This whitepaper is for historical reference only. Some content might be outdated and some links might not be available.
Data security and governance
Security within data lakes is addressed in two areas.
-
Security of data at rest
-
Security of data in transit
Data at rest — With AWS, you have many options that can potentially meet your encryption needs. Within the data lake framework, data primarily resides in the primary datastore (for example, Amazon S3) and in certain use-cases in secondary datastore (for example, S3 in a non-primary Region, or Outposts). Refer to the latest AWS documentation for the latest details:
-
For S3, Protecting data using server-side encryption - Amazon Simple Storage Service
-
For Outposts, Data protection in AWS Outposts - AWS Outposts
-
For importance of encryption, refer to The importance of encryption and how AWS can help
on the AWS Security blog
Data in transit — To protect data in transit, AWS encourages customers to use a multi-level approach. All network traffic between AWS data centers is transparently encrypted at the physical layer. All traffic within a VPC and between peered VPCs across Regions is transparently encrypted at the network layer when using supported Amazon EC2 instance types. At the application layer, customers have a choice about whether and how to use encryption using a protocol like Transport Layer Security (TLS). All AWS service endpoints support TLS to create a secure HTTPS connection to make API requests. Refer to our latest documentation for the latest details:
-
Implement secure key and certificate management
How to regulate your data (GDPR, CCPA, and COPPA)
Regulations such as
GDPR
First, you need to scan through all data in the data lake to identify partitions that contain records with the user ID you need.
Second, you cannot delete a single record from a Parquet file or update a single Parquet file within a partition - you’ll have to re-calculate and re-write the whole partition.
Both operations are very time- and resource-consuming on a big data lake, because they involve many metadata operations (such as S3 LIST), and they must scan through all data.
There are two main approaches to solve this: avoid storing PII in the data lake, or implement an additional metadata layer to reduce the number of operations and volume of data to scan to search for a specific user ID, and delete the corresponding data.
The safest way to comply with regulatory frameworks is to not store PII in the data lake. Depending on what kind of analytics you require, this may or may not be possible. For example, you can get rid of any forms of user identifiers in your data lake, but this will make any kind of per-user aggregations, often required by analytics, impossible.
A common approach is to replace real user identifiers with surrogate ones, store these mappings in a separate table outside of the data lake, and avoid storing any other kind of user information besides these internal IDs. This way, you can still analyze user behavior without knowing who the user is. The data lake itself doesn’t store any PII in this case. It’s enough to delete a mapping for a specific user from an external table to make data records in the data lake not relatable to users. Consult your legal department to find out if this is enough to comply with regulatory requirements in your case.
There are also a number of techniques to impersonate data, such as masking, hashing, blurring, modifying numbers by a random percent, and so on. They can be used to impersonate other personally identifiable data, if you choose to store it in a data lake. There are some third-party products such as Dataguise or Collibra (available on the AWS Marketplace) to automate this.
Another approach is to optimize user ID lookup and delete performance, usually by implementing an additional metadata layer. This might be required if your legal department tells you impersonation or surrogate IDs are not enough to comply. You can build your own solution to maintain indexes by user_id, or use an open-data formats such as Apache Hudi in the data lake.
You can build your own solution for indexing. For example, you can
maintain an index of files in the data lake by user ID, and update
it when new files are added with a Lambda function. Then a delete
job can re-write only those files directly. An example of such a
solution is described in the
How
to delete user data in an AWS data lake
For an alternative approach which provides additional benefits such as versioning, transactions, and improved performance, use one of the data formats such as Apache Hudi, Delta Lake, or Apache Iceberg for the data lake. Such solutions maintain additional metadata on top of open file formats such as Parquet or AVRO to enable upsert/delete. When using these solutions, you can delete specific user data by ID with an SQL query or a Spark job. This will still be expensive in terms of reads, but it will be much faster on write. Generally, such delete jobs can work in reasonable time, even in big data lakes.
The downside is that you’ll need to use analytical engines and ETL tools that support such formats. The degree of support by AWS services varies for different formats. Hudi is probably a good place to start. Amazon Redshift, Athena, AWS Glue, and EMR all support it. Specific feature support can also vary by service. Be sure to check the specific service’s documentation.
Data discovery
Data discovery refers to the overall recognition of patterns in
data stored on AWS. Services such as
Amazon Macie
-
Extract value from stored data within the business SLA
-
Prevent sensitive data types to be ingested into a data lake
For an example of discovering sensitive data, refer to
Use
Macie to discover sensitive data as part of automated data
pipelines
For information on Amazon RDS as a data store, refer to
Enabling
data classification for Amazon RDS database with Macie
For information on detecting sensitive data in DynamoDB, refer to
Detecting
sensitive data in DynamoDB with Macie
Data governance
Data governance refers to the overall management of data assets in terms of the availability, quality, usability, lineage and security of the data in an organization. Data governance largely depends upon business policies and usually covers the following areas:
-
Data ownership and accountability
-
Have proper structure in place to determine permissions and roles for data in raw, curated, and processed formats.
-
Ability to monitor all API calls made within AWS, which is critical to audit any suspicious actions in your AWS account.
-
-
Enforcing policies and rules
-
Developing policies based on the organizational structure regarding what the data will be used for, and who can access it.
-
Having automation in place for data sharing, data quality, alerts, and faster access to data for users with proper permissions.
-
-
Technical processes, tools and practices
-
AWS Lake Formation
is an integrated data lake service that makes it easy for you to ingest, clean, catalog, transform, and secure your data and make it available for analysis and machine learning. Lake Formation gives you a central console where you can discover data sources, set up transformation jobs to move data to an Amazon S3 data lake, remove duplicates and match records, catalog data for access by analytic tools, configure data access and security policies, and audit and control access from AWS analytic and ML services. Lake Formation offers features that make it easy to govern and administer data in your data lake: -
Governed tables allow your data lake to support atomicity, consistency, isolation, durability (ACID) transactions, where you can add and delete S3 objects reliably, while protecting the integrity of the data catalog.
-
Row level security provides security at the table, column, and row level, and is managed directly from Lake Formation. You can apply row level security to S3-based tables such as AWS Glue Data Catalog, Amazon Redshift data shares, Governed, Apache Hive, Apache Hudi, and more.
-
AWS Glue Data Catalog is a persistent metadata store and contains information about your data such as format, structure, size, data types, data fields, row count, and more. You can register databases and tables within the AWS Glue Data Catalog, which is integrated with many native AWS services.
-
AWS CloudTrail
for auditing and monitoring API calls made within your AWS accounts and is built directly into Lake Formation. 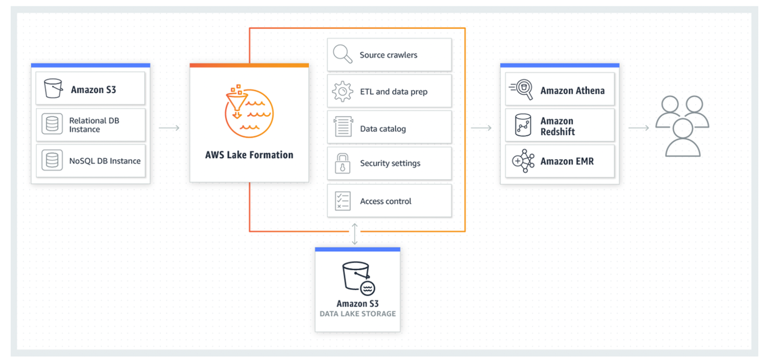
Lake Formation manages all of the tasks shown here, and is integrated with the AWS data stores and services
-
AWS Glue DataBrew
helps by giving you a visual interface to prepare, profile data, and track lineage in a repeatable, automated fashion. DataBrew can take your raw data that has come in and run the automation recipe you have set for it, like removing columns, formatting some of the values or headers, and then write the processed data to Amazon S3 for downstream consumption of other analytical or machine learning services. AWS Glue DataBrew can also be used for data quality automation and alerts. -
Open-source tools such as Apache Atlas, Deequ, and Apache Ranger are also popular among customers who are comfortable managing and setting up the infrastructure and required configurations, as these tools do not natively integrate with other AWS services like Athena or Glue.
-
-
Unlike data management, where the primary concern is usage of data in making sound business decisions, data governance is concerned with how disciplined you are in managing and using the data across the organization. Without data governance and proper mechanisms to maintain it, the data lake risks becoming a data swamp, and being a collection of disconnected data silos.
