Introduction
Your workload must perform its intended function correctly and consistently. To achieve this, you must architect for resiliency. Resiliency is the ability of a workload to recover from infrastructure, service, or application disruptions, dynamically acquire computing resources to meet demand, and mitigate disruptions, such as misconfigurations or transient network issues.
Disaster recovery (DR) is an important part of your resiliency strategy and concerns how your workload responds when a disaster strikes (a disaster is an event that causes a serious negative impact on your business). This response must be based on your organization's business objectives which specify your workload's strategy for avoiding loss of data, known as the Recovery Point Objective (RPO), and reducing downtime where your workload is not available for use, known as the Recovery Time Objective (RTO). You must therefore implement resilience in the design of your workloads in the cloud to meet your recovery objectives (RPO and RTO) for a given one-time disaster event. This approach helps your organization to maintain business continuity as part of Business Continuity Planning (BCP).
This paper focuses on how to plan for, design, and implement architectures on AWS that meet the disaster recovery objectives for your business. The information shared here is intended for those in technology roles, such as chief technology officers (CTOs), architects, developers, operations team members, and those tasked with assessing and mitigating risks.
Disaster recovery and availability
Disaster recovery can be compared to availability, which is another important component of your resiliency strategy. Whereas disaster recovery measures objectives for one-time events, availability objectives measure mean values over a period of time.

Figure 1 - Resiliency Objectives
Availability is calculated using Mean Time Between Failures (MTBF) and Mean Time to Recover (MTTR):

This approach is often referred to as “nines”, where a 99.9% availability target is referred to as “three nines”.
For your workload, it may be easier to count successful and failed requests instead of using a time-based approach. In this case, the following calculation can be used:
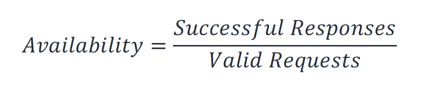
Disaster recovery focuses on disaster events, whereas availability focuses on more common disruptions of smaller scale such as component failures, network issues, software bugs, and load spikes. The objective of disaster recovery is business continuity, whereas availability concerns maximizing the time that a workload is available to perform its intended business functionality. Both should be part of your resiliency strategy.
Are you Well-Architected?
The AWS
Well-Architected Framework
The concepts covered in this whitepaper expand on the best practices contained in the Reliability Pillar whitepaper, specifically question REL 13, “How do you plan for disaster recovery (DR)?”. After implementing the practices in this whitepaper, be sure to review (or re-review) your workload using the AWS Well-Architected Tool.
