This whitepaper is for historical reference only. Some content might be outdated and some links might not be available.
Data plane-controlled evacuation
There are several solutions that you can implement to perform an Availability Zone evacuation using data plane-only actions. This section will describe three of them and the use cases where you may want to pick one over the other.
When using any of these solutions, you need to ensure you have sufficient capacity in the remaining Availability Zones to handle the load of the Availability Zone you are shifting away from. The most resilient was to do this is by having the required capacity pre-provisioned in each Availability Zone. If you are using three Availability Zones, you would have 50% of the required capacity to handle your peak load deployed in each one, so that the loss of a single Availability Zone would still leave you 100% of your required capacity without having to rely on a control plane to provision more.
Additionally, if you are using EC2 Auto Scaling, ensure your Auto Scaling group (ASG) doesn’t scale in during the shift, so that when the shift ends, you still have sufficient capacity in the group to handle your customer traffic. You can do this by ensuring that your ASG’s minimum desired capacity can handle your current customer load. You can also help ensure that your ASG doesn’t inadvertently scale in by using averages in your metrics as opposed to outlier percentile metrics like P90 or P99.
During a shift, the resources no longer serving traffic should have very low utilization, but the other resources will increase their utilization with the new traffic, keeping the average fairly consistent, which would prevent a scale-in action. Finally, you can also use target group health settings for ALB and NLB to specify DNS failover with either a percentage or count of healthy hosts. This prevents traffic from being routed to an Availability Zone that does not have enough healthy hosts.
Zonal Shift in Route 53 Application Recovery Controller (ARC)
The first solution for Availability Zone evacuation uses zonal shift in Route 53 ARC. This solution can be used for request/response workloads that use an NLB or ALB as the ingress point for customer traffic.
When you detect that an Availability Zone has become impaired, you can initiate a zonal
shift with Route 53 ARC. Once this operation completes and existing cached DNS responses
expire, all new requests are only routed to resources in the remaining Availability Zones.
The following figure shows how zonal shift works. In the following figure we have a Route 53
alias record for www.example.com that points to
my-example-nlb-4e2d1f8bb2751e6a.elb.us-east-1.amazonaws.com. The zonal shift
is performed for Availability Zone 3.

Zonal shift
In the example, if the primary database instance is not in Availability Zone 3, then performing the zonal shift is the only action required to achieve the first outcome for evacuation, preventing work from being processed in the impacted Availability Zone. If the primary node was in Availability Zone 3, then you could perform a manually initiated failover (which does rely on the Amazon RDS control plane) in coordination with the zonal shift, if Amazon RDS did not already failover automatically. This will be true for all of the data plane-controlled solutions in this section.
You should initiate the zonal shift using CLI commands or the API in order to minimize dependencies required to start the evacuation. The simpler the evacuation process, the more reliable it will be. The specific commands can be stored in a local runbook that on-call engineers can easily access. Zonal shift is the most preferred and simplest solution for evacuating an Availability Zone.
Route 53 ARC
The second solution uses the capabilities of Route 53 ARC to manually specify the health of specific DNS records. This solution has the benefit of using the highly available Route 53 ARC cluster data plane, making it resilient to the impairment of up to two different AWS Regions. It has the tradeoff of additional cost and it requires some additional configuration of DNS records. To implement this pattern, you need to create alias records for the Availability Zone-specific DNS names provided by the load balancer (ALB or NLB). This is shown in the following table.
Table 3: Route 53 alias records configured for the load balancer’s zonal DNS names
|
Routing Policy: weighted
Name:
Type:
Value:
Weight: Evaluate Target Health: true |
Routing Policy: weighted
Name:
Type:
Value:
Weight:
Evaluate Target Health:
|
Routing Policy: weighted
Name:
Type:
Value:
Weight:
Evaluate Target Health:
|
For each of these DNS records, you would configure a Route 53 health check that is
associated with a Route 53 ARC routing control. When you want to
initiate an Availability Zone evacuation, set the routing control state to Off.
AWS recommends you do this using the CLI or API in order to minimize the dependencies
required to start the Availability Zone evacuation. As a best practice, you
should keep a local copy of the Route 53 ARC cluster endpoints so you don’t need to retrieve
those from the ARC control plane when you need to perform an evacuation.
To minimize cost when using this approach, you can create a single Route 53 ARC cluster and
health checks in a single AWS account and share the
health checks with other AWS accountsuse1-az1) instead of the Availability Zone name (for example,
us-east-1a) for your routing controls. Because AWS maps the physical
Availability Zone randomly to the Availability Zone names for each AWS account, using the
AZ-ID provides a consistent way to refer to the same physical locations. When you initiate
an Availability Zone evacuation, say for use1-az2, the Route 53 record sets in
each AWS account should ensure they use the AZ-ID mapping to configure the right health
check for each NLB records.
For example, let’s say we have a Route 53 health check associated with a Route 53 ARC routing
control for use1-az2, with an ID of
0385ed2d-d65c-4f63-a19b-2412a31ef431. If in a different AWS account that
wants to use this health check, us-east-1c was mapped to use1-az2,
you would need to use the use1-az2 health check for the record
us-east-1c.load-balancer-name.elb.us-east-1.amazonaws.com. You would use the
health check ID 0385ed2d-d65c-4f63-a19b-2412a31ef431 with that resource record
set.
Using a self-managed HTTP endpoint
You can also implement this solution by managing your own HTTP endpoint that indicates the status of a particular Availability Zone. It allows you to manually specify when an Availability Zone is unhealthy based on the response from the HTTP endpoint. This solution costs less than using Route 53 ARC, but is more expensive than zonal shift and requires managing additional infrastructure. It has the benefit of being much more flexible for different scenarios.
The pattern can be used with NLB or ALB architectures and Route 53 health checks. It can also be used in non-load balanced architectures, like service discovery or queue processing systems where worker nodes perform their own health checks. In those scenarios, the hosts can use a background thread where they periodically make a request to the HTTP endpoint with their AZ-ID (refer to Appendix A – Getting the Availability Zone ID for details on how find this) and receive back a response about the health of the Availability Zone.
If the Availability Zone has been declared to be unhealthy, they have multiple options
on how to respond. They may choose to fail an external health check from sources such as
ELB, Route 53, or custom health checks in service discovery architectures so that they appear
unhealthy to those services. They can also immediately respond with an error should they
receive a request, allowing the client to backoff and retry. In event-driven architectures,
nodes can intentionally fail to process work, like intentionally returning an SQS message to
the queue. In work router architectures where a central service schedules work on specific
hosts you can also use this pattern. The router can check the status of an Availability Zone
before selecting a worker, endpoint, or cell. In service discovery architectures that use
AWS Cloud Map, you can discover endpoints by providing a filter in your request
The following figure shows how this approach can be used for multiple types of workloads.
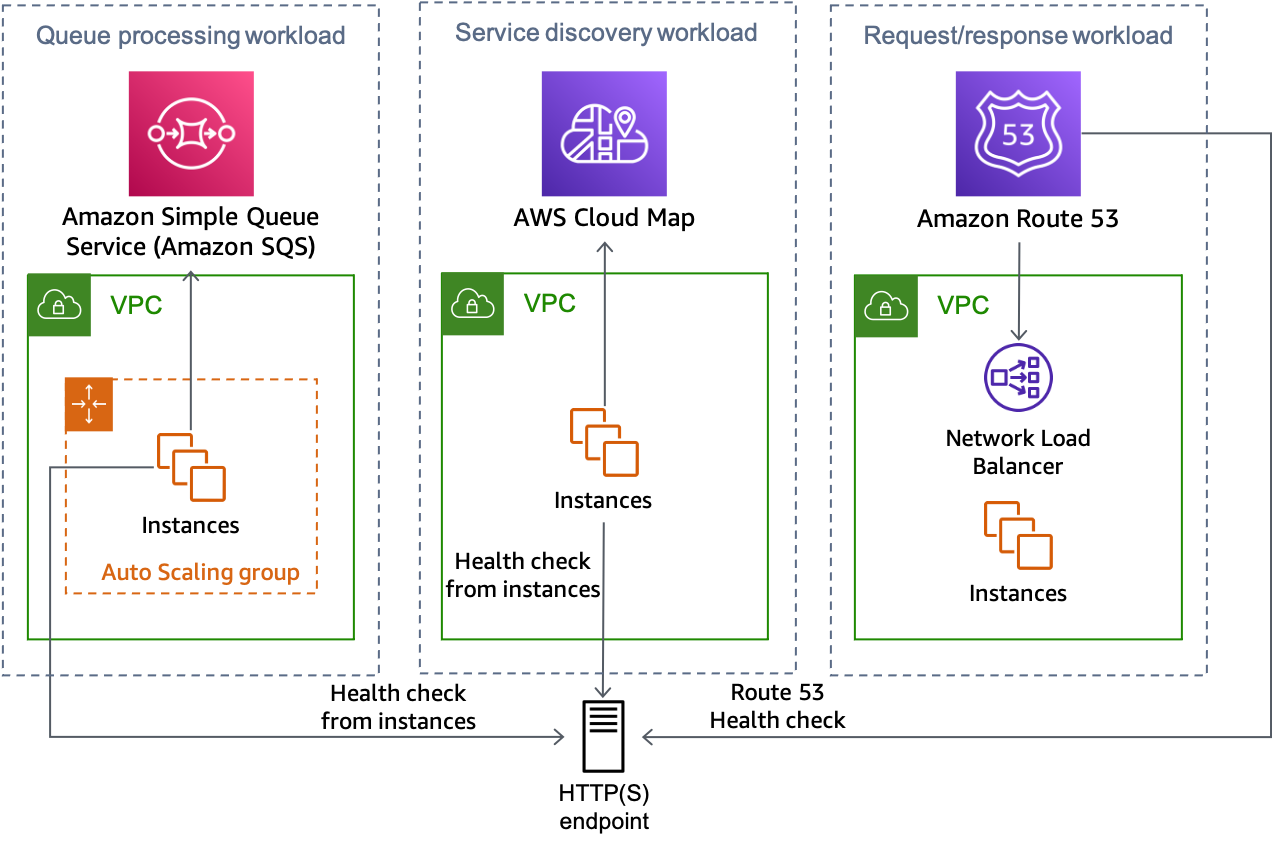
Multiple workload types can all use the HTTP endpoint solution
There are multiple ways to implement the HTTP endpoint approach, two of them are outlined next.
Using Amazon S3
This pattern was originally presented in this blog post
In this scenario you would create Route 53 DNS resource record sets for each zonal DNS record just like the Route 53 ARC scenario above as well as associated health checks. However, for this implementation, instead of associating the health checks with Route 53 ARC routing controls, they are configured to use an HTTP endpoint and are inverted to safeguard against an impairment in Amazon S3 accidentally triggering an evacuation. The health check is considered healthy when the object is absent and unhealthy when the object is present. This setup is shown in the following table.
Table 4: DNS record configuration for using Route 53 health checks per Availability Zone
|
Health check type: monitor an endpoint
Protocol:
ID:
URL:
|
Health check type: monitor an endpoint
Protocol:
ID:
URL: |
Health check type: monitor an endpoint
Protocol:
ID:
URL:
|
← | Health checks |
| ↑ | ↑ | ↑ | ||
|
Routing Policy: weighted
Name:
Type:
Value:
Weight:
Evaluate Target Health: |
Routing Policy: weighted
Name:
Type:
Value:
Weight:
Evaluate Target Health:
|
Routing Policy: weighted
Name:
Type:
Value:
Weight:
Evaluate Target Health:
|
← | Top level, evenly weighted alias A records point to NLB AZ specific endpoints |
Let’s assume that the Availability Zone us-east-1a is mapped to
use1-az3 in the account where we have a workload where we want to perform
an Availability Zone evacuation. For the resource record set created for
us-east-1a.load-balancer-name.elb.us-east-1.amazonaws.com would associate a
health check that tests the URL
https://.
When you want to initiate an Availability Zone evacuation for bucket-name.s3.us-east-1.amazonaws.com/use1-az3.txtuse1-az3,
upload a file named use1-az3.txt to the bucket using the CLI or API. The file
doesn’t need to contain any content, but it does need to be public so that the Route 53
health check can access it. The following figure demonstrates this implementation being
used to evacuate use1-az3.
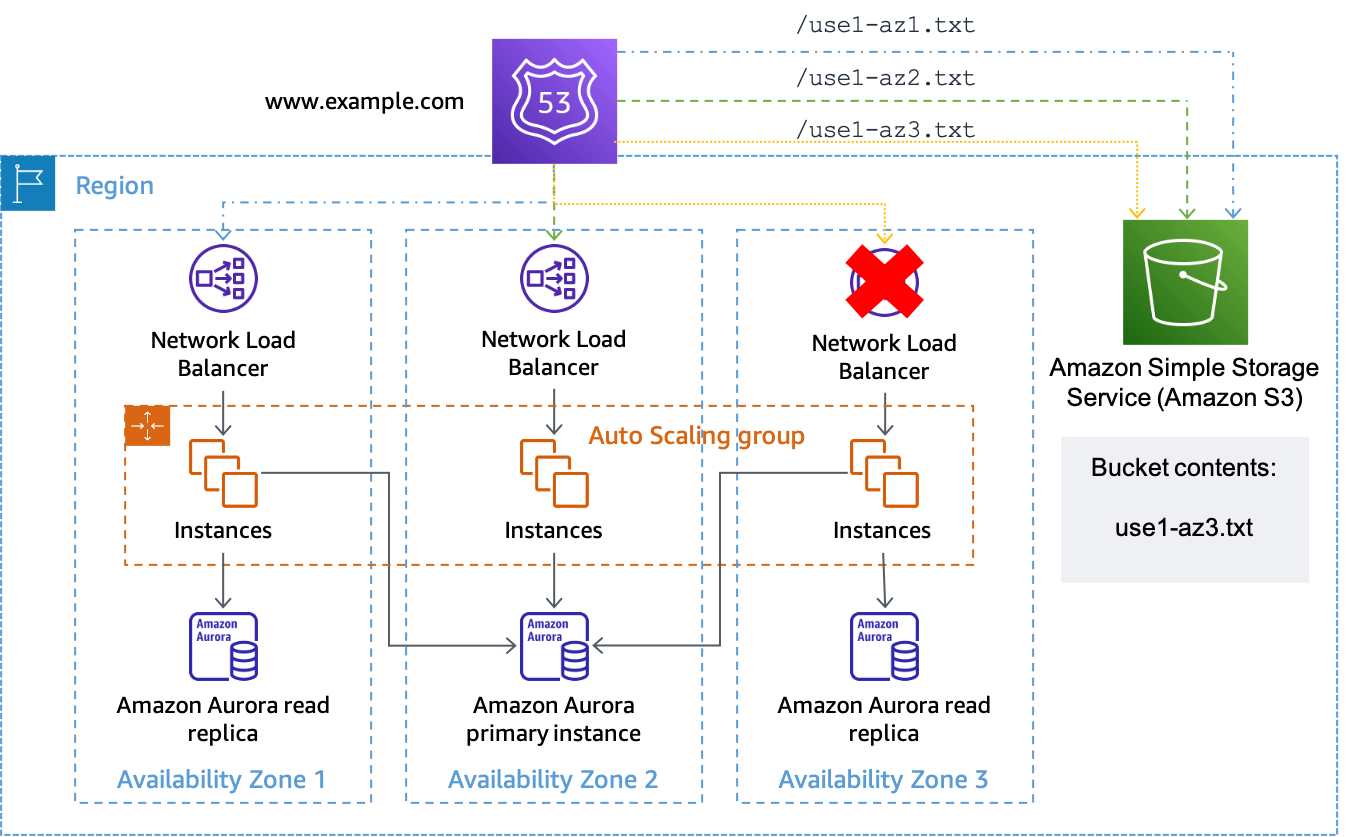
Using Amazon S3 as the target for a Route 53 health check
Using API Gateway and DynamoDB
The second implementation of this pattern uses an Amazon API Gateway
If you are using this solution with an NLB or ALB architecture, set up your DNS
records in the same way as the Amazon S3 example above, except change the health check path to
use the API Gateway endpoint and provide the AZ-ID in the URL path. For example, if
the API Gateway is configured with a custom domain of az-status.example.com, the
full request for use1-az1 would look like
https://az-status.example.com/status/use1-az1. When you want to initiate an
Availability Zone evacuation, you can create or update a DynamoDB item using the CLI or API.
The item uses the AZ-ID as its primary key and then has a Boolean attribute
called Healthy which is used indicate how API Gateway responds. The following is
example code used in the API Gateway configuration to make this determination.
#set($inputRoot = $input.path('$')) #if ($inputRoot.Item.Healthy['BOOL'] == (false)) #set($context.responseOverride.status = 500) #end
If the attribute is true (or isn’t present), API Gateway responds to the health
check with an HTTP 200, if it is false, it responds with an HTTP 500. This implementation
is shown in the following figure.
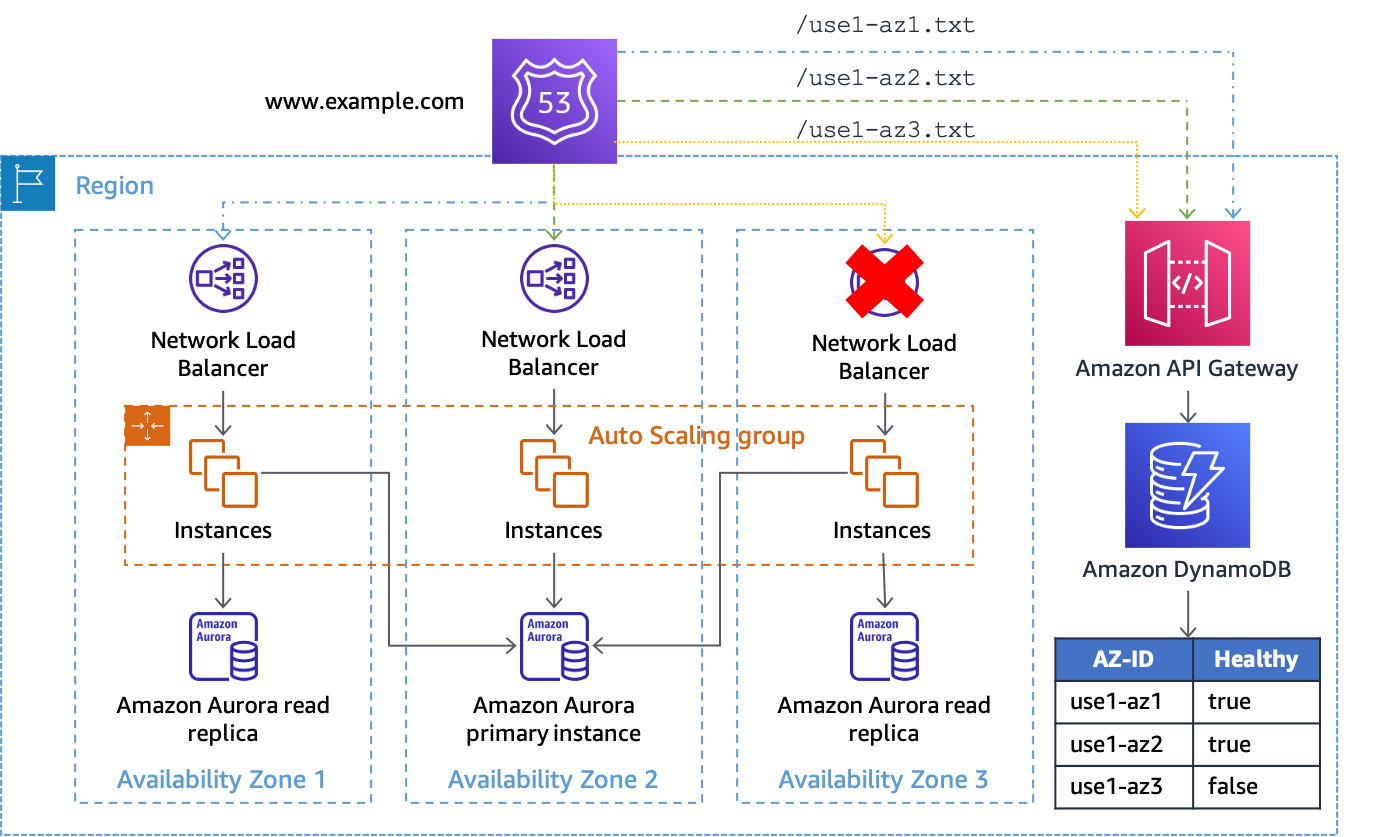
Using API Gateway and DynamoDB as the target of Route 53 health checks
In this solution you need to use API Gateway in front of DynamoDB so that you can make the
endpoint publicly accessible as well as manipulate the request URL into a
GetItem request for DynamoDB. The solution also provides flexibility if you
want to include additional data in the request. For example, if you wanted to create more
granular statuses, like per application, you can configure the health check URL to provide
an application ID in the path or query string that is also matched against the DynamoDB item.
The Availability Zone status endpoint can be deployed centrally so that multiple health check resources across AWS accounts can all use the same consistent view of Availability Zone health (ensuring that your API Gateway REST API and DynamoDB table are scaled to handle the load) and eliminates the need to share Route 53 health checks.
The solution could also be scaled across multiple AWS Regions using an Amazon DynamoDB global table
If you were building a solution for individual hosts to use as a mechanism to determine the health of their AZ, as an alternative, instead of providing a pull mechanism for health checks, you can use push notifications. One way to do this is with an SNS topic that your consumers subscribe to. When you want to trigger the circuit breaker, publish a message to the SNS topic that indicates which Availability Zone is impaired. This approach makes tradeoffs with the former. It removes the need to create and operate the API Gateway infrastructure and perform capacity management. It can also potentially provide faster convergence of the Availability Zone state. However, it removes the ability to perform ad hoc queries and relies on the SNS delivery retry policy to ensure each endpoint receives the notification. It also requires each workload or service to build a way to receive the SNS notification and take action on it.
For example, each new EC2 instance or container that is launched will need to subscribe to the topic with an HTTP endpoint during its bootstrap. Then, each instance needs to implement software that listens on this endpoint where the notification is delivered. Additionally, if the instance is impacted by the event, it may not receive the push notification and continue to do work. Whereas, with a pull notification, the instance will know if its pull request fails and can choose what action to take in response.
A second way to send push notifications is with long-lived WebSocket connections. Amazon API Gateway can be used to provide a WebSocket API that consumers can connect to and receive a message when sent by the backend. With a WebSocket, instances can both do periodic pulls to ensure their connection is healthy and also receive low-latency push notifications.
