终止支持通知:2026 年 5 月 31 日, AWS 将终止对的支持。 AWS Panorama 2026 年 5 月 31 日之后,您将无法再访问 AWS Panorama 控制台或 AWS Panorama 资源。有关更多信息,请参阅AWS Panorama 终止支持。
本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
计算机视觉模型
计算机视觉模型是一种经过训练的软件程序,用于检测图像中的对象。模型首先通过训练分析这些对象的图像,从而学习识别一组对象。计算机视觉模型将图像作为输入并输出有关其检测到的对象的信息,例如对象的类型及其位置。AWS Panorama 支持使用 PyTorch、Apache MXNet 和 TensorFlow构建的计算机视觉模型。
注意
有关已使用 AWS Panorama 测试的预构建模型的列表,请参阅模型兼容性
在代码中使用模型
模型返回一个或多个结果,其中可能包括检测到的类别的概率、位置信息和其他数据。以下示例演示了如何对视频流中的图像运行推理,并将模型的输出发送到处理函数。
例 application.py
def process_media(self, stream): """Runs inference on a frame of video.""" image_data = preprocess(stream.image,self.MODEL_DIM) logger.debug('Image data: {}'.format(image_data)) # Run inference inference_start = time.time()inference_results = self.call({"data":image_data}, self.MODEL_NODE)# Log metrics inference_time = (time.time() - inference_start) * 1000 if inference_time > self.inference_time_max: self.inference_time_max = inference_time self.inference_time_ms += inference_time # Process results (classification)self.process_results(inference_results, stream)
以下示例演示了一个处理基本分类模型结果的函数。示例模型返回一个概率数组,该数组是结果数组中的第一个也是唯一的值。
例 application.py
def process_results(self, inference_results, stream): """Processes output tensors from a computer vision model and annotates a video frame.""" if inference_results is None: logger.warning("Inference results are None.") return max_results = 5 logger.debug('Inference results: {}'.format(inference_results)) class_tuple = inference_results[0] enum_vals = [(i, val) for i, val in enumerate(class_tuple[0])] sorted_vals = sorted(enum_vals, key=lambda tup: tup[1]) top_k = sorted_vals[::-1][:max_results] indexes = [tup[0] for tup in top_k] for j in range(max_results): label = 'Class [%s], with probability %.3f.'% (self.classes[indexes[j]], class_tuple[0][indexes[j]]) stream.add_label(label, 0.1, 0.1 + 0.1*j)
应用程序代码会查找概率最高的值,并将其映射到初始化期间加载的资源文件中的标签。
构建自定义模型
您可以在 Apache MXNet 和 AWS Panorama 应用程序 TensorFlow 中使用自己构建的模型。 PyTorch作为在 SageMaker AI 中构建和训练模型的替代方案,您可以使用经过训练的模型或使用支持的框架构建和训练自己的模型,然后将其导出到本地环境或 Amazon 中 EC2。
注意
有关 SageMaker AI Neo 支持的框架版本和文件格式的详细信息,请参阅 Amazon A SageMaker I 开发者指南中的支持的框架。
本指南的存储库提供了一个示例应用程序,以 TensorFlow SavedModel格式演示 Keras 模型的此工作流程。它使用 TensorFlow 2,可以在虚拟环境或 Docker 容器中本地运行。示例应用程序还包括用于在 Amazon EC2 实例上构建模型的模板和脚本。
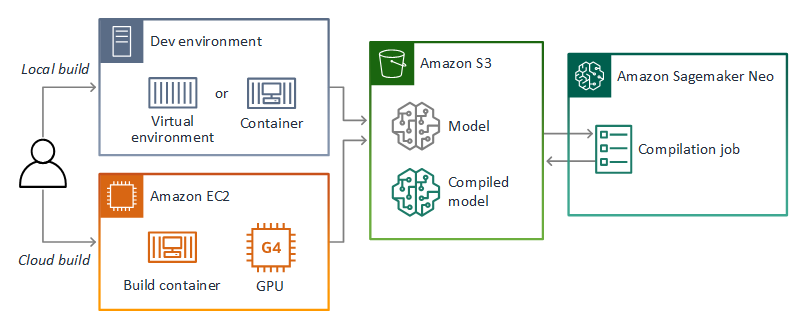
AWS Panorama 使用 A SageMaker I Neo 编译模型以在 AWS Panorama 设备上使用。对于每个框架,使用 SageMaker AI Neo 支持的格式,并将模型打包到.tar.gz存档中。
有关更多信息,请参阅 Amazon A SageMaker I 开发者指南中的使用 Neo 编译和部署模型。
打包模型
模型包由描述符、包配置和模型存档组成。与应用程序映像包一样,程序包配置会告知 AWS Panorama 服务模型和描述符在 Amazon S3 中的存储位置。
例 packages/123456789012-SQUEEZENET_PYTORCH-1.0/descriptor.json
{ "mlModelDescriptor": { "envelopeVersion": "2021-01-01", "framework": "PYTORCH", "frameworkVersion": "1.8", "precisionMode": "FP16", "inputs": [ { "name": "data", "shape": [ 1, 3, 224, 224 ] } ] } }
注意
仅指定框架版本的主要版本和次要版本。有关支持的框架 PyTorch、Apache MXNet TensorFlow 版本和版本列表,请参阅支持的框架。
要导入模型,请使用 AWS Panorama 应用程序 CLI import-raw-model 命令。如果对模型或其描述符进行任何更改,则必须重新运行此命令以更新应用程序的资产。有关更多信息,请参阅 更改计算机视觉模型。
有关描述符文件的 JSON 架构,请参阅 assetDescriptor.schema.json
训练模型
训练模型时,请使用目标环境或与目标环境非常相似的测试环境中的图像。请考虑以下可能影响模型性能的因素:
-
照明 – 拍摄对象反射的光量决定了模型必须分析的细节量。使用光线充足的拍摄对象图像训练的模型在弱光或背光环境中可能无法正常工作。
-
分辨率 – 模型的输入大小通常固定在 224 到 512 像素宽之间的分辨率,呈方形纵横比。在将一帧视频传递给模型之前,可以将其缩小或裁剪以适应所需的尺寸。
-
图像失真 – 相机的焦距和镜头形状会导致图像在远离画面中心的地方出现失真。相机的位置也决定了拍摄对象的哪些特征清晰可见。例如,带有广角镜头的高架相机在拍摄对象位于画面中心时会显示拍摄对象的顶部,而当拍摄对象远离中心时会显示拍摄对象侧面的倾斜视图。
要解决这些问题,可以在将图像发送给模型前对其进行预处理,并在反映现实环境中差异的更广泛的图像上训练模型。如果一个模型需要在照明条件下使用各种相机进行操作,则需要更多数据进行训练。除了收集更多图像之外,您还可以通过创建倾斜或具有不同光照的现有图像的变体来获取更多训练数据。
