Amazon Forecast 不再向新买家开放。Amazon Forecast 的现有客户可以继续照常使用该服务。了解更多
本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
评估预测器准确率
Amazon Forecast 会生成准确性指标来评估预测器,并帮助您选择使用哪种预测器来生成预测。Forecast 使用均方根误差(RMSE)、加权分位数损失(wQL) 、平均绝对百分比误差(MAPE)、平均绝对比例误差(MASE) 和加权绝对百分比误差(WAPE)指标来评估预测器。
Amazon Forecast 使用回测来调整参数并生成准确性指标。在回测期间,Forecast 会自动将您的时间序列数据分成两组:训练集和测试集。训练集用于训练模型和生成测试集内数据点的预测。Forecast 通过将预测值与测试集中的观测值进行比较来评估模型的准确性。
Forecast 允许您使用不同的预测类型来评估预测器,这些预测类型可以是一组分位数预测和均值预测。均值预测提供点估计值,而分位数预测通常提供一系列可能的结果。
Python 笔记本
有关评估预测指标的 step-by-step指南,请参阅使用项目级回测计算指标
解释准确性指标
Amazon Forecast 使用均方根误差(RMSE)、加权分位数损失(wQL) 、平均加权分位数损失(平均 wQL)、平均绝对比例误差(MASE)、平均绝对百分比误差(MAPE) 和加权绝对百分比误差(WAPE)指标来评估预测器。除了总体预测器的指标外,Forecast 还会计算每个回测窗口的指标。
您可以使用 Amazon Forecast 软件开发工具包(SDK)和 Amazon Forecast 控制台查看预测器的准确性指标。
注意
对于平均 wQL、wQL、RMSE、MASE、MAPE 和 WAPE 指标,值越低表示模型越好。
加权分位数损失(wQL)
加权分位数损失(wQL)指标用于衡量模型在指定分位数下的准确性。当预测过低和预测过高的成本不同时,它特别有用。通过设置 wQL 函数的权重(τ),您可以自动合并针对预测过低和预测过高的不同惩罚。
损失函数的计算方法如下。
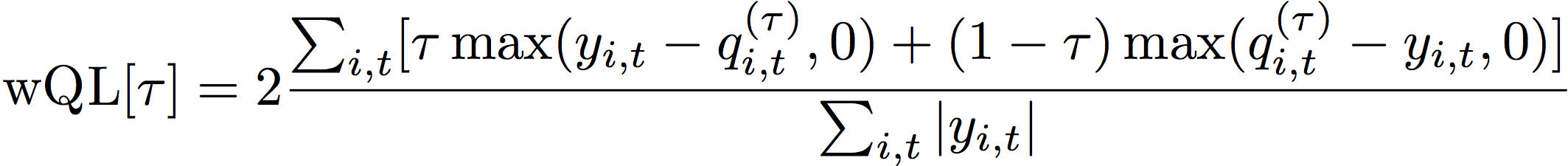
- 其中:
-
τ - 集合{0.01、0.02、...、0.99}中的一个分位数
qi,t(τ) - 模型预测的 τ-分位数。
yi,t - 点(i, t)处的观测值
wQL 的分位数(τ)的范围为 0.01(P1)到 0.99(P99)。无法计算均值预测的 wQL 指标。
默认情况下,Forecast 在 0.1(P10)、0.5(P50)和 0.9 (P90)处计算 wQL。
-
P10(0.1) - 预期真实值将在 10% 的时间内低于预测值。
-
P50(0.5) - 预期真实值将在 50% 的时间内低于预测值。这也称作中值预测。
-
P90(0.9) - 预期真实值将在 90% 的时间内低于预测值。
在零售业中,库存不足的成本通常高于库存过剩的成本,因此,P75(τ = 0.75)处的预测可能比在中值分位数(P50)处的预测更能提供信息。在这些情况下,wQL[0.75] 为预测过低(0.75)分配较大的惩罚权重 ,为预测过高(0.25)分配较小的惩罚权重。

上图显示了 wQL[0.50] 和 wQL[0.75] 的不同需求预测。P75 处的预测值明显高于 P50 处的预测值,因为 P75 处的预测预计将在 75% 的时间内满足需求,而 P50 处的预测预计仅在 50%的时间内满足需求。
在给定的回测窗口中,当所有项目和所有时间点的观测值之和近似为零时,未定义加权分位数损失表达式。在这些情况下,Forecast 会输出未加权分位数损失,这是 wQL 表达式中的分子。
Forecast 还会计算平均 wQL,即所有指定分位数的加权分位数损失的平均值。默认情况下,这将是 wQL[0.10]、wQL[0.50] 和 wQL[0.90] 的平均值。
加权绝对百分比误差(WAPE)
加权绝对百分比误差(WAPE)用于测量预测值与观测值的总体偏差。WAPE 的计算方法是将观测值和预测值相加,然后计算这两个值之间的误差。值越低表示模型越准确。
在给定的回测窗口中,当所有时间点和所有项目的观测值之和近似为零时,未定义加权绝对百分比误差表达式。在这些情况下,Forecast 会输出未加权绝对误差和,这是 WAPE 表达式中的分子。
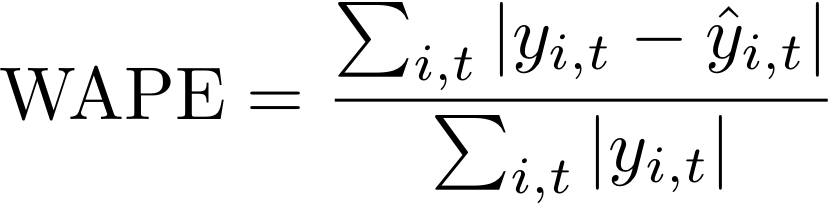
- 其中:
-
yi,t - 点(i, t)处的观测值
ŷi,t - 点(i, t)处的预测值
Forecast 使用预测均值作为预测值,ŷi,t。
WAPE 对异常值比均方根误差(RMSE)更稳健,因为它使用绝对误差而不是平方误差。
Amazon Forecast 之前将 WAPE 指标称为平均绝对百分比误差(MAPE),并使用预测中值(P50)作为预测值。Forecast 现在使用预测均值来计算 WAPE。wQL[0.5] 指标等同于 WAPE [中值] 指标,如下所示:
![Mathematical equation showing the equivalence of wQL[0.5] and WAPE[median] metrics.](images/wql-to-wape.PNG)
均方根误差(RMSE)
均方根误差(RMSE)是平方误差平均值的平方根,因此与其他准确性指标相比,它对异常值更敏感。值越低表示模型越准确。
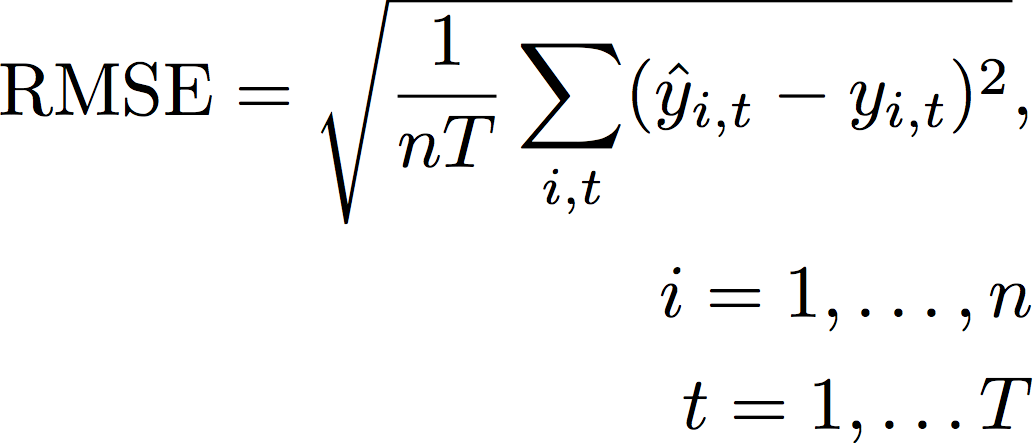
- 其中:
-
yi,t - 点(i, t)处的观测值
ŷi,t - 点(i, t)处的预测值
nT - 测试集中的数据点数量
Forecast 使用预测均值作为预测值,ŷi,t。在计算预测器指标时,nT 是回测窗口中的数据点的数量。
RMSE 使用残差的平方值,这会放大异常值的影响。在只有少数重大错误预测可能造成代价高昂的用例中,RMSE 是更相关的指标。
2020 年 11 月 11 日之前创建的预测器默认使用 0.5 分位数 (P50)计算 RMSE。Forecast 现在使用均值预测。
平均绝对百分比误差(MAPE)
平均绝对百分比误差(MAPE)取每个单位时间内观测值和预测值之间百分比误差的绝对值,并取这些值的平均值。值越低表示模型越准确。
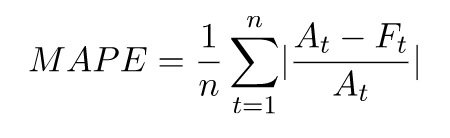
- 其中:
-
At - 点 t 处的观测值
Ft - 点 t 处的预测值
n - 时间序列中的数据点的数量
Forecast 使用预测均值作为预测值, Ft。
MAPE 对于时间点之间的值存在显着差异且异常值会产生重大影响的情况非常有用。
平均绝对比例误差(MASE)
平均绝对比例误差(MASE)的计算方法是将平均误差除以比例系数。此比例系数取决于季节性值 m,根据预测频率选择该值。值越低表示模型越准确。

- 其中:
-
Yt - 点 t 处的观测值
Yt-m - 点 t-m 处的观测值
ej - 点 j 处的误差(观测值-预测值)
m - 季节性值
Forecast 使用预测均值作为预测值。
MASE 非常适合具有周期性或具有季节性特性的数据集。例如,对夏季需求量大、冬季需求量小的项目进行预测,可以从考虑季节性影响中获益。
导出准确性指标
注意
导出的文件可以直接从数据集导入中返回信息。如果导入的数据包含公式或命令,则文件易受 CSV 注入影响。因此,导出的文件可能会提示安全警告。为避免恶意活动,请在读取导出的文件时禁用链接和宏。
Forecast 允许您导出回测期间生成的预测值和准确性指标。
您可以使用这些导出文件来评估特定时间点和分位数的特定项目,从而更好地了解您的预测器。回测导出文件将发送到指定的 S3 位置,并包含两个文件夹:
-
forecasted-values 文件夹:包含 CSV 或 Parquet 文件,其中包含每个回测的每种预测类型的预测值。
-
accuracy-metrics-values:包含 CSV 或 Parquet 文件,其中包含每次回测的指标,以及所有回测的平均值。这些指标包括每个分位数的 wQL、平均 wQL、RMSE、MASE、MAPE 和 WAPE。
forecasted-values 文件夹包含每个回测窗口中每种预测类型的预测值。它还包括有关项目 IDs、尺寸、时间戳、目标值以及回测窗口开始和结束时间的信息。
accuracy-metrics-values 文件夹包含每个回测窗口的准确性指标,以及所有回测窗口的平均指标。它包含每个指定分位数的 wQL 指标,以及平均 wQL、RMSE、MASE、MAPE 和 WAPE 指标。
两个文件夹中的文件都遵循命名约定:<ExportJobName>_<ExportTimestamp>_<PartNumber>.csv.
您可以使用 Amazon Forecast 软件开发工具包(SDK)和 Amazon Forecast 控制台导出准确性指标。

选择预测类型
Amazon Forecast 使用预测类型来创建预测并评估预测器。预测类型有以下两种形式:
-
均值预测类型 - 使用均值作为预期值的预测。通常用作给定时间点的点预测。
-
分位数预测类型 - 在指定分位数处的预测。通常用于提供预测区间,预测区间是考虑预测不确定性的可能值范围。例如,在
0.65分位数处的预测将估计值在 65% 的时间内低于观测值。
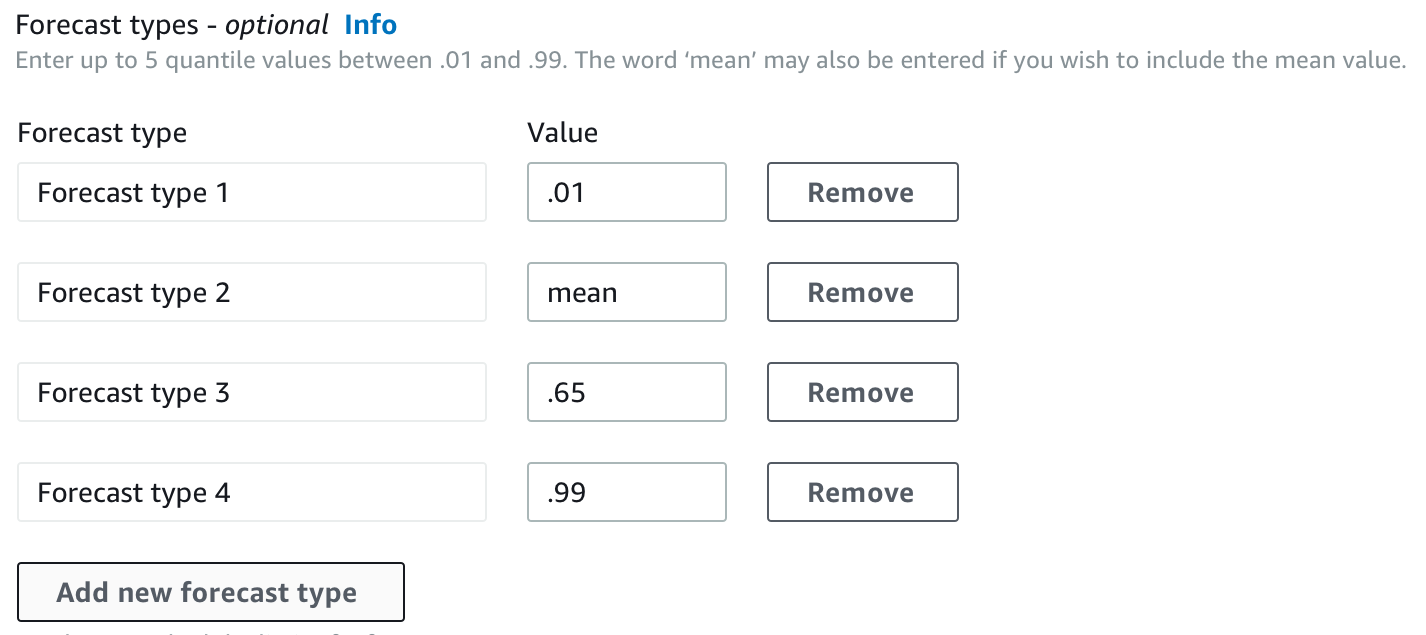
默认情况下,Forecast 对预测器预测类型使用以下值:0.1(P10)、0.5(P50)和 0.9(P90)。您最多可以选择五种自定义预测类型,包括 mean 和分位数,范围从 0.01(P1)到 0.99(P99)。
分位数可以为预测提供上限和下限。例如,使用预测类型 0.1(P10)和 0.9(P90)可提供一个称为 80% 置信区间的值范围。预计观测值在 10% 的时间内将低于 P10 值,预计 P90 值在 90% 的时间内将高于观测值。通过在 p10 和 P90 处生成预测,您可以预期真实值在 80% 的时间内会落在这些界限之间。下图中,P10 和 P90 之间的阴影区域描绘了这些值的范围。
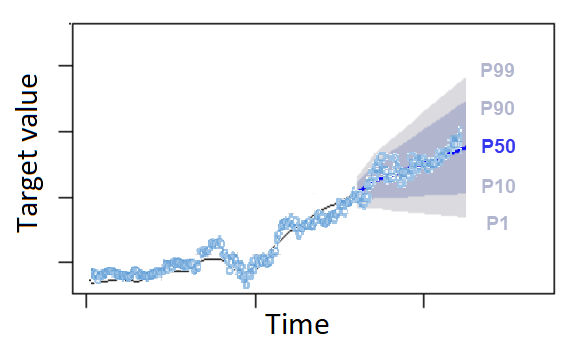
当预测过低和预测过高的成本不同时,您也可以使用分位数预测作为点预测。例如,在某些零售案例中,库存不足的成本高于库存过剩的成本。在这些情况下,0.65(P65)处的预测比中值(P50)或均值预测更能提供信息。
训练预测器时,您可以使用 Amazon Forecast 软件开发工具包(SDK)和 Amazon Forecast 控制台选择自定义预测类型。
使用传统预测器
设置回测参数
Forecast 使用回测来计算准确性指标。如果您运行多个回测,Forecast 会在所有回测窗口中计算每个指标的平均值。默认情况下,Forecast 计算一个回测,回测窗口(测试集)的大小等于预测范围的长度(预测窗口)。在训练预测器时,您可以设置回测窗口长度和回测场景数量。
Forecast 会在回测过程中忽略填充值,并且在给定回测窗口内具有填充值的任何项目都将从该回测中排除。这是因为 Forecast 仅在回测期间将预测值与观测值进行比较,而填充值不是观测值。
回测窗口必须至少与预测范围一样大,并且小于整个目标时间序列数据集长度的一半。您可以从 1 到 5 个回测中进行选择。

通常,增加回测数量会产生更可靠的准确性指标,因为测试期间使用了大部分时间序列,并且 Forecast 能够取所有回测指标的平均值。
您可以使用 Amazon Forecast 软件开发工具包(SDK)和 Amazon Forecast 控制台设置回测参数。

HPO 和 AutoML
默认情况下,Amazon Forecast 使用 0.1(P10)、0.5(P50)和 0.9(P90)分位数在超参数优化(HPO)期间进行超参数调整,在 AutoML 期间进行模型选择。如果您在创建预测器时指定了自定义预测类型,Forecast 将在 HPO 和 AutoML 期间使用这些预测类型。
如果指定了自定义预测类型,Forecast 将使用这些指定的预测类型来确定 HPO 和 AutoML 期间的最佳结果。在 HPO 期间,Forecast 使用第一个回测窗口来查找最佳超参数值。在 AutoML 期间,Forecast 使用所有回测窗口的平均值和 HPO 中的最佳超参数值来找到最佳算法。
针对 AutoML 和 HPO,Forecast 选择可最大限度减少预测类型平均损失的选项。您还可以使用以下其中一项准确性指标在 AutoML 和 HPO 期间优化预测器:平均加权分位数损失(平均 wQL)、加权绝对百分比误差(WAPE)、均方根误差(RMSE)、平均绝对百分比误差(MAPE)或平均绝对比例误差(MASE)。
您可以使用 Amazon Forecast 软件开发工具包(SDK)和 Amazon Forecast 控制台选择优化指标。
