本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
处理阶段
Amazon Textract 将 PDF 文件内容提取为不能由下游应用程序直接使用的字符串(例如,通过汇总数字生成统计数据)。需要正确识别和转换数据值,因为下游应用程序可以更轻松地使用它们(例如,将成本趋势绘制为时间序列)。要实现 PDF 文件处理,必须通过 Amazon Textract 对每种新 PDF 文件类型中的一个 PDF 文件进行一次性处理,然后生成一个 JS Template ON 格式的文件。
在中启动该 AWS Lambda 函数后摄取阶段,它将按下图所示的步骤运行。
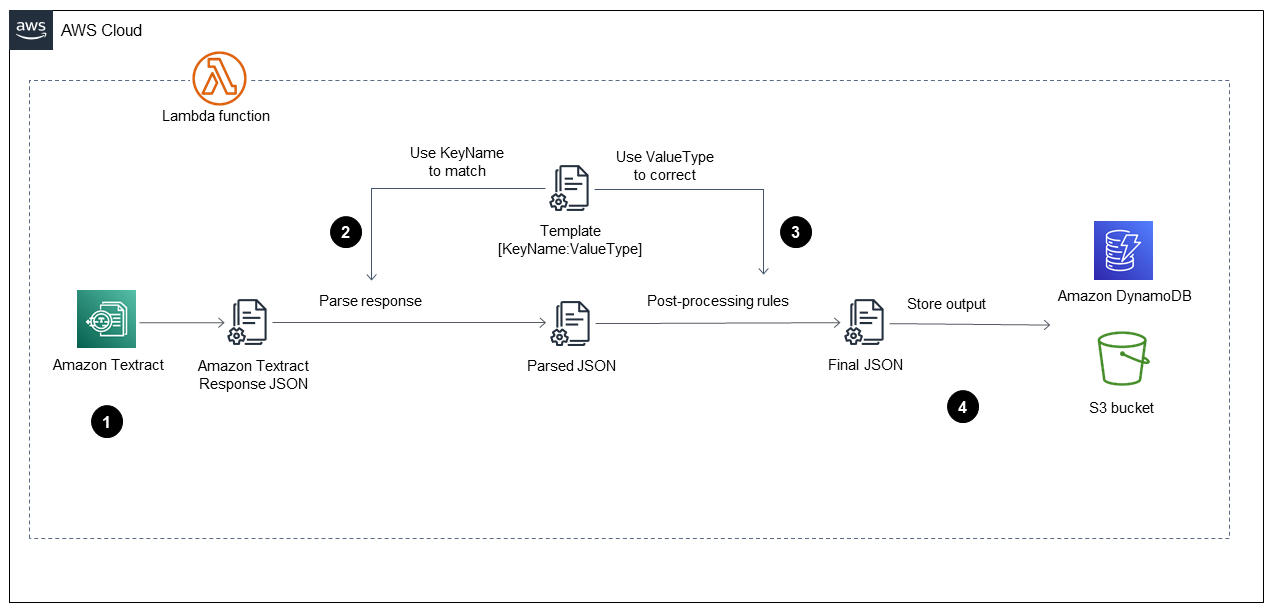
该图显示了实现以下步骤的 Lambda 函数:
-
调用 Amazon Textract 处理 PDF 文件,提取内容并返回 JSON 格式的文件。
-
获取 JSON 文件并使用预定义的
TemplateJSON 文件解析表单和表格,该文件对每个字段都有正确的键名和值类型。此过程提供已解析的 JSON 文件。 -
应用后处理规则并使用
TemplateJSON 文件更正已解析的 JSON 文件中的每个值。这将生成FinalJSON 文件。预定义的TemplateJSON 文件可以存储在 S3 存储桶中。 -
在 Amazon DynamoDB 中将 JSO
FinalN 文件存储为每个 PDF 文件的一条记录,此外还在 S3 输出存储桶中为每个 PDF 文件存储一个 JSON 文件。
有关使用 Amazon Textract 自动从 PDF 文件中提取内容并将其处理成干净输出 step-by-step的工作流程,请参阅规范指南网站上的 “使用 Amazon Textract 自动从 PDF 文件中提取内容 AWS ” 模式。此模式使用模板匹配技术正确识别必填字段、密钥名称和表,然后对每种数据类型进行后期处理更正。
处理阶段的最佳实践
使用以下四种最佳实践来确保成功完成处理阶段:
-
为您要处理的每种 PDF 文件类型创建一个模板 JSON 文件。您可以将这些不同的模板 JSON 文件存储在 Lambda 函数调用的 S3 存储桶中。如果您想在一个 Lambda 函数中处理不同的 PDF 文件类型,则应为每种 PDF 文件类型使用唯一标识符(例如,S3 存储桶中 PDF 文件类型的文件夹名称)。调用 Lambda 函数后,它会检索相应的模板 JSON 文件并对其进行处理。
-
设置一种机制来准确跟踪 Lambda 函数中每个步骤的状态。例如,您可以在 Amazon Textract 调
Success用之后、将最终 JSON 文件保存到亚马逊 DynamoDB 表或 PDF 文件保存到 S3 存储桶时添加状态。您还可以创建单独的 DynamoDB 表,以跟踪不同步骤中每个 PDF 文件的状态,从而了解流程。 -
批处理许多 PDF 文件时,通过自动重试失败的操作来管理限制和断开的连接。如果您的连接中断或超过了每秒最大交易量 (TPS),Amazon Textract 中可能会出现限制。有关自动重试失败操作的更多信息和步骤,请参阅 Amazon Tex tract 文档中的处理受限制的呼叫和断开的连接。
-
如果您的 PDF 文件包含多个页面,则可以使用异步操作来处理整个文件,也可以将 PDF 文件分解为单独的页面,使用同步操作处理每个页面,然后合并每个页面的结果。有关异步操作的完整代码实现,请参阅 Amazon Textract 文档中的检测和分析多页文档中的文本。有关使用同步操作的更多信息,请参阅 Amazon Textract 文档中的检测和分析单页文档中的文本。
