This whitepaper is for historical reference only. Some content might be outdated and some links might not be available.
Data ingestion methods
A core capability of a data lake architecture is the ability to quickly and easily ingest multiple types of data:
-
Real-time streaming data and bulk data assets, from on-premises storage platforms.
-
Structured data generated and processed by legacy on-premises platforms - mainframes and data warehouses.
Unstructured and semi-structured data – images, text files, audio and video, and graphs).
AWS provides services and capabilities to ingest different types of data into your data lake built on Amazon S3 depending on your use case. This section provides an overview of various ingestion services.
Amazon Kinesis Data Firehose
Amazon Data Firehose
Firehose can convert your input JSON data to Apache Parquet and Apache ORC before storing the
data into your data lake built on Amazon S3. Parquet and Orc being columnar data formats, help save
space and allow faster queries on the stored data compared to row-based formats such as JSON.
Firehose can compress data before it’s stored in Amazon S3. It currently supports GZIP, ZIP, and
SNAPPY compression formats. GZIP is the preferred format because it can be used by Amazon Athena,
Amazon EMR
Firehose also allows you to invoke Lambda functions to perform transformations on the input data. Using Lambda blueprints, you can transform the input comma-separated values (CSV), structured text, such as Apache Log and Syslog formats, into JSON first. You can optionally store the source data to another S3 bucket. The following figure illustrates the data flow between Firehose and different destinations.
Firehose also provides the ability to group and partition the target files using custom prefixes such as dates for S3 objects. This facilitates faster querying by the use of the partitioning and incremental processing further with the same feature.
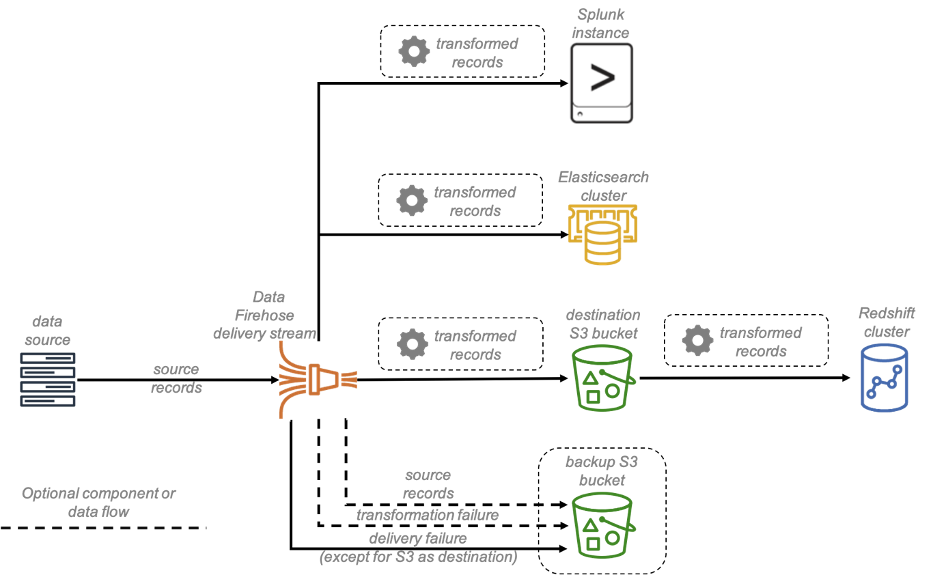
Delivering real-time streaming data with Kinesis Data Firehose to different destinations with optional backup
Firehose also natively integrates with Amazon Managed Service for Apache Flink which provides you with an efficient way to analyze and transform streaming data using Apache Flink and SQL applications. Apache Flink is an open-source framework and engine for processing streaming data using Java and Scala. Using Managed Service for Apache Flink, you can develop applications to perform time series analytics, feed real-time dashboards, and create real-time metrics. You can also use Managed Service for Apache Flink for transforming the incoming stream and create a new data stream that can be written back into Firehose before it is delivered to a destination.
Finally, Firehose encryption supports Amazon S3 server-side encryption with AWS Key Management Service
This is an important capability because it reduces the load of Amazon S3 transaction costs and transactions per second. You can grant your application access to send data to Firehose using AWS Identity and Access Management (IAM). Using IAM, you can also grant Firehose access to S3 buckets, Amazon Redshift cluster, or Amazon OpenSearch Service cluster. You can also use Kinesis Data Firehose with virtual private cloud (VPC) endpoints (AWS PrivateLink). AWS PrivateLink is an AWS technology that enables private communication between AWS services using an elastic network interface with private IPs in your Amazon VPC.
AWS Snow Family
AWS Snow Family
Snowball moves terabytes of data into your data lake built on Amazon S3. You can use it to transfer databases, backups, archives, healthcare records, analytics datasets, historic logs, IoT sensor data, and media content, especially in situations where network conditions hinder transfer of large amounts of data both into and out of AWS.
AWS Snow Family uses physical storage devices to transfer large amounts of data between
your on-premises data centers and your data lake built on Amazon S3. You can use AWS Storage Optimized Snowball Edge
Data is transferred from the Snowball Edge device to your data lake built on Amazon S3 and stored as S3 objects in their original or native format. Snowball Edge also has a Hadoop Distributed File System (HDFS) client, so data may be migrated directly from Hadoop clusters into an S3 bucket in its native format. Snowball Edge devices can be particularly useful for migrating terabytes of data from data centers and locations with intermittent internet access.
AWS Glue
AWS Glue
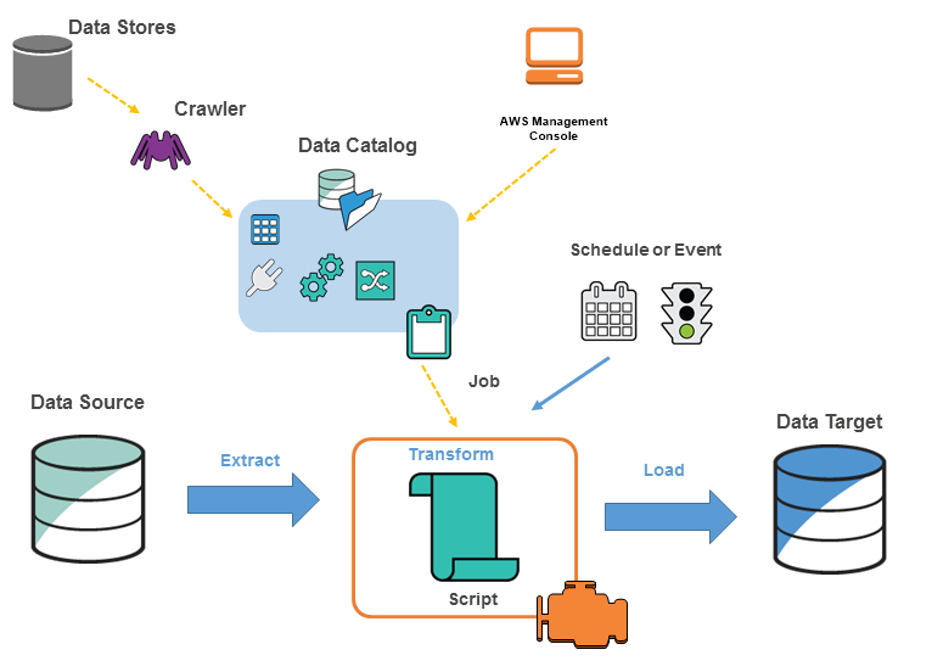
Architecture of an AWS Glue environment
To ETL the data from source to target, you create a job in AWS Glue, which involves the following steps:
-
Before you can run an ETL job, define a crawler and point it to the data source to identify the table definition and the metadata required to run the ETL job. The metadata and the table definitions are stored in the Data Catalog. The data source can be an AWS service, such as Amazon RDS, Amazon S3, Amazon DynamoDB, or Kinesis Data Streams, as well as a third-party JDBC-accessible database. Similarly, a data target can be an AWS service, such as Amazon S3, Amazon RDS, and Amazon DocumentDB (with MongoDB compatibility), as well as a third-party JDBC-accessible database.
-
Either provide a script to perform the ETL job, or AWS Glue can generate the script automatically.
-
Run the job on-demand or use the scheduler component that helps in initiating the job in response to an event and schedule at a defined time.
-
When the job is run, the script extracts the data from the source, transforms the data, and finally loads the data into the data target.
AWS DataSync
AWS DataSync
AWS Transfer Family
AWS Transfer Family
Storage Gateway
Storage Gateway
Apache Hadoop distributed copy command
Amazon S3 natively supports distributed copy (DistCp), which is a standard Apache Hadoop data transfer mechanism. This allows you to run DistCp jobs to transfer data from an on-premises Hadoop cluster to an S3 bucket. The command to transfer data is similar to the following:
hadoop distcp hdfs://source-folder s3a://destination-bucket
AWS Direct Connect
AWS Direct Connect
AWS Database Migration Service
AWS Database Migration Service
You can also write the data into Apache Parquet format (parquet) for more compact storage and faster query options. Both CSV and parquet formats are favorable for in-place querying using services such as Amazon Athena and Amazon Redshift Spectrum (refer to the In-place querying section of this document for more information). As mentioned earlier, Parquet format is recommended for analytical querying. It is useful to use AWS DMS to migrate databases from on-premises to or across different AWS accounts to your data lake built on Amazon S3 during initial data transfer or on a regular basis.
