This whitepaper is for historical reference only. Some content might be outdated and some links might not be available.
Access logs
Access logs can help you troubleshoot or analyze traffic coming to your site. Both Amazon CloudFront and Amazon S3 give you the option of turning on access logs. There’s no extra charge to enable logging, other than the storage of the actual logs. The access logs are delivered on a best-effort basis; they are usually delivered within a few hours after the events are recorded.
Analyzing logs
Amazon S3 access logs are deposited in your Amazon S3 bucket as plain text files. Each record in the log files provides details about a single Amazon S3 access request, such as the requester, bucket name, request time, request action, response status, and error code, if any. You can open individual log files in a text editor or use a third-party tool that can interpret the Amazon S3 access log format.
CloudFront logs are deposited in your Amazon S3 bucket as GZIP-compressed text files. CloudFront logs follow the standard W3C extended log file format and can be analyzed using any log analyzer.
You can also build out a custom analytics solution using AWS Lambda and Amazon OpenSearch Service. AWS Lambda functions can be hooked to an Amazon S3 bucket to detect when new log files are available for processing. AWS Lambda function code can process the log files and send the data to an Amazon OpenSearch Service cluster. Users can then analyze the logs by querying OpenSearch Service or using the Kibana visual dashboard. Both AWS Lambda and OpenSearch Service are managed services, and there are no servers to manage.
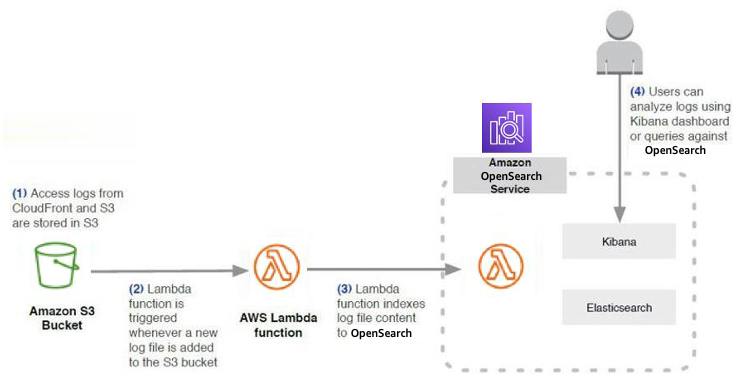
Using AWS Lambda to send logs from Amazon S3 to Amazon OpenSearch Service
Archiving and purging logs
Amazon S3 buckets don’t have a storage cap, and you’re free to retain logs for as long as you want. However, an AWS best practice is to archive files into Amazon S3 Glacier.
Amazon S3 Glacier
The easiest way to archive data into Amazon S3 Glacier is to use Amazon S3 lifecycle policies. The lifecycle policies can be applied to an entire Amazon S3 bucket or to specific objects within the bucket (for example, only the log files). A minute of configuration in the Amazon S3 console can reduce your storage costs significantly in the long run.
Here’s an example of setting up data tiering using lifecycle policies:
-
Lifecycle policy #1: After X days, automatically move logs from Amazon S3 into Amazon S3 Glacier.
-
Lifecycle policy #2: After Y days, automatically delete logs from Amazon S3 Glacier.
Data tiering is illustrated in the following figure.
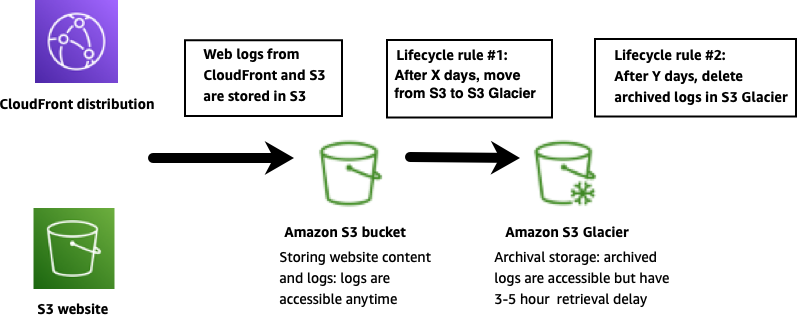
Data tiering using Amazon S3 lifecycle policies
