从 2025 年 11 月 1 日起,Amazon Redshift 将不再支持创建新的 Python UDF。如果您想要使用 Python UDF,请在该日期之前创建 UDF。现有的 Python UDF 将继续正常运行。有关更多信息,请参阅博客文章
Amazon Redshift Serverless 数据仓库入门
如果您是首次接触 Amazon Redshift Serverless 的用户,我们建议您先阅读以下部分,以帮助您开始使用 Amazon Redshift Serverless。Amazon Redshift Serverless 的基本流程是创建无服务器资源,连接到 Amazon Redshift Serverless,加载示例数据,然后对数据运行查询。在本指南中,您可以选择从 Amazon Redshift Serverless 或 Amazon S3 存储桶加载示例数据。在 Amazon Redshift 文档中,会使用示例数据来演示功能。要开始使用 Amazon Redshift 预置数据仓库,请参阅 Amazon Redshift 预置数据仓库入门。
注册 AWS
如果您还没有 AWS 账户,请先注册一个。如果您已有账户,则可以跳过此先决条件步骤,并使用您已有的账户。
按照屏幕上的说明操作。
当您注册 AWS 账户时,系统会创建一个 AWS 账户根用户。根用户有权访问该账户中的所有 AWS 服务和资源。作为安全最佳实践,请为管理用户分配管理访问权限,并且只使用根用户执行需要根用户访问权限的任务。
使用 Amazon Redshift Serverless 创建数据仓库
首次登录 Amazon Redshift Serverless 控制台时,系统会提示您访问入门体验,您可以通过该体验创建和管理无服务器资源。在本指南中,您将使用 Amazon Redshift Serverless 的默认设置创建无服务器资源。
要更精细地控制您的设置,请选择 Customize settings(自定义设置)。
注意
Redshift Serverless 需要一个 Amazon VPC,且该 VPC 有三个子网位于三个不同的可用区中。Redshift Serverless 还需要至少 3 个可用 IP 地址。在继续操作之前,请确保您用于 Redshift Serverless 的 Amazon VPC 有三个子网位于三个不同的可用区中,并且至少有 3 个可用 IP 地址。有关在 Amazon VPC 中创建子网的更多信息,请参阅《Amazon Virtual Private Cloud 用户指南》中的创建子网。有关 Amazon VPC 中的 IP 地址的更多信息,请参阅为 VPC 和子网分配 IP 地址。
要使用原定设置进行配置,请执行以下操作:
登录到 AWS Management Console并打开 Amazon Redshift 控制台,网址:https://console.aws.amazon.com/redshiftv2/
。 选择试用 Redshift Serverless 免费试用版。
-
在 Configuration(配置)下,选择 Use default settings(使用原定设置)。Amazon Redshift Serverless 将创建一个默认命名空间,其中包含与该命名空间关联的默认工作组。选择 Save configuration。
注意
命名空间是数据库对象和用户的集合。命名空间将您在 Redshift Serverless 中使用的所有资源组合在一起,例如架构、表、用户、数据共享和快照。
工作组是计算资源的集合。工作组存放 Redshift Serverless 运行计算任务所用的计算资源。
以下屏幕截图显示 Amazon Redshift Serverless 的默认设置。
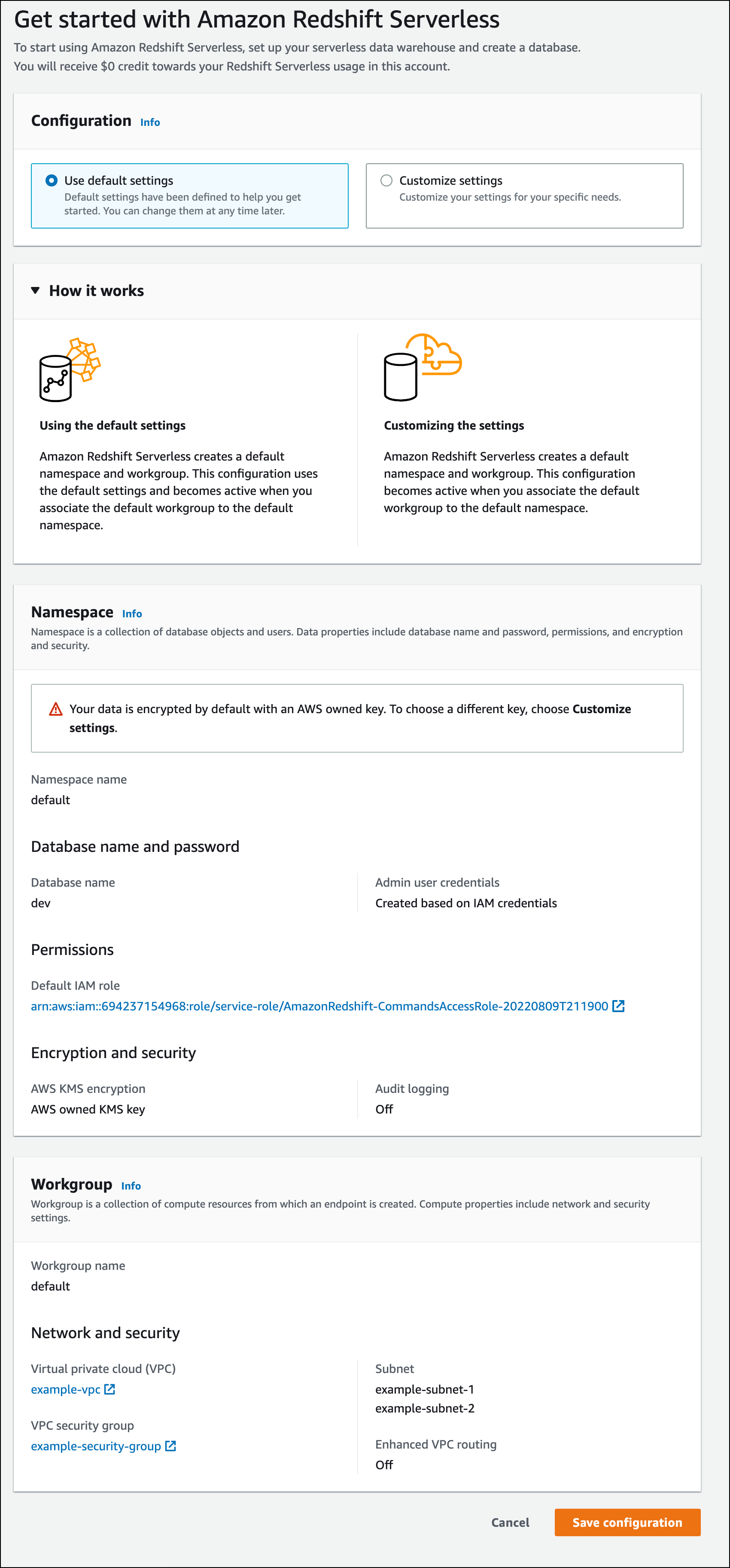
-
设置完成后,选择 Continue(继续)以转到 Serverless dashboard(Serverless 控制面板)。您可以看到无服务器工作组和命名空间可用。
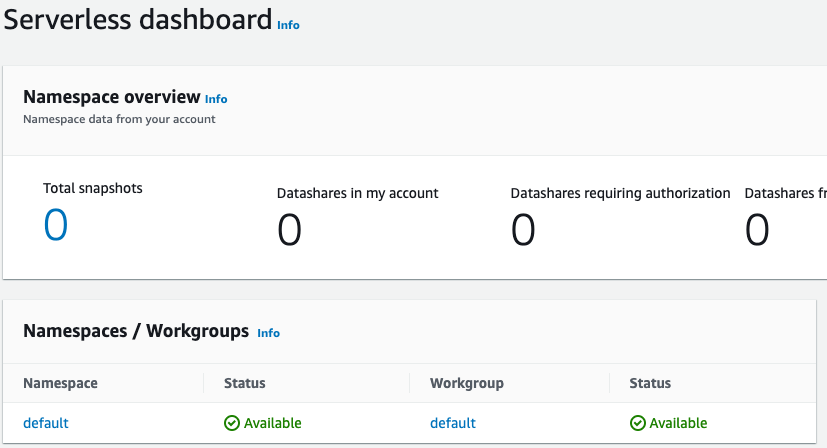
注意
如果 Redshift Serverless 未能成功创建工作组,您可以执行以下操作:
解决 Redshift Serverless 报告的任何错误,例如 Amazon VPC 中的子网过少。
通过在 Redshift Serverless 控制面板中选择 default-namespace,然后选择操作、删除命名空间,来删除命名空间。删除命名空间需要几分钟时间。
再次打开 Redshift Serverless 控制台时,会出现欢迎屏幕。
加载示例数据
现在,使用 Amazon Redshift Serverless 设置了数据仓库之后,您可以使用 Amazon Redshift 查询编辑器 v2 来加载示例数据。
-
要从 Amazon Redshift Serverless 控制台启动查询编辑器 v2,请选择查询数据。当您从 Amazon Redshift Serverless 控制台调用查询编辑器 v2 时,将打开一个新的浏览器选项卡,其中包含查询编辑器。查询编辑器 v2 将从客户端计算机连接到 Amazon Redshift Serverless 环境。
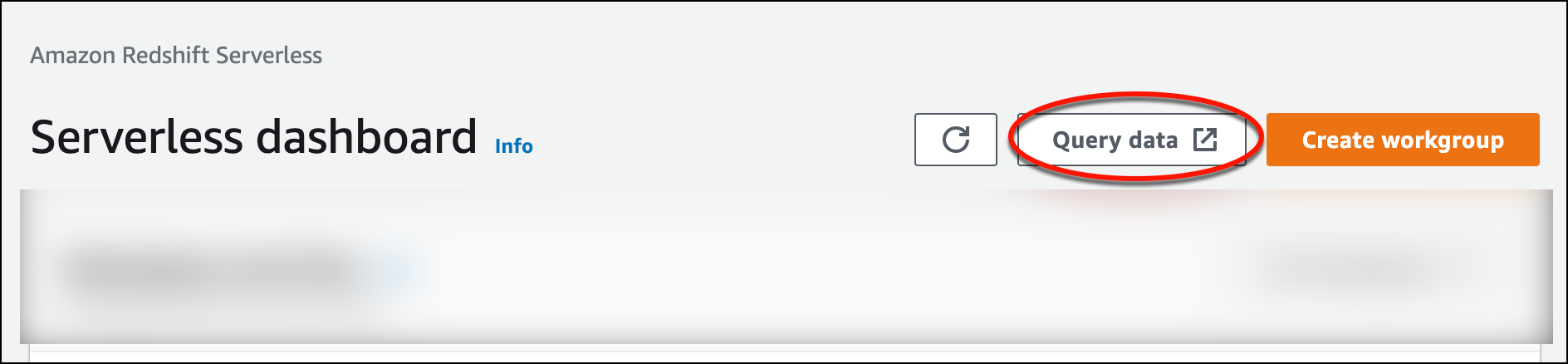
-
对于本指南,您将使用您的 AWS 管理员账户和默认的 AWS KMS key。有关配置查询编辑器 v2 的信息,包括需要哪些权限,请参阅《Amazon Redshift 管理指南》中的配置您的 AWS 账户。有关将 Amazon Redshift 配置为使用客户自主管理型密钥或更改 Amazon Redshift 使用的 KMS 密钥的信息,请参阅更改命名空间的 AWS KMS 密钥。
-
要连接到工作组,请在树视图面板中选择工作组名称。
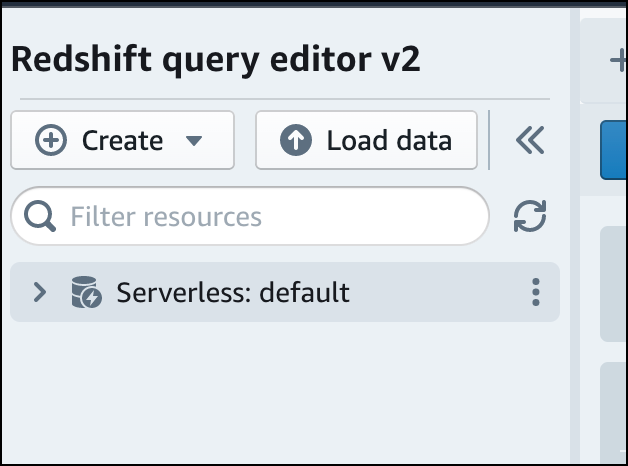
-
在查询编辑器 v2 中首次连接到新工作组时,必须选择连接到该工作组所用的身份验证类型。在本指南中,选择联合用户,然后选择创建连接。
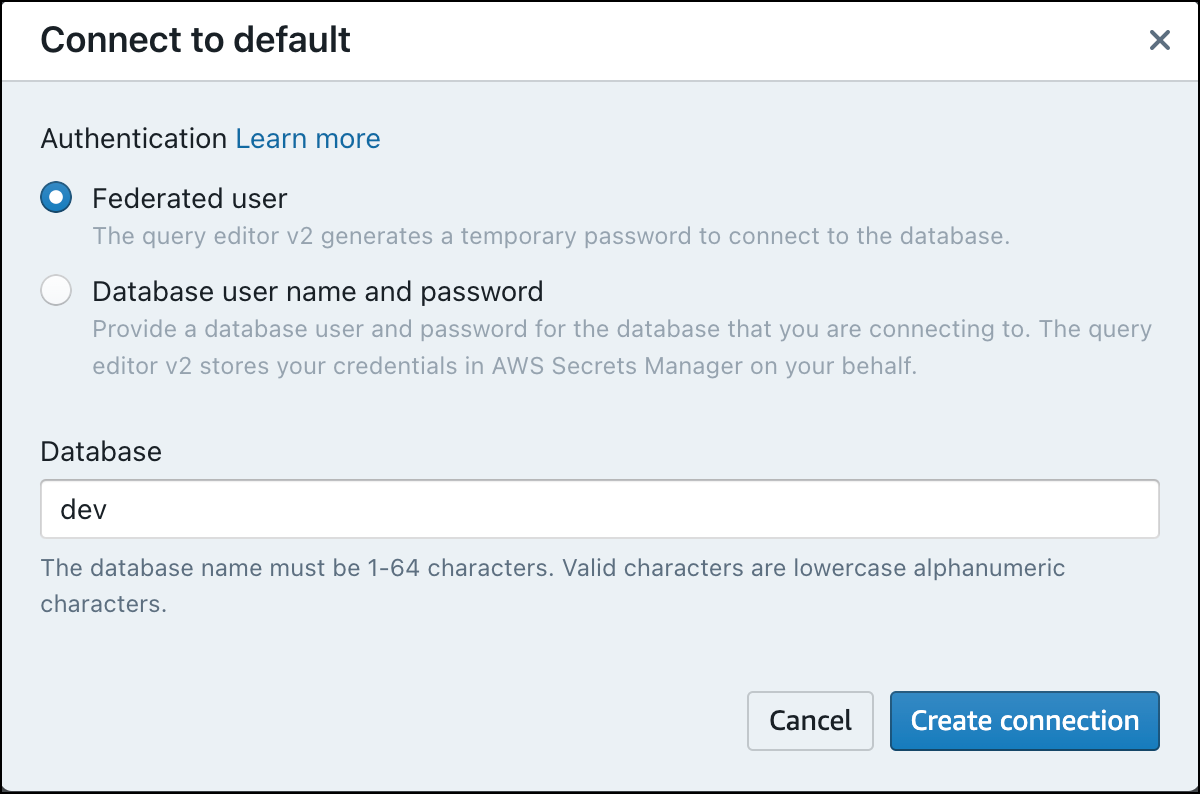
连接之后,您可以选择从 Amazon Redshift Serverless 或从 Amazon S3 存储桶加载示例数据。
-
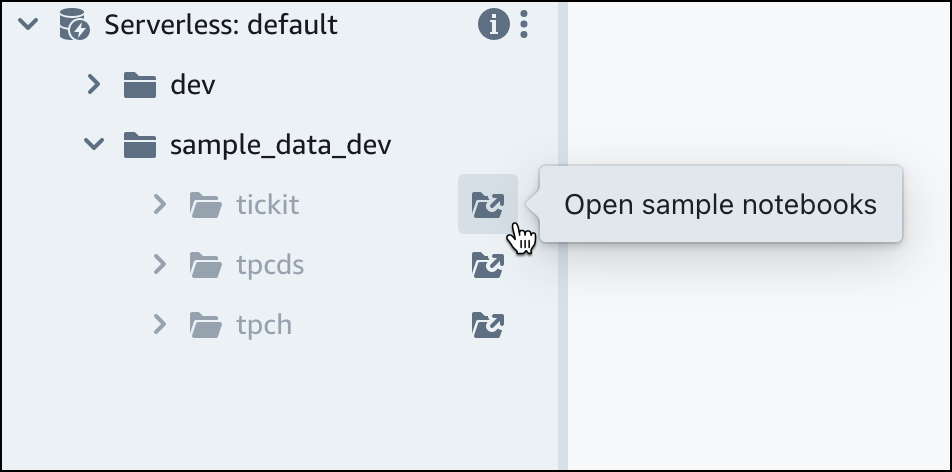
在 Amazon Redshift Serverless 原定设置工作组下,展开 sample_data_dev 数据库。有三个示例架构对应于三个示例数据集,您可以将这些示例数据集加载到 Amazon Redshift Serverless 数据库中。选择要加载的示例数据集,然后选择打开示例笔记本。
注意
SQL 笔记本是 SQL 和 Markdown 单元格的容器。您可以使用笔记本在单个文档中组织、注释及共享多个 SQL 命令。
-
首次加载数据时,查询编辑器 v2 将提示您创建示例数据库。选择创建。

运行示例查询
设置 Amazon Redshift Serverless 之后,您可以开始在 Amazon Redshift Serverless 中使用示例数据集。Amazon Redshift Serverless 自动加载示例数据集,例如 tickit 数据集,然后您便立即可以查询数据。
-
Amazon Redshift Serverless 完成示例数据的加载后,所有示例查询都会加载到编辑器中。您可以选择运行全部来运行示例笔记本中的所有查询。
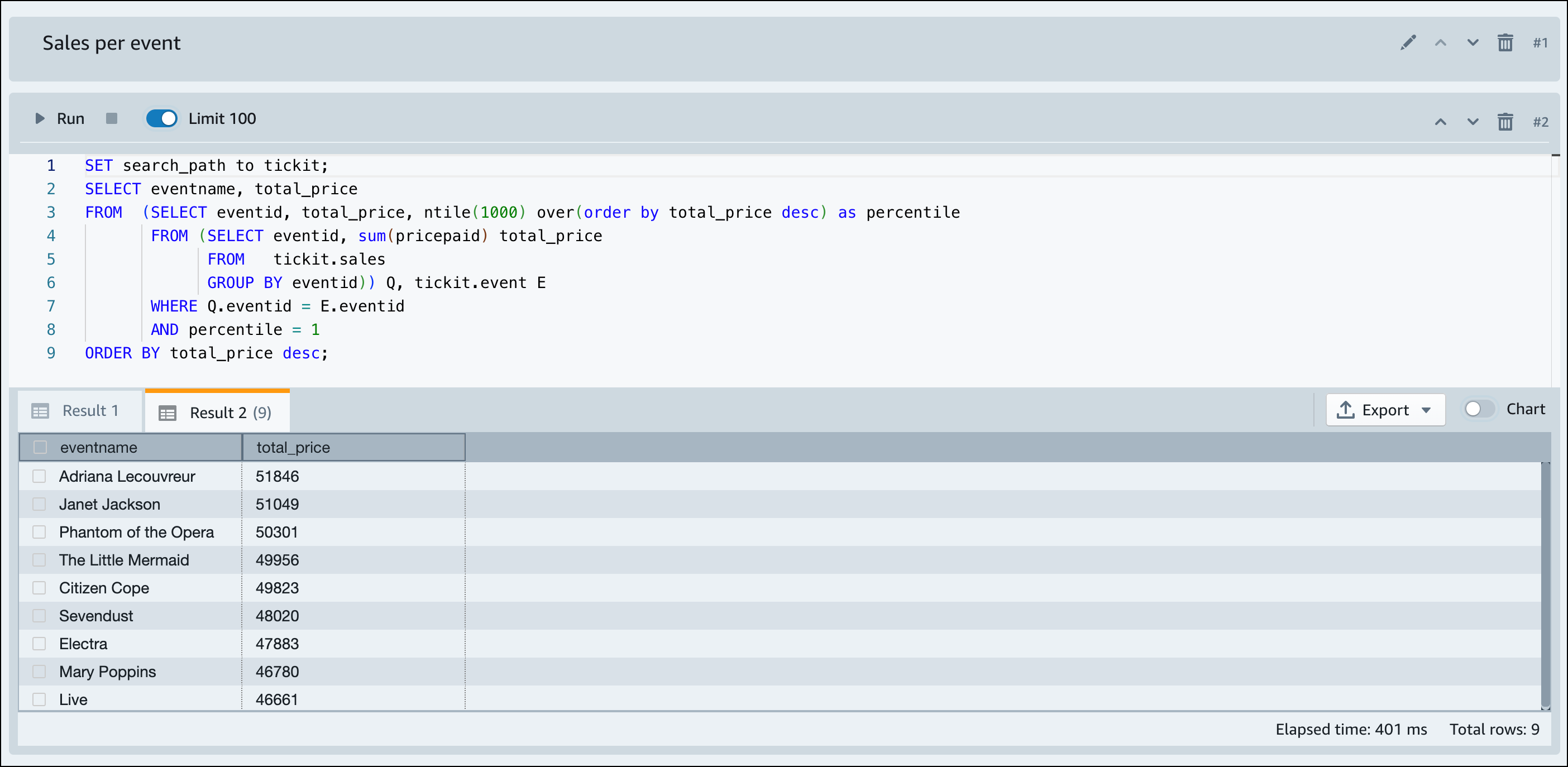
您也可以将结果导出为 JSON 或 CSV 文件,或者以图表格式查看结果。

您还可以从 Amazon S3 存储桶加载数据。要了解更多信息,请参阅从 Amazon S3 加载数据。
从 Amazon S3 加载数据
创建数据仓库后,您可以从 Amazon S3 加载数据。
此时,您拥有了一个名为 dev 的数据库。接下来,在该数据库中创建一些表,将数据上传到表,然后尝试执行查询。为方便起见,您上载的示例数据在 Amazon S3 桶中可用。
-
在从 Amazon S3 中加载数据之前,您必须先创建具有必要权限的 IAM 角色并将其附加到无服务器命名空间。为此,请返回 Redshift Serverless 控制台并选择命名空间配置。在导航菜单中,选择您的命名空间,然后选择安全和加密。然后选择管理 IAM 角色。
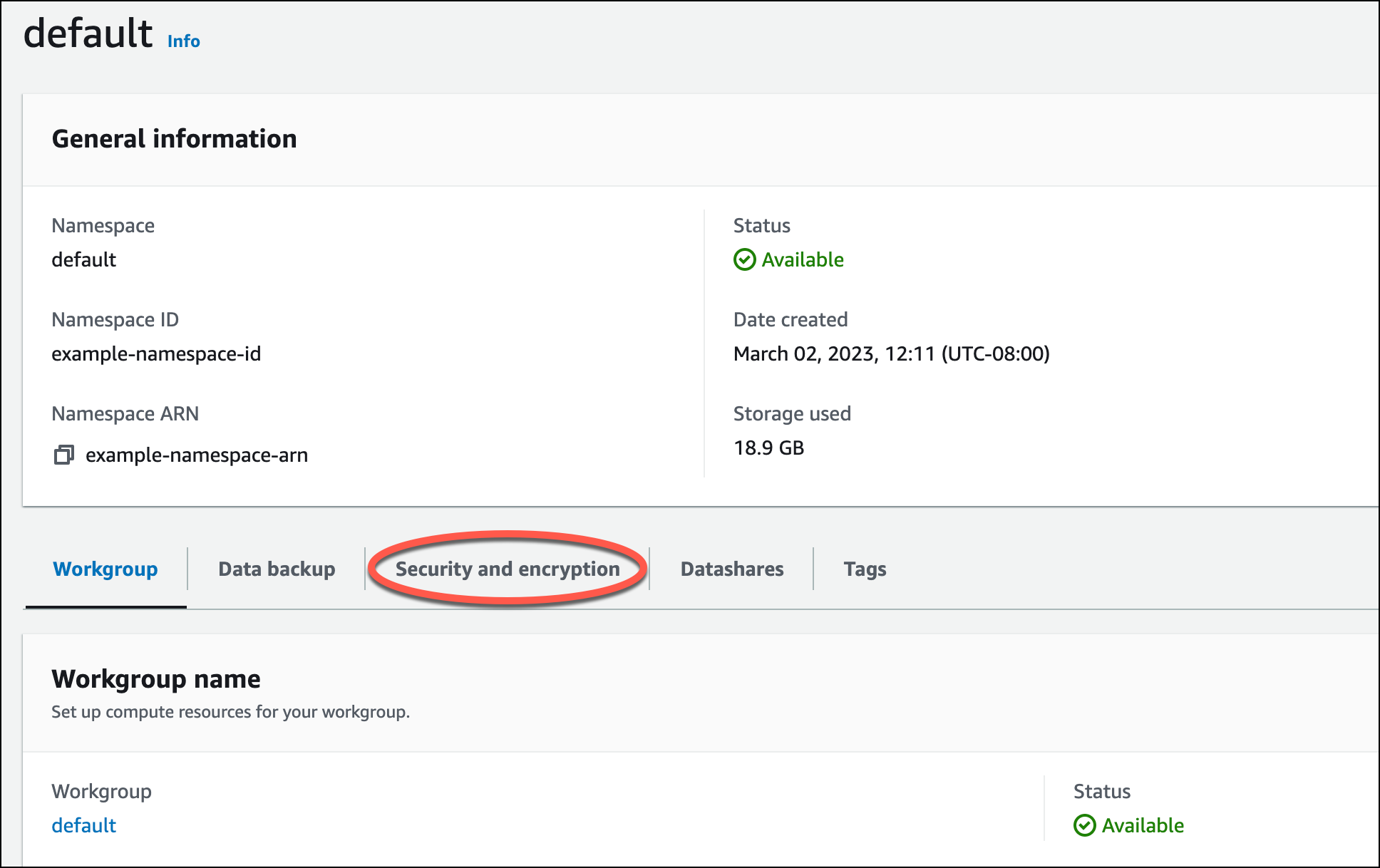
展开管理 IAM 角色菜单,然后选择创建 IAM 角色。
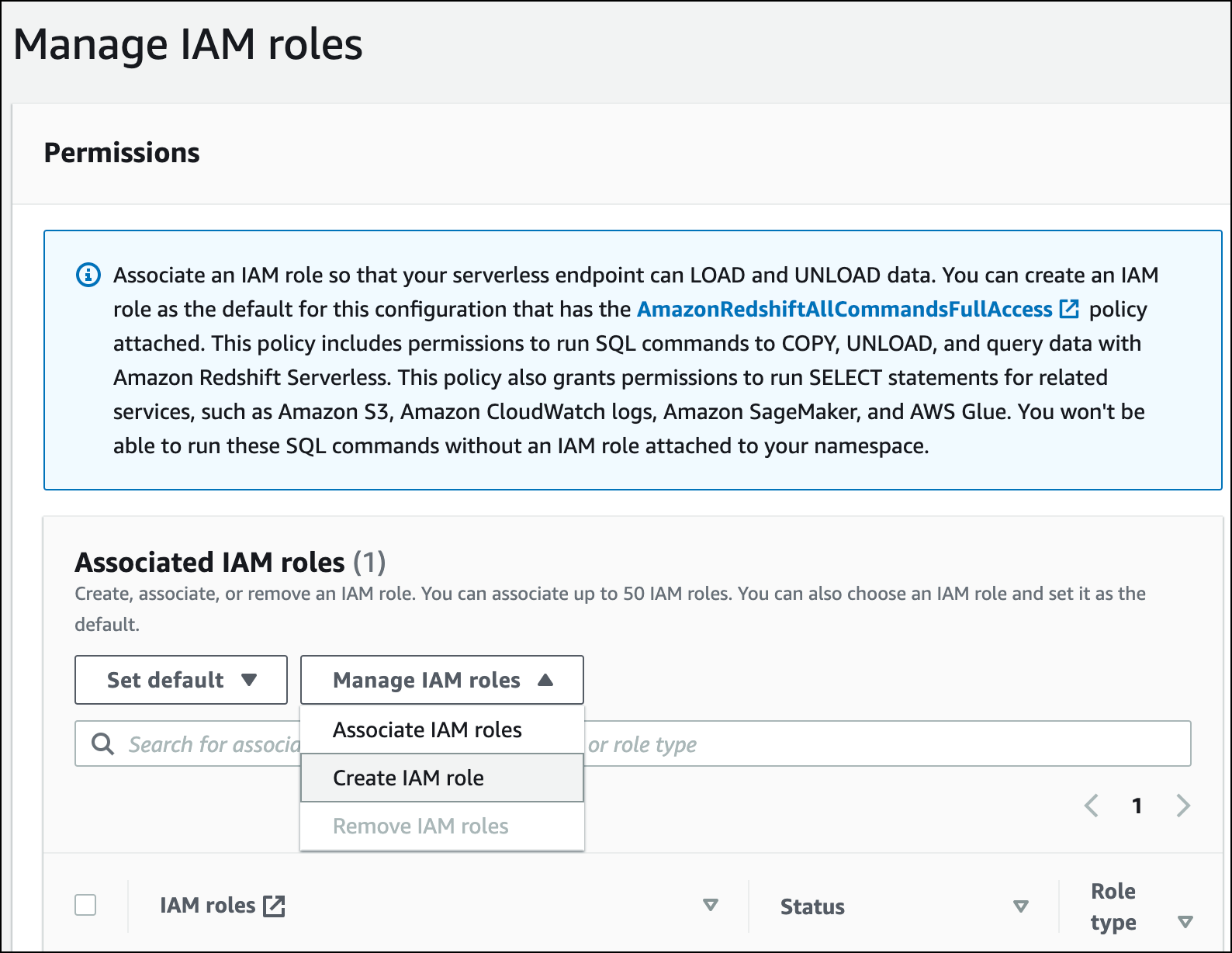
选择您要授予此角色的 S3 存储桶访问权限级别,然后选择创建 IAM 角色作为默认角色。

-
选择保存更改。现在您可从 Amazon S3 加载示例数据。
以下步骤使用公共 Amazon Redshift S3 存储桶中的数据,不过您可以使用自己的 S3 存储桶和 SQL 命令重复相同的步骤。
从 Amazon S3 加载示例数据
-
在查询编辑器 v2 中,选择
 “添加”,然后选择笔记本以创建新的 SQL 笔记本。
“添加”,然后选择笔记本以创建新的 SQL 笔记本。
-
切换到
dev数据库。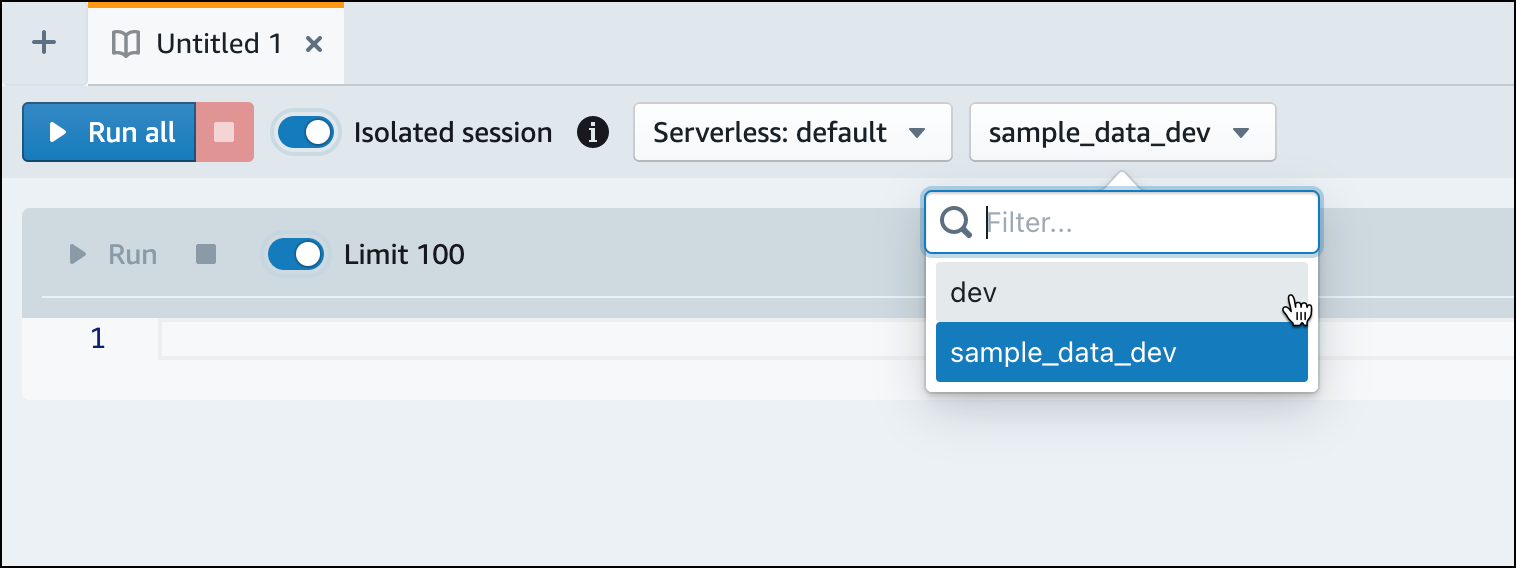
-
创建表。
如果您使用查询编辑器 v2,请复制并运行下列 create table 语句,以在
dev数据库中创建表。有关语法的更多信息,请参阅《Amazon Redshift 数据库开发人员指南》中的 CREATE TABLE。create table users( userid integer not null distkey sortkey, username char(8), firstname varchar(30), lastname varchar(30), city varchar(30), state char(2), email varchar(100), phone char(14), likesports boolean, liketheatre boolean, likeconcerts boolean, likejazz boolean, likeclassical boolean, likeopera boolean, likerock boolean, likevegas boolean, likebroadway boolean, likemusicals boolean); create table event( eventid integer not null distkey, venueid smallint not null, catid smallint not null, dateid smallint not null sortkey, eventname varchar(200), starttime timestamp); create table sales( salesid integer not null, listid integer not null distkey, sellerid integer not null, buyerid integer not null, eventid integer not null, dateid smallint not null sortkey, qtysold smallint not null, pricepaid decimal(8,2), commission decimal(8,2), saletime timestamp); -
使用查询编辑器 v2,在笔记本中创建一个新的 SQL 单元格。
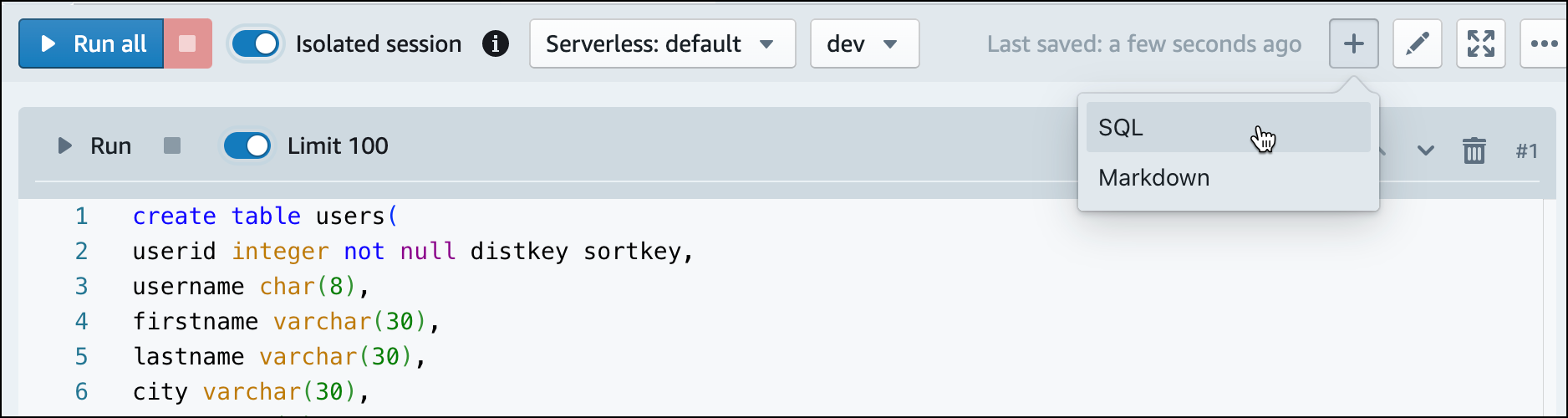
-
现在,您可以在查询编辑器 v2 中使用 COPY 命令,将大型数据集从 Amazon S3 或 Amazon DynamoDB 加载到 Amazon Redshift 中。有关 COPY 语法的更多信息,请参阅《Amazon Redshift 数据库开发人员指南中的 COPY。
您可以使用公共 S3 存储桶中的一些示例数据运行 COPY 命令。在查询编辑器 v2 中运行以下 SQL 命令。
COPY users FROM 's3://redshift-downloads/tickit/allusers_pipe.txt' DELIMITER '|' TIMEFORMAT 'YYYY-MM-DD HH:MI:SS' IGNOREHEADER 1 REGION 'us-east-1' IAM_ROLE default; COPY event FROM 's3://redshift-downloads/tickit/allevents_pipe.txt' DELIMITER '|' TIMEFORMAT 'YYYY-MM-DD HH:MI:SS' IGNOREHEADER 1 REGION 'us-east-1' IAM_ROLE default; COPY sales FROM 's3://redshift-downloads/tickit/sales_tab.txt' DELIMITER '\t' TIMEFORMAT 'MM/DD/YYYY HH:MI:SS' IGNOREHEADER 1 REGION 'us-east-1' IAM_ROLE default; -
加载数据后,在笔记本中创建另一个 SQL 单元格,然后尝试执行一些示例查询。有关使用 SELECT 命令的更多信息,请参阅《Amazon Redshift 开发人员指南》中的 SELECT。要了解示例数据的结构和架构,请使用查询编辑器 v2 进行探索。
-- Find top 10 buyers by quantity. SELECT firstname, lastname, total_quantity FROM (SELECT buyerid, sum(qtysold) total_quantity FROM sales GROUP BY buyerid ORDER BY total_quantity desc limit 10) Q, users WHERE Q.buyerid = userid ORDER BY Q.total_quantity desc; -- Find events in the 99.9 percentile in terms of all time gross sales. SELECT eventname, total_price FROM (SELECT eventid, total_price, ntile(1000) over(order by total_price desc) as percentile FROM (SELECT eventid, sum(pricepaid) total_price FROM sales GROUP BY eventid)) Q, event E WHERE Q.eventid = E.eventid AND percentile = 1 ORDER BY total_price desc;
现在,在加载了数据并运行了一些示例查询后,您可以探索 Amazon Redshift Serverless 的其他领域。请参阅以下列表,详细了解如何使用 Amazon Redshift Serverless。
-
您可以从 Amazon S3 存储桶加载数据。有关更多信息,请参阅从 Amazon S3 加载数据。
-
您可以使用查询编辑器 v2,从小于 5MB 的本地字符分隔文件中加载数据。有关更多信息,请参阅从本地文件加载数据。
-
您可以使用具有 JDBC 和 ODBC 驱动程序的第三方 SQL 工具连接到 Amazon Redshift Serverless。有关更多信息,请参阅连接到 Amazon Redshift Serverless。
-
还可使用 Amazon Redshift 数据 API 连接到 Amazon Redshift Serverless。有关更多信息,请参阅使用 Amazon Redshift Data API
。 -
您可以通过 CREATE MODEL 命令,将 Amazon Redshift Serverless 中的数据与 Redshift ML 结合使用来创建机器学习模型。请参阅教程:构建客户流失模型,了解如何构建 Redshift ML 模型。
-
您可以从 Amazon S3 数据湖中查询数据,而无需将任何数据加载到 Amazon Redshift Serverless 中。有关更多信息,请参阅查询数据湖。
