This whitepaper is for historical reference only. Some content might be outdated and some links might not be available.
Identity and access management
To establish a secure ML environment, both human and machine identities need to be defined
and created to allow for the intended access into the environment. AWS Identity and Access Management
For managing human users, identity federation is the recommended practice to allow for
employee lifecycle events to be reflected in your ML environment when they are made in the
source identity provider. You can set up identity federation
After configuring identity management for your environment, you’ll need to define the permissions necessary for your users and services. Following is a list of user and service roles to consider for your ML environment:
User roles
User roles are assigned to the actual people who perform operations in an AWS account through AWS Management Console, The AWS Command Line Interface (AWS CLI), or APIs. Following are some of the primary user roles:
-
Data scientist/ML engineering role — The IAM role for the data scientist / ML engineer persona provides access to the resources and services that are mainly used for experimentation. These services could include Amazon SageMaker AI Studio or SageMaker Notebook for data science notebook authoring, Amazon S3 for data access, and Amazon Athena
for data querying against the data sources. Multiple such roles might be needed for the different data scientists or different teams of data scientists to ensure proper separation of data and resources. -
Data engineering role — The IAM role for the data engineering persona provides access to the resources and services mainly used for data management, data pipeline development, and operations. These services could include S3, AWS Glue
, Amazon EMR , Athena, Amazon Relational Database Service (Amazon RDS), SageMaker AI Feature Store, and SageMaker AI Notebooks. Multiple such roles might be needed for the different data engineering teams to ensure proper separation of data and resources. -
MLOps engineering role — The IAM role for the MLOps persona provides access to the resources and services mainly used for building automation pipelines and infrastructure monitoring. These services could include SageMaker AI for model training and deployment, and services for ML workflow such as AWS CodePipeline, AWS CodeBuild, AWS CloudFormation, Amazon ECR, AWS Lambda
, and AWS Step Functions .
Service roles
Services roles are assumed by AWS services to perform different tasks such as running a SageMaker AI training job or Step Functions workflow. Following are some of the main service roles:
-
SageMaker notebook execution role — This role is assumed by a SageMaker AI Notebook instance or SageMaker AI Studio Application when code or AWS commands (such as CLI) are run in the notebook instance or Studio environment. This role provides access to resources such as the SageMaker AI training service, or hosting service from the notebook and Studio environment. This role is different from the data scientist / ML engineer user role.
-
SageMaker processing job role — This role is assumed by SageMaker AI processing when a processing job is run. This role provides access to resources such as an S3 bucket to use for input and output for the job. While it might be feasible to use theSageMaker AI notebook executionrole to run the processing job, it is best practice to have this as a separate role to ensure it is in accordance with least privilege standard.
-
SageMaker AI training/tuning job role — This role is assumed by the SageMaker AI training/tuning job when the job is run. Similarly, the SageMaker AI notebook executionrole can be used to run the training job. However, it is a good practice to have a separate role, which prevents giving end-users more rights than required.
-
SageMaker AI model execution role — This role is assumed by the inference container hosting the model when deployed to a SageMaker AI endpoint or used by the SageMaker Batch Transform job.
-
Other service roles — Other services such as AWS Glue, Step Functions, and CodePipeline also need service roles to assume when running a job or a pipeline.
The following figure shows the typical user and service roles for a SageMaker AI user and SageMaker AI service functions.
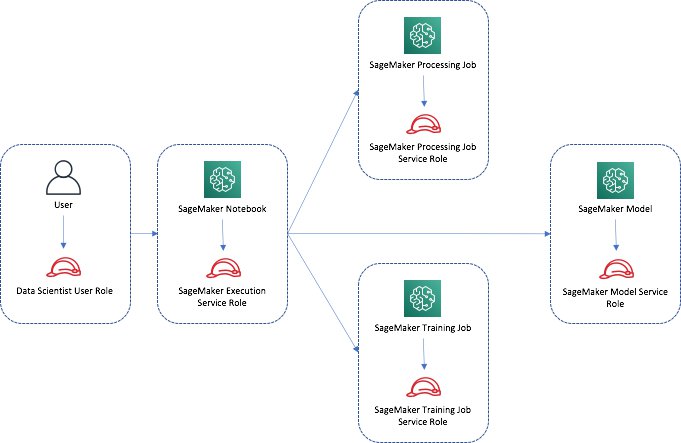
User role and services roles for Sagemaker
