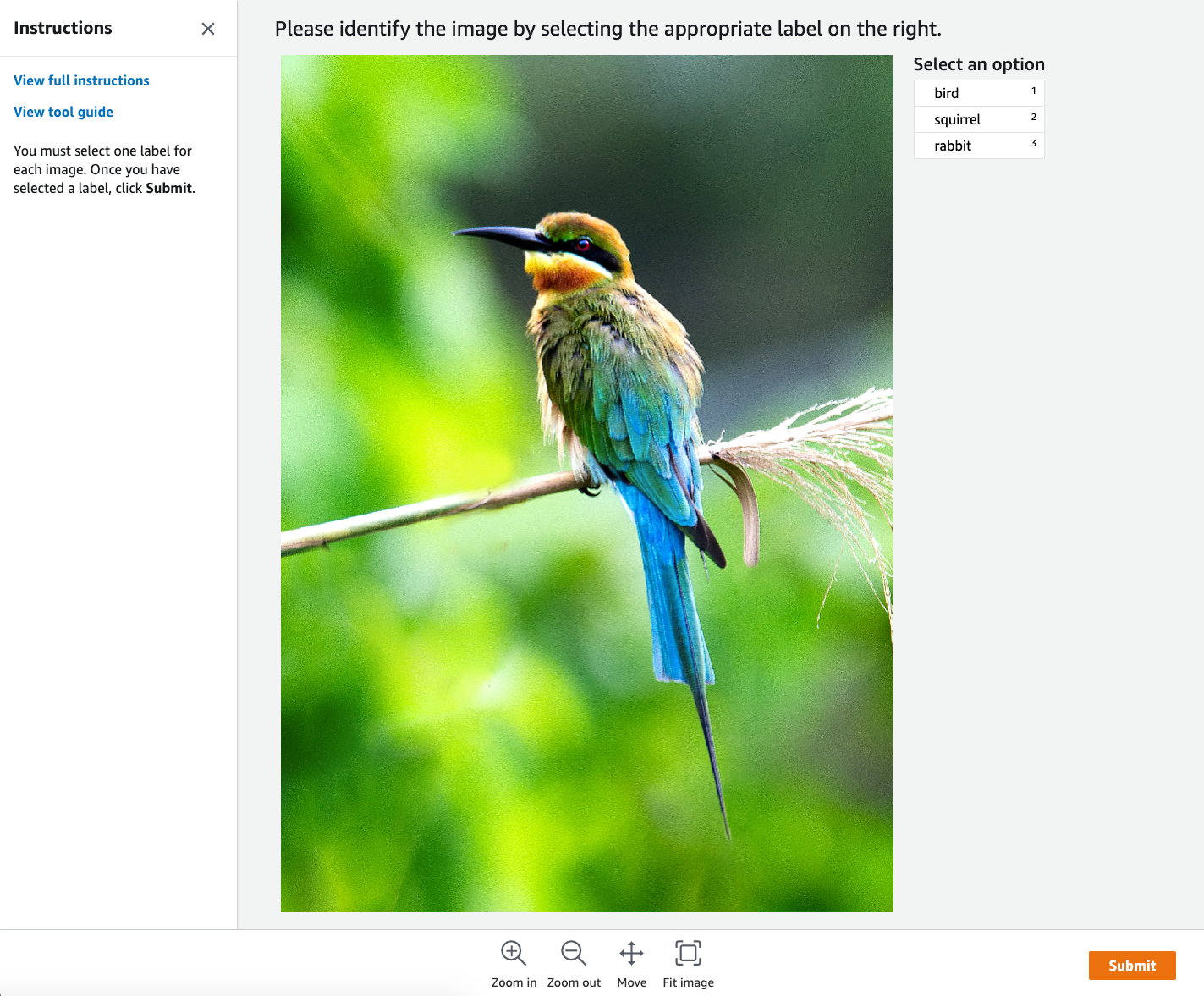
Ground Truth provides a worker UI similar to the following for labeling tasks. When you create the labeling job with the console, you specify instructions to help workers complete the job and labels that workers can choose from.
Create an Image Classification Labeling Job (API)
To create an image classification labeling job, use the SageMaker API operation
CreateLabelingJob. This API defines this operation for all AWS SDKs.
To see a list of language-specific SDKs supported for this operation, review the
See Also section of CreateLabelingJob.
Follow the instructions on Create a Labeling Job (API) and do the following while you configure your request:
-
Pre-annotation Lambda functions for this task type end with
PRE-ImageMultiClass. To find the pre-annotation Lambda ARN for your Region, see PreHumanTaskLambdaArn . -
Annotation-consolidation Lambda functions for this task type end with
ACS-ImageMultiClass. To find the annotation-consolidation Lambda ARN for your Region, see AnnotationConsolidationLambdaArn.
The following is an example of an AWS Python SDK (Boto3) request
response = client.create_labeling_job( LabelingJobName='example-image-classification-labeling-job', LabelAttributeName='label', InputConfig={ 'DataSource': { 'S3DataSource': { 'ManifestS3Uri':'s3://bucket/path/manifest-with-input-data.json'} }, 'DataAttributes': { 'ContentClassifiers': ['FreeOfPersonallyIdentifiableInformation'|'FreeOfAdultContent', ] } }, OutputConfig={ 'S3OutputPath':'s3://bucket/path/file-to-store-output-data', 'KmsKeyId':'string'}, RoleArn='arn:aws:iam::*:role/*, LabelCategoryConfigS3Uri='s3://bucket/path/label-categories.json', StoppingConditions={ 'MaxHumanLabeledObjectCount':123, 'MaxPercentageOfInputDatasetLabeled':123}, HumanTaskConfig={ 'WorkteamArn':'arn:aws:sagemaker:region:*:workteam/private-crowd/*', 'UiConfig': { 'UiTemplateS3Uri':'s3://bucket/path/worker-task-template.html'}, 'PreHumanTaskLambdaArn': 'arn:aws:lambda:us-east-1:432418664414:function:PRE-ImageMultiClass, 'TaskKeywords': [Image classification', ], 'TaskTitle':Image classification task', 'TaskDescription':'Carefully inspect the image and classify it by selecting one label from the categories provided.', 'NumberOfHumanWorkersPerDataObject':123, 'TaskTimeLimitInSeconds':123, 'TaskAvailabilityLifetimeInSeconds':123, 'MaxConcurrentTaskCount':123, 'AnnotationConsolidationConfig': { 'AnnotationConsolidationLambdaArn': 'arn:aws:lambda:us-east-1:432418664414:function:ACS-ImageMultiClass' }, Tags=[ { 'Key':'string', 'Value':'string'}, ] )
Provide a Template for Image Classification Labeling Jobs
If you create a labeling job using the API, you must supply a worker task template
in UiTemplateS3Uri. Copy and modify the following template. Only modify
the short-instructions, full-instructions, and header.
Upload this template to S3, and provide the S3 URI for this file in
UiTemplateS3Uri.
<script src="https://assets.crowd.aws/crowd-html-elements.js"></script> <crowd-form> <crowd-image-classifier name="crowd-image-classifier" src="{{ task.input.taskObject | grant_read_access }}" header="please classify" categories="{{ task.input.labels | to_json | escape }}" > <full-instructions header="Image classification instructions"> <ol><li><strong>Read</strong> the task carefully and inspect the image.</li> <li><strong>Read</strong> the options and review the examples provided to understand more about the labels.</li> <li><strong>Choose</strong> the appropriate label that best suits the image.</li></ol> </full-instructions> <short-instructions> <h3><span style="color: rgb(0, 138, 0);">Good example</span></h3> <p>Enter description to explain the correct label to the workers</p> <h3><span style="color: rgb(230, 0, 0);">Bad example</span></h3><p>Enter description of an incorrect label</p> </short-instructions> </crowd-image-classifier> </crowd-form>
Image Classification Output Data
Once you have created an image classification labeling job, your output data will be
located in the Amazon S3 bucket specified in the S3OutputPath parameter when
using the API or in the Output dataset location field of the
Job overview section of the console.
To learn more about the output manifest file generated by Ground Truth and the file structure the Ground Truth uses to store your output data, see Labeling job output data.
To see an example of an output manifest file from an image classification labeling job, see Classification job output.
