本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
在 Amazon Aurora PostgreSQL 中模拟 Oracle PL/SQL 关联数组和适用于 PostgreSQL 的亚马逊 RDS
Rajkumar Raghuwanshi、Bhanu Ganesh Gudivada 和 Amazon Web Services 的 Sachin Khanna
摘要
此模式描述了如何在 Amazon Aurora PostgreSQL 和 Amazon RDS for PostgreSQL 环境中模拟索引位置为
在迁移 Oracle 数据库时,我们提供了 PostgreSQL 替代方案,而不是aws_oracle_ext使用函数来处理空索引位置。这种模式使用额外的列来存储索引位置,它保持了 Oracle 对稀疏数组的处理,同时整合了原生 PostgreSQL 功能。
Oracle
在 Oracle 中,可以将集合初始化为空,然后使用EXTEND集合方法进行填充,该方法将NULL元素追加到数组中。使用索引的 PL/SQL 关联数组时PLS_INTEGER,该EXTEND方法按顺序添加NULL元素,但也可以在非序列索引位置初始化元素。任何未显式初始化的索引位置均为空。
这种灵活性允许稀疏数组结构,其中元素可以填充到任意位置。使用 with FIRST 和 LAST bounds 遍历集合时,仅处理初始化的元素(NULL无论是否具有定义的值),而跳过空位置。FOR LOOP
PostgreSQL(亚马逊 Aurora 和亚马逊 RDS)
PostgreSQL 对空值的处理方式与值的处理方式不同。NULL它将空值存储为使用一个字节存储空间的不同实体。当数组的值为空时,PostgreSQL 会像非空值一样分配顺序索引位置。但是顺序索引需要额外的处理,因为系统必须遍历所有索引位置,包括空位置。这使得传统的数组创建对于稀疏数据集来说效率低下。
AWS Schema Conversion Tool
AWS Schema Conversion Tool (AWS SCT) 通常使用aws_oracle_ext函数处理 Oracle-to-PostgreSQL迁移。在这种模式中,我们提出了一种使用原生 PostgreSQL 功能的替代方法,该方法将 PostgreSQL 数组类型与用于存储索引位置的附加列相结合。然后,系统可以仅使用索引列遍历数组。
先决条件和限制
先决条件
活跃 AWS 账户的.
具有管理员权限的 AWS Identity and Access Management (IAM) 用户。
与 Amazon RDS 或 Aurora PostgreSQL 兼容的实例。
对关系数据库有基本的了解。
限制
有些 AWS 服务 并非全部可用 AWS 区域。有关区域可用性,请参阅AWS 服务 按地区划分
。有关特定终端节点,请参阅服务终端节点和配额页面,然后选择服务的链接。
产品版本
此模式已在以下版本中进行了测试:
亚马逊 Aurora PostgreSQL 13.3
适用于 PostgreSQL 的亚马逊 RDS 13.3
AWS SCT 1.0.674
甲骨文 12c EE 12.2
架构
源技术堆栈
本地 Oracle 数据库
目标技术堆栈
Amazon Aurora PostgreSQL
Amazon RDS for PostgreSQL
目标架构
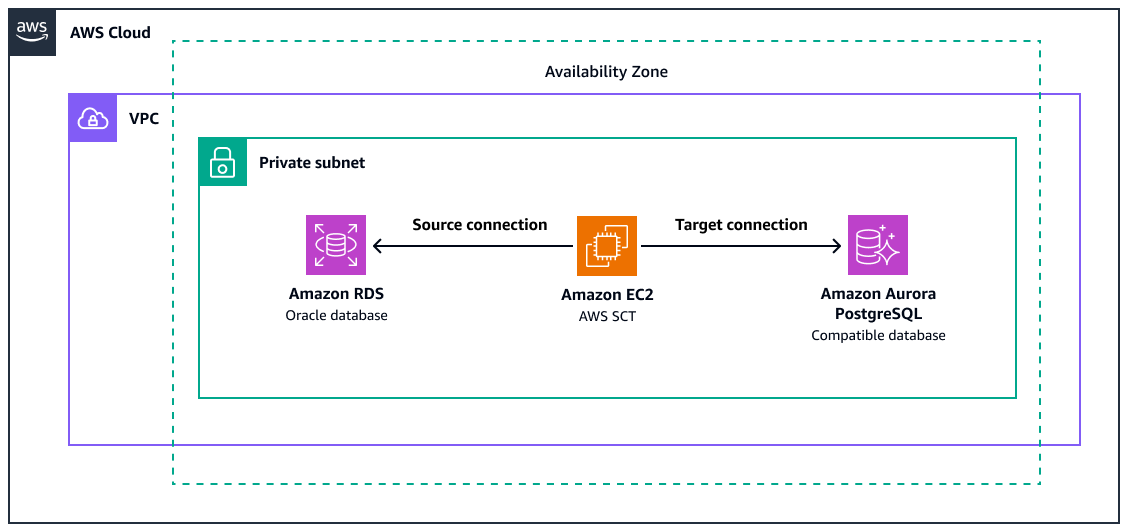
此图显示以下内容:
来源 Amazon RDS for Oracle 数据库实例
一个带有的 Amazon EC2 实例, AWS SCT 用于将 Oracle 函数转换为 PostgreSQL 的等效函数
与亚马逊 Aurora PostgreSQL 兼容的目标数据库
工具
Amazon Web Services
Amazon Aurora 是与 MySQL 和 PostgreSQL 兼容的完全托管式的云端关系数据库引擎。
Amazon Aurora PostgreSQL 兼容版是一个完全托管的、与 ACID 兼容的关系数据库引擎,可帮助您建立、运行和扩缩 PostgreSQL 部署。
亚马逊弹性计算云 (Amazon EC2) 在中提供可扩展的计算容量 AWS 云。您可以根据需要启动任意数量的虚拟服务器,并快速扩展或缩减它们。
Amazon Relational Database Service(Amazon RDS)可帮助您在中设置、操作和扩展关系数据库 AWS 云。
适用于 Oracle 的 Amazon Relational Database Service(Amazon RDS)可帮助您在中设置、操作和扩展 Oracle 关系数据库 AWS 云。
适用于 PostgreSQL 的亚马逊关系数据库服务(Amazon RDS)可帮助您在中设置、操作和扩展 PostgreSQL 关系数据库。 AWS 云
AWS Schema Conversion Tool (AWS SCT) 通过自动将源数据库架构和大部分自定义代码转换为与目标数据库兼容的格式来支持异构数据库迁移。
其他工具
Oracle SQL Developer
是一个集成的开发环境,可简化传统部署和基于云的部署中 Oracle 数据库的开发和管理。 pgAdmin
是一种适用于 PostgreSQL 的开源管理工具。它提供了一个图形界面,可帮助您创建、维护和使用数据库对象。在这种模式下,pgadmin 连接到 RDS for PostgreSQL 数据库实例并查询数据。或者,你可以使用 psql 命令行客户端。
最佳实践
测试数据集边界和边缘场景。
考虑对 out-of-bounds索引条件实现错误处理。
优化查询以避免扫描稀疏的数据集。
操作说明
| Task | 描述 | 所需技能 |
|---|---|---|
在 Oracle 中创建源 PL/SQL 块。 | 在 Oracle 中创建使用以下关联数组的源 PL/SQL 块:
| 数据库管理员 |
运行方 PL/SQL 块。 | 在 Oracle 中运行源代码 PL/SQL 块。如果关联数组的索引值之间存在间隙,则不会在这些间隙中存储任何数据。这允许 Oracle 循环仅遍历索引位置。 | 数据库管理员 |
检查输出。 | 五个元素以非连续的间隔插入到数组 (
| 数据库管理员 |
| Task | 描述 | 所需技能 |
|---|---|---|
在 PostgreSQL 中创建一个目标 PL/pgSQL 区块。 | 在 PostgreSQL 中创建一个使用以下关联数组的目标 PL/pgSQL 块:
| 数据库管理员 |
运行方 PL/pgSQL 块。 | 在 PostgreSQL 中运行目标 PL/pgSQL 区块。如果关联数组的索引值之间存在间隙,则不会在这些间隙中存储任何数据。这允许 Oracle 循环仅遍历索引位置。 | 数据库管理员 |
检查输出。 | 数组长度大于 5,因为
| 数据库管理员 |
| Task | 描述 | 所需技能 |
|---|---|---|
使用数组和用户定义类型创建目标 PL/pgSQL 块。 | 为了优化性能并匹配 Oracle 的功能,我们可以创建一个用户定义的类型来存储索引位置及其对应的数据。这种方法通过保持索引和值之间的直接关联来减少不必要的迭代。
| 数据库管理员 |
运行方 PL/pgSQL 块。 | 运行目标 PL/pgSQL 方块。如果关联数组的索引值之间存在间隙,则不会在这些间隙中存储任何数据。这允许 Oracle 循环仅遍历索引位置。 | 数据库管理员 |
检查输出。 | 如以下输出所示,用户定义的类型仅存储填充的数据元素,这意味着数组长度与值的数量相匹配。因此,
| 数据库管理员 |
相关的资源
AWS 文档
其他文档
