本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
数据使用者
在集中式目录使用数据创建器共享数据后,数据使用者使用这些数据 AWS Lake Formation。下图显示了数据湖中的两个数据使用者。
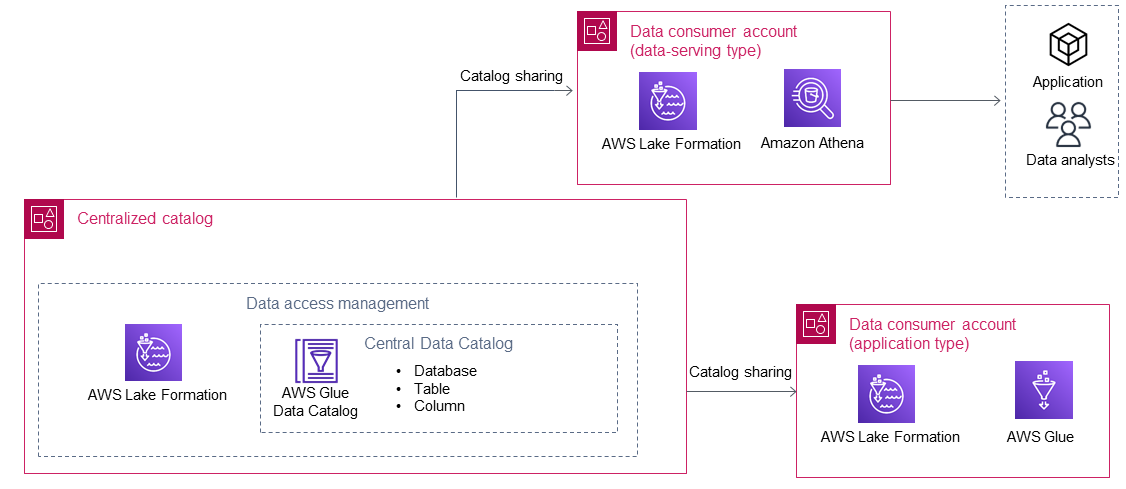
有两种类型的数据使用者:应用程序和数据服务。下表描述了这两种类型。
| 应用程序类型 |
应用程序数据使用者自己运行应用程序 AWS 账户。应用程序使用 AWS Identity and Access Management (IAM) 角色来访问来自数据生产者的共享数据,然后根据其逻辑对其进行处理。 通常,这种类型的数据使用者具有规范性的数据要求来满足应用程序的需求。 |
| 数据服务类型 |
提供数据服务的数据使用者通常适用于没有自己的 AWS 账户个人(例如数据分析师或数据科学家)和应用程序(例如商业智能应用程序)。 一个组织的数据湖中可以存在多个提供数据服务的数据使用者。例如,不同的业务部门可能会选择设置自己的数据服务使用者,以帮助用户使用来自数据湖的数据。这些数据使用者在其 AWS 账户 (例如,与之关联的 IAM 角色 AWS IAM Identity Center)中配置了自己的 IAM 角色主体,数据使用者账户中的最终用户使用这些角色主体通过 AWS 服务(例如 A mazon Athena)访问共享数据。 通常,这种类型的数据使用者具有广泛且不断增长的数据需求。 |
AWS Lake Formation 是数据使用者用于跨账户数据共享和访问集中式目录的最重要的 AWS 服务。集中式目录共享数据库后,共享资源将在 Lake Formation 中的数据使用者帐户中可用。然后,如果需要,可以向数据使用者账户中的本地 IAM 委托人授予数据访问权限,并获得数据创建者的许可。然后,与 Lake Formation 集成的 AWS 服务(例如 Amazon Athen AWS Glue a 和)即可使用共享的数据。您可以使用以下 AWS 服务访问数据使用者账户中的共享数据:
-
Amazon Athena 是一项交互式查询服务,可帮助使用标准 SQL 直接分析亚马逊简单存储服务 (Amazon S3) 中的数据。有关 Athena 和 Lake Formation 的更多信息,请参阅亚马逊 Athena 文档中的 Athena 如何访问在 Lake Formation 注册的数据。
-
Amazon Redshift Spectrum 可帮助您有效地查询和检索亚马逊 S3 中的文件中的结构化和半结构化数据,而无需将数据加载到亚马逊 Redshift 表中。有关 Redshift Spectrum 和 Lake Formation 的更多信息,请参阅亚马逊 Redshift 文档中的将 Redshift Spectrum 与 Lake Formation 配合使用。
-
AWS Glue是一项完全托管的提取、转换和加载 (ETL) 服务,它可以简单且经济高效地对数据进行分类、清理、丰富数据,并在不同的数据存储和数据流之间可靠地移动数据。如果 AWS Glue ETL 作业的关联 IAM 角色具有所需的访问权限,则可以访问由 Lake Formation 管理的数据湖数据。
-
亚马逊 EMR 可帮助运行大数据框架(例如 Apache Hadoop 和 Apach
e Spark )来处理和分析大量数据。有关亚马逊 EMR 和 Lake Formation 的更多信息,请参阅亚马逊 EMR 文档中的将亚马逊 EMR 与 Lake Formation 集成。 -
Amazon QuickSight 是一项可扩展、无服务器、可嵌入且由机器学习 (ML) 提供支持的商业智能服务,您可以使用它来分析和可视化来自数据湖的数据。有关 QuickSight 和 Lake Formation 的更多信息,请参阅 QuickSight 文档中的通过 Lake Formation 授权连接。
-
Amazon SageMaker AI Data Wrangler(Data Wrangler)缩短了为机器学习汇总和准备数据所需的时间。有关 Data Wrangler 和 Lake For mation 的更多信息,请参阅亚马逊 AI 文档中的使用亚马逊 A SageMaker I Data Wrangler 准备机器学习数据。 SageMaker
