本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
在上创建可用于生产的机器学习管道 AWS
Josiah Davis、Verdi March、Yin Song、Baichuan Sun、Chen Wu 和 Wei Yih Yap,Amazon Web Services (AWS)
2021 年 1 月(文档历史记录)
机器学习 (ML) 项目需要大量的多阶段工作,包括建模、实施和生产,以实现业务价值和解决现实问题。每个步骤都有许多备选方案和自定义选项可供选择,这使得在资源和预算的限制下为生产准备机器学习模型变得越来越困难。过去的几年在 Amazon Web Services (AWS),我们的数据科学团队与不同行业部门就机器学习计划进行了合作。我们确定了许多 AWS 客户共同面临的痛点,这些痛点源于组织问题和技术挑战,并且我们开发了一种交付生产就绪型机器学习解决方案的最佳方法。
本指南适用于参与机器学习工作流实施的数据科学家和机器学习工程师。它描述了我们交付生产就绪机器学习工作流的方法。本指南讨论了如何从以交互方式运行机器学习模型(开发期间)过渡到将其作为机器学习用例工作流的一部分(生产期间)进行部署。为此,我们还开发了一组示例模板(参见 ML Max 项目
概览
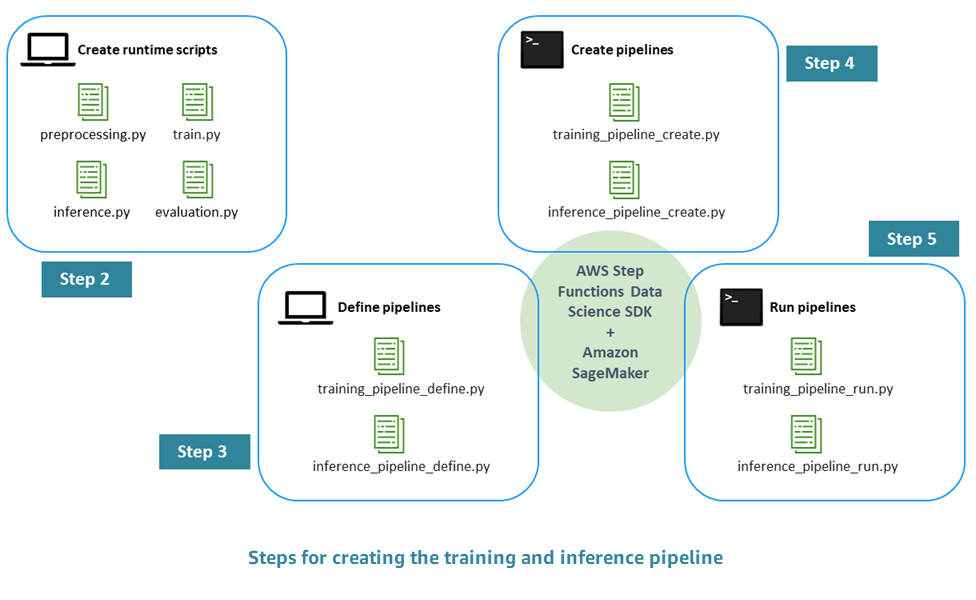
创建生产就绪机器学习工作流的流程包括以下步骤:
-
第 1 步。执行 EDA 并开发初始模型:数据科学家在 Amazon Simple Storage Service (Amazon S3) 中提供原始数据,执行探索性数据分析 (EDA),开发初始机器学习模型,并评估其推理性能。您可以通过 Jupyter 笔记本以交互方式进行这些活动。
-
第 2 步。创建运行时脚本 — 您将模型与运行时 Python 脚本集成,以便可以由机器学习框架(在本例中为 Amazon A SageMaker I)对其进行管理和配置。这是从独立模型的交互式开发转向生产的第一步。具体而言,您可以分别定义预处理、评估、训练和推理的逻辑。
-
第 3 步。定义工作流:您可以为工作流的每个步骤定义输入和输出占位符。这些值的具体值将在稍后运行时提供(第 5 步)。您将重点放在用于训练、推理、交叉验证和回测的工作流上。
-
第 4 步。创建管道 — 您可以使用以自动(几乎一键式)的方式创建底层基础架构,包括 AWS Step Functions 状态机实例。 AWS CloudFormation
-
第 5 步。运行工作流:运行第 4 步中定义的工作流。您还可以准备元数据和数据或数据位置,以填充您在第 3 步 中定义的输入/输出占位符的具体值。这包括第 2 步中定义的运行时脚本以及模型超参数。
-
第 6 步。扩展工作流:您可以实施持续集成和持续部署 (CI/CD) 流程、自动再训练、计划推理以及类似的工作流扩展。
下图阐明此过程的主要步骤。