本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
使用 將資料從內部部署資料倉儲遷移至 Amazon Redshift AWS Schema Conversion Tool
您可以使用 AWS SCT 代理程式從內部部署資料倉儲擷取資料,並將其遷移至 Amazon Redshift。代理程式會擷取您的資料,並將資料上傳至 Amazon S3,或針對大規模遷移,上傳 AWS Snowball Edge Edge 裝置。然後,您可以使用 AWS SCT 代理程式將資料複製到 Amazon Redshift。
或者,您可以使用 AWS Database Migration Service (AWS DMS) 將資料遷移至 Amazon Redshift。的優點 AWS DMS 是支援持續複寫 (變更資料擷取)。不過,若要提高資料遷移的速度,請平行使用多個 AWS SCT 代理程式。根據我們的測試, AWS SCT 代理程式遷移資料的速度比 AWS DMS 15-35% 快。速度的差異是由於資料壓縮、支援平行遷移資料表分割區,以及不同的組態設定。如需詳細資訊,請參閱使用 Amazon Redshift 資料庫做為 AWS Database Migration Service的目標。
Amazon S3 是一種儲存和擷取服務。若要將物件存放在 Amazon S3 中,請上傳您要存放至 Amazon S3 儲存貯體的檔案。當您上傳檔案時,您可以設定物件及任何中繼資料的許可。
大規模移轉
大規模資料遷移可以包含許多 TB 的資訊,而且可能會因網路效能和必須移動的資料量而變慢。 AWS Snowball Edge Edge 是一種 AWS 服務,您可以使用 AWS擁有的設備,以faster-than-network的速度將資料傳輸到雲端。 AWS Snowball Edge Edge 裝置最多可存放 100 TB 的資料。它使用 256 位元加密和業界標準的信任平台模組 (TPM),以確保資料的安全性和完整的chain-of-custody。 AWS SCT 可與 AWS Snowball Edge Edge 裝置搭配使用。
使用 AWS SCT 和 AWS Snowball Edge Edge 裝置時,您會分兩個階段遷移資料。首先,您會使用 AWS SCT 在本機處理資料,然後將該資料 AWS Snowball Edge 移至 Edge 裝置。然後 AWS ,您可以使用 AWS Snowball Edge Edge 程序將裝置傳送至 ,然後將資料 AWS 自動載入 Amazon S3 儲存貯體。接著,當資料在 Amazon S3 上可用時,您可以使用 將資料 AWS SCT 遷移至 Amazon Redshift。 AWS SCT 關閉時,資料擷取代理程式可以在背景中運作。
下圖顯示所支援的案例。
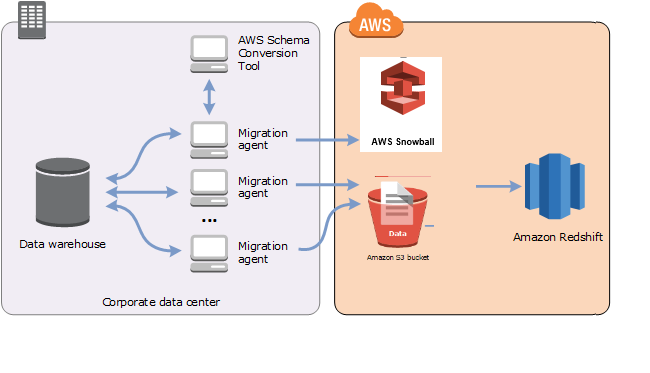
目前支援資料擷取代理程式的來源資料倉儲如下:
Azure Synapse Analytics
BigQuery
Greenplum 資料庫 (4.3 版)
Microsoft SQL Server (2008 版及更新版本)
Netezza (7.0.3 版及更新版本)
Oracle (10 版及更高版本)
Snowflake (第 3 版)
Teradata (13 版及更高版本)
Vertica (7.2.2 版及更新版本)
如果您需要遵守聯邦資訊處理標準 (FIPS) 安全要求,您可以連線至 Amazon Redshift 的 FIPS 端點。FIPS 端點可在下列 AWS 區域使用:
美國東部 (維吉尼亞北部) 區域 (redshift-fips.us-east-1.amazonaws.com://)
美國東部 (俄亥俄) 區域 (redshift-fips.us-east-2.amazonaws.com://)
美國西部 (加利佛尼亞北部) 區域 (redshift-fips.us-west-1.amazonaws.com://)
美國西部 (奧勒岡) 區域 (redshift-fips.us-west-2.amazonaws.com://)
使用下列主題中的資訊,以了解如何使用資料擷取代理程式。
主題
使用資料擷取代理程式的先決條件
使用資料擷取代理程式之前,請將 Amazon Redshift 作為目標所需的許可新增至 Amazon Redshift 使用者。如需詳細資訊,請參閱Amazon Redshift 做為目標的許可。
然後,存放您的 Amazon S3 儲存貯體資訊,並設定 Secure Sockets Layer (SSL) 信任和金鑰存放區。
Amazon S3 設定
客服人員擷取資料後,會將資料上傳至 Amazon S3 儲存貯體。在繼續之前,您必須提供登入資料才能連線到 AWS 您的帳戶和 Amazon S3 儲存貯體。您可以將登入資料和儲存貯體資訊存放在全域應用程式設定的設定檔中,然後將設定檔與您的 AWS SCT 專案建立關聯。如有必要,請選擇全域設定以建立新的設定檔。如需詳細資訊,請參閱在 中管理設定檔 AWS Schema Conversion Tool。
若要將資料遷移到目標 Amazon Redshift 資料庫, AWS SCT 資料擷取代理程式需要代表您存取 Amazon S3 儲存貯體的許可。若要提供此許可,請使用下列政策建立 AWS Identity and Access Management (IAM) 使用者。
{ "Version": "2012-10-17", "Statement": [ { "Action": [ "s3:PutObject", "s3:DeleteObject", "s3:GetObject", "s3:GetObjectTagging", "s3:PutObjectTagging" ], "Resource": [ "arn:aws:s3:::bucket_name/*", "arn:aws:s3:::bucket_name" ], "Effect": "Allow" }, { "Action": [ "s3:ListBucket", "s3:GetBucketLocation" ], "Resource": [ "arn:aws:s3:::bucket_name" ], "Effect": "Allow" }, { "Effect": "Allow", "Action": "s3:ListAllMyBuckets", "Resource": "*" }, { "Action": [ "iam:GetUser" ], "Resource": [ "arn:aws:iam::111122223333:user/DataExtractionAgentName" ], "Effect": "Allow" } ] }
在上述範例中,將 取代bucket_name111122223333:user/DataExtractionAgentName
擔任 IAM 角色
為了提高安全性,您可以使用 AWS Identity and Access Management (IAM) 角色來存取 Amazon S3 儲存貯體。若要這樣做,請為資料擷取代理程式建立 IAM 使用者,而不需要任何許可。然後,建立啟用 Amazon S3 存取的 IAM 角色,並指定可擔任此角色的 服務和使用者清單。如需詳細資訊,請參閱《IAM 使用者指南》中的 IAM 角色。
設定 IAM 角色以存取您的 Amazon S3 儲存貯體
-
建立新的 IAM 使用者。針對使用者登入資料,選擇程式設計存取類型。
-
設定主機環境,讓您的資料擷取代理程式可以擔任 AWS SCT 提供的角色。請確定您在上一個步驟中設定的使用者,可讓資料擷取代理程式使用登入資料提供者鏈結。如需詳細資訊,請參閱《 適用於 Java 的 AWS SDK 開發人員指南》中的使用登入資料。
-
建立可存取 Amazon S3 儲存貯體的新 IAM 角色。
-
修改此角色的信任區段,信任您之前建立的使用者擔任該角色。在下列範例中,將
111122223333:user/DataExtractionAgentName{ "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::111122223333:user/DataExtractionAgentName" }, "Action": "sts:AssumeRole" } -
修改此角色的信任區段,以信任
redshift.amazonaws.com擔任該角色。{ "Effect": "Allow", "Principal": { "Service": [ "redshift.amazonaws.com" ] }, "Action": "sts:AssumeRole" } -
將此角色連接至您的 Amazon Redshift 叢集。
現在,您可以在其中執行資料擷取代理程式 AWS SCT。
當您使用 IAM 角色擔任時,資料遷移的運作方式如下。資料擷取代理程式會使用登入資料提供者鏈結啟動並取得使用者登入資料。接著,您在 中建立資料遷移任務 AWS SCT,然後指定資料擷取代理程式要擔任的 IAM 角色,然後啟動任務。 AWS Security Token Service (AWS STS) 會產生臨時登入資料以存取 Amazon S3。資料擷取代理程式使用這些登入資料將資料上傳至 Amazon S3。
然後,為 Amazon Redshift AWS SCT 提供 IAM 角色。然後,Amazon Redshift 會從 取得新的臨時登入資料 AWS STS ,以存取 Amazon S3。Amazon Redshift 使用這些登入資料,將資料從 Amazon S3 複製到您的 Amazon Redshift 資料表。
安全性設定
AWS Schema Conversion Tool 和 擷取代理程式可以透過 Secure Sockets Layer (SSL) 進行通訊。若要啟用 SSL,請設定信任存放區和金鑰存放區。
設定與擷取代理程式的安全通訊
-
啟動 AWS Schema Conversion Tool。
-
開啟設定選單,然後選擇全域設定。Global settings (全域設定) 對話方塊隨即出現。
-
選擇 Security (安全性)。
-
選擇產生信任和金鑰存放區,或選擇選取現有的信任存放區。
如果您選擇產生信任和金鑰存放區,然後指定信任和金鑰存放區的名稱和密碼,以及產生檔案的位置路徑。您可以在稍後的步驟中使用這些檔案。
如果您選擇選取現有的信任存放區,然後指定信任存放區和金鑰存放區的密碼和檔案名稱。您可以在稍後的步驟中使用這些檔案。
-
指定信任存放區和金鑰存放區之後,請選擇確定以關閉全域設定對話方塊。
設定資料擷取代理程式的環境
您可以在單一主機上安裝多個資料擷取代理程式。不過,我們建議您在一個主機上執行一個資料擷取代理程式。
若要執行資料擷取代理程式,請確定您使用至少具有四個 vCPUs和 32 GB 記憶體的主機。此外,將 可用的最小記憶體設定為 AWS SCT 至少 4 GB。如需詳細資訊,請參閱設定其他記憶體。
最佳組態和客服人員主機數量取決於每位客戶的特定情況。請務必考慮此類因素,例如要遷移的資料量、網路頻寬、擷取資料的時間等。您可以先執行概念驗證 (PoC),然後根據此 PoC 的結果設定資料擷取代理程式和主機。
安裝擷取代理程式
建議您在個別的電腦上 (與執行 AWS Schema Conversion Tool的電腦分開),安裝多個擷取代理程式。
目前支援擷取代理程式的作業系統如下:
Microsoft Windows
Red Hat Enterprise Linux (RHEL) 6.0
Ubuntu Linux (14.04 版及更新版本)
請使用下列程序來安裝擷取代理程式。針對要安裝擷取代理程式的每部電腦,重複這個程序。
安裝擷取代理程式
-
如果您尚未下載 AWS SCT 安裝程式檔案,請遵循 中的指示安裝和設定 AWS Schema Conversion Tool進行下載。包含 AWS SCT 安裝程式檔案的 .zip 檔案也包含擷取代理程式安裝程式檔案。
-
下載並安裝最新版本的 Amazon Corretto 11。如需詳細資訊,請參閱《Amazon Corretto 11 使用者指南》中的 Amazon Corretto 11 的下載。
-
在名為 agents (代理程式) 的子資料夾中,找出擷取代理程式的安裝程式檔案。針對各種電腦作業系統,用來安裝擷取代理程式的正確檔案如下所示。
作業系統 檔案名稱 Microsoft Windows
aws-schema-conversion-tool-extractor-2.0.1.build-number.msiRHEL
aws-schema-conversion-tool-extractor-2.0.1.build-number.x86_64.rpmUbuntu Linux
aws-schema-conversion-tool-extractor-2.0.1.build-number.deb -
將安裝程式檔案複製到新的電腦,在不同的電腦上安裝擷取代理程式。
-
執行安裝程式檔案。使用適用於您作業系統的指示,如下所示。
作業系統 安裝說明 Microsoft Windows
按兩下檔案來執行安裝程式。
RHEL
在您下載或移動檔案的資料夾中執行下列命令。
sudo rpm -ivh aws-schema-conversion-tool-extractor-2.0.1.build-number.x86_64.rpm sudo ./sct-extractor-setup.sh --configUbuntu Linux
在您下載或移動檔案的資料夾中執行下列命令。
sudo dpkg -i aws-schema-conversion-tool-extractor-2.0.1.build-number.deb sudo ./sct-extractor-setup.sh --config -
選擇下一步,接受授權合約,然後選擇下一步。
-
輸入安裝 AWS SCT 資料擷取代理程式的路徑,然後選擇下一步。
-
選擇安裝以安裝您的資料擷取代理程式。
AWS SCT 安裝您的資料擷取代理程式。若要完成安裝,請設定您的資料擷取代理程式。 AWS SCT 會自動啟動組態設定程式。如需詳細資訊,請參閱設定擷取代理程式。
-
選擇完成以在設定資料擷取代理程式後關閉安裝精靈。
設定擷取代理程式
請使用下列程序來設定擷取代理程式。在已安裝擷取代理程式的每部電腦上,重複這個程序。
設定擷取代理程式
-
啟動組態設定程式:
-
在 Windows 中, 會在安裝資料擷取代理程式期間自動 AWS SCT 啟動組態設定程式。
您可以視需要手動啟動安裝程式。若要這樣做,請在 Windows 中執行
ConfigAgent.bat檔案。您可以在安裝代理程式的 資料夾中找到此檔案。 -
在 RHEL 和 Ubuntu 中,從您安裝代理程式的位置執行
sct-extractor-setup.sh檔案。
安裝程式會提示您輸入資訊。針對每個提示,都會顯示預設值。
-
-
在每個提示接受預設值,或輸入新值。
指定下列資訊:
針對接聽連接埠,輸入客服人員接聽的連接埠號碼。
對於新增來源廠商,請輸入是,然後輸入您的來源資料倉儲平台。
對於 JDBC 驅動程式,輸入您安裝 JDBC 驅動程式的位置。
針對工作資料夾,輸入 AWS SCT 資料擷取代理程式將存放擷取資料的路徑。工作資料夾可以在與代理程式不同的電腦上,而且單一工作資料夾可由位在不同電腦上的多個代理程式共用。
針對啟用 SSL 通訊,輸入 yes。
針對金鑰存放區,輸入金鑰存放區檔案的位置。
針對金鑰存放區密碼,輸入金鑰存放區的密碼。
針對啟用用戶端 SSL 身分驗證,輸入 yes。
針對信任存放區,輸入信任存放區檔案的位置。
針對信任存放區密碼,輸入信任存放區的密碼。
安裝程式會更新擷取代理程式的設定檔。設定檔名為 settings.properties,位在擷取代理程式的安裝位置。
以下是設定檔範例。
$ cat settings.properties
#extractor.start.fetch.size=20000
#extractor.out.file.size=10485760
#extractor.source.connection.pool.size=20
#extractor.source.connection.pool.min.evictable.idle.time.millis=30000
#extractor.extracting.thread.pool.size=10
vendor=TERADATA
driver.jars=/usr/share/lib/jdbc/terajdbc4.jar
port=8192
redshift.driver.jars=/usr/share/lib/jdbc/RedshiftJDBC42-1.2.43.1067.jar
working.folder=/data/sct
extractor.private.folder=/home/ubuntu
ssl.option=OFF若要變更組態設定,您可以使用文字編輯器編輯settings.properties檔案,或再次執行代理程式組態。
使用專用複製代理程式安裝和設定擷取代理程式
您可以在具有共用儲存體和專用複製代理程式的組態中安裝擷取代理程式。下圖說明此案例。
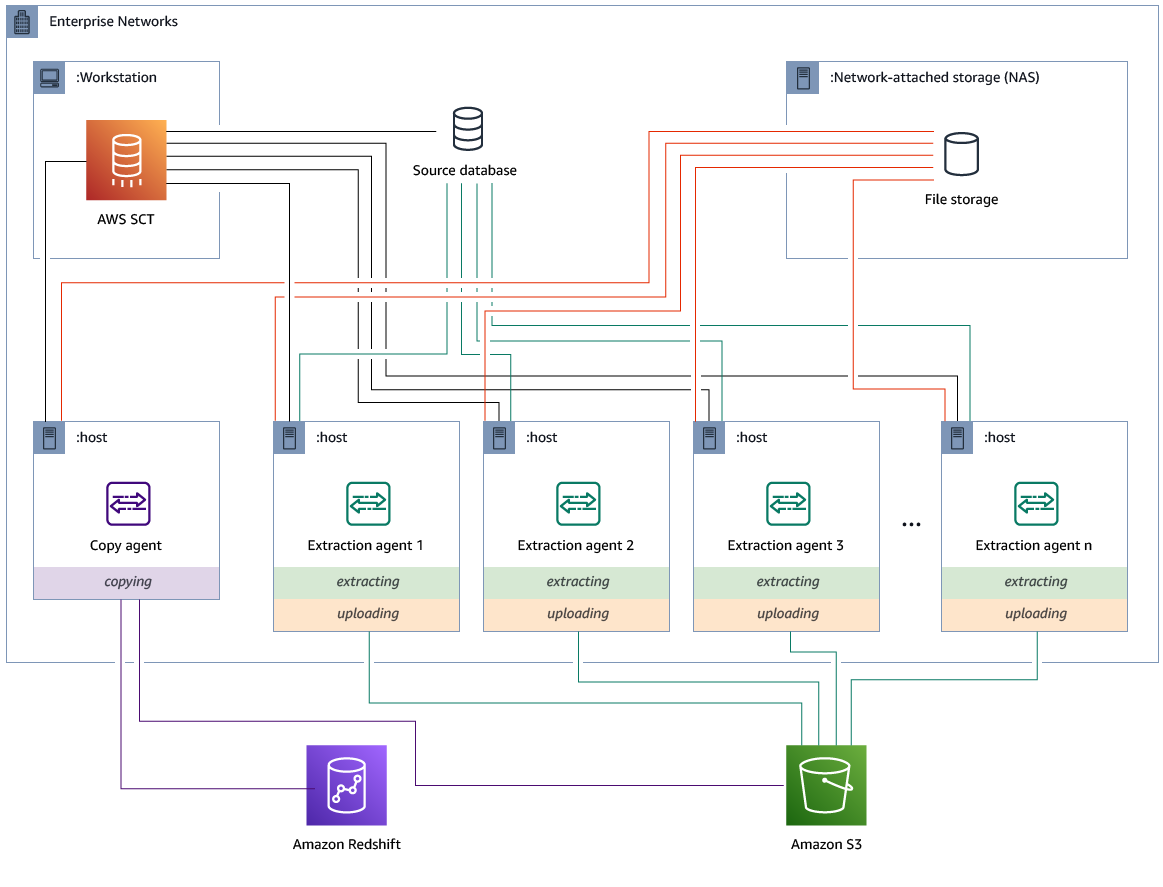
當來源資料庫伺服器支援最多 120 個連線,且您的網路已連接足夠的儲存空間時,該組態很有用。使用下列程序來設定具有專用複製代理程式的擷取代理程式。
安裝和設定擷取代理程式和專用複製代理程式
啟動擷取代理程式
請使用下列程序來啟動擷取代理程式。在已安裝擷取代理程式的每部電腦上,重複這個程序。
擷取代理程式是做為接聽程式。當您使用此程序來啟動代理程式時,代理程式即開始接聽指示。在稍後的章節中,您會傳送指示給代理程式,以從資料倉儲擷取資料。
啟動擷取代理程式
-
在已安裝擷取代理程式的電腦中,針對您的作業系統執行下列命令。
作業系統 Start 命令 Microsoft Windows
按兩下
StartAgent.bat批次檔。RHEL
在安裝代理程式的資料夾路徑中,執行下列命令:
sudo initctlstartsct-extractorUbuntu Linux
在安裝代理程式的資料夾路徑中,執行下列命令。使用 Ubuntu 版本適用的命令。
Ubuntu 14.04:
sudo initctlstartsct-extractorUbuntu 15.04 及更高版本:
sudo systemctlstartsct-extractor
若要查看代理程式的狀態,請執行相同的命令,但將 start 取代為 status。
若要停止代理程式,請執行相同的命令,但將 start 取代為 stop。
向 註冊擷取代理程式 AWS Schema Conversion Tool
您可以使用 管理您的擷取代理程式 AWS SCT。擷取代理程式是做為接聽程式。當他們收到指示時 AWS SCT,他們會從您的資料倉儲擷取資料。
使用下列程序向 AWS SCT 專案註冊擷取代理程式。
註冊擷取代理程式
-
啟動 AWS Schema Conversion Tool,然後開啟專案。
-
開啟檢視功能表,然後選擇資料遷移檢視 (其他)。Agents (代理程式) 索引標籤隨即出現。如果您先前已註冊客服人員, 會在標籤頂端的網格中 AWS SCT 顯示他們。
-
選擇註冊。
向 AWS SCT 專案註冊代理程式後,您無法向不同的專案註冊相同的代理程式。如果您在 AWS SCT 專案中不再使用 代理程式,您可以取消註冊它。然後可以再將其註冊於不同的專案。
-
選擇 Redshift 資料代理程式,然後選擇確定。
-
在對話方塊的連線索引標籤上輸入您的資訊:
-
在描述中,輸入代理程式的描述。
-
在主機名稱中,輸入代理程式電腦的主機名稱或 IP 地址。
-
針對連接埠,輸入客服人員接聽的連接埠號碼。
-
選擇註冊,向 AWS SCT 專案註冊代理程式。
-
-
重複上述步驟,以向 AWS SCT 專案註冊多個代理程式。
隱藏和復原 AWS SCT 代理程式的資訊
AWS SCT 代理程式會加密大量資訊,例如使用者金鑰信任存放區的密碼、資料庫帳戶、 AWS 帳戶資訊和類似項目。它是使用一個名為 seed.dat 的特殊檔案來執行此作業。依預設,代理程式會在第一個設定代理程式之使用者的工作資料夾中建立此檔案。
由於不同的使用者都可以設定及執行代理程式,因此 seed.dat 的路徑會存放在 settings.properties 檔案的 {extractor.private.folder} 參數中。代理程式啟動時,可以使用此路徑來尋找 seed.dat 檔案,以存取其作用之資料庫的金鑰信任存放區資訊。
您可能會需要復原代理程式在下列情況下存放的密碼:
如果使用者遺失
seed.dat檔案,且 AWS SCT 客服人員的位置和連接埠未變更。如果使用者遺失
seed.dat檔案,且 AWS SCT 代理程式的位置和連接埠已變更。在此情況下,通常會發生變更,因為代理程式已遷移到另一個主機或連接埠,而seed.dat檔案中的資訊不再有效。
在這些情況下,如果啟動代理程式時未使用 SSL,則代理程式會啟動,然後存取先前建立的代理程式儲存體。接著它會變成 Waiting for recovery (等待復原) 狀態。
不過,在這些情況下,如果啟動代理程式時有使用 SSL,您就無法將其重新啟動。這是因為代理程式無法將存放在 settings.properties 檔案中之憑證的密碼解密。在這種類型的啟動作業中,代理程式無法啟動。類似下列的錯誤會寫入日誌中:「代理程式無法在啟用 SSL 模式的情況下啟動。請重新設定代理程式。原因:金鑰存放區的密碼不正確。」
若要修正此問題,請建立新的代理程式,並將該代理程式設定為使用現有的密碼來存取 SSL 憑證。若要完成此操作,請遵循下列程序:
執行此程序後,代理程式應執行並前往等待復原狀態。 AWS SCT 會自動將所需的密碼傳送至處於等待復原狀態的代理程式。當代理程式取得密碼後,就會重新啟動任何任務。您不需要進一步的使用者動作 AWS SCT 。
重新設定代理程式並還原密碼來存取 SSL 憑證
安裝新的 AWS SCT 代理程式並執行組態。
將
instance.properties檔案的agent.name屬性,變更為已為其建立儲存體之代理程式的名稱,讓新的代理程式使用現有的代理程式儲存體。instance.properties檔案存放在代理程式的私有資料夾中,其使用下列命名慣例:{。output.folder}\dmt\{hostName}_{portNumber}\將
{的名稱變更為先前代理程式的輸出資料夾名稱。output.folder}此時, AWS SCT 仍在嘗試存取舊主機和連接埠的舊擷取器。因此,無法存取的擷取器會發生 FAILED (失敗) 狀態。然後您就可以變更主機和連接埠。
使用 Modify 命令,將請求流量重新導向至新的代理程式,藉以修改舊代理程式的主機及/或連接埠。
當 AWS SCT 可以 ping 新代理程式時, AWS SCT 會收到等待從代理程式復原的狀態。 AWS SCT 然後 會自動復原代理程式的密碼。
使用代理程式儲存體的每個代理程式都會更新一個名為 storage.lck 的特殊檔案 (位於 {)。這個檔案包含代理程式的網路 ID,以及直到儲存體鎖定的時間。當代理程式使用代理程式儲存體時,會更新 output.folder}\{agentName}\storage\storage.lck 檔案,並將儲存體的每 5 分鐘租賃期延長 10 分鐘。在租賃到期之前,其他執行個體都不能使用此代理程式儲存體。
在 中建立資料遷移規則 AWS SCT
使用 擷取資料之前 AWS Schema Conversion Tool,您可以設定篩選條件,以減少擷取的資料量。您可以使用 WHERE子句來減少您擷取的資料,以建立資料遷移規則。例如,您可以編寫從單一資料表選取資料的 WHERE 子句。
您可以建立資料遷移規則,並將篩選條件儲存為專案的一部分。開啟專案後,請使用下列程序來建立資料遷移規則。
建立資料遷移規則
-
開啟檢視功能表,然後選擇資料遷移檢視 (其他)。
-
選擇資料遷移規則,然後選擇新增規則。
-
設定您的資料遷移規則:
-
在名稱中,輸入資料遷移規則的名稱。
-
對於結構描述名稱類似的地方,輸入要套用至結構描述的篩選條件。此篩選條件是使用
LIKE子句來評估WHERE子句。若要選擇一個結構描述,請輸入確切的結構描述名稱。若要選擇多個結構描述,請使用「%」字元做為萬用字元,以符合結構描述名稱中任意數量的字元。 -
對於類似資料表名稱,輸入要套用至資料表的篩選條件。此篩選條件是使用
LIKE子句來評估WHERE子句。若要選擇一個資料表,請輸入確切的名稱。若要選擇多個資料表,請使用「%」字元做為萬用字元,以符合資料表名稱中任意數量的字元。 -
在 Where 子句中,輸入子
WHERE句來篩選資料。
-
-
設定篩選條件之後,選擇 Save (儲存),以儲存您的篩選條件,或選擇 Cancel (取消),以取消變更。
-
完成新增、編輯和刪除篩選條件後,請選擇全部儲存以儲存所有變更。
若要關閉篩選條件,但不將其刪除,請使用切換圖示。若要複製現有的篩選條件,請使用複製圖示。若要刪除現有的篩選條件,請使用刪除圖示。若要儲存您對篩選條件所做的任何變更,請選擇全部儲存。
從專案設定變更擷取器和複製設定
從 中的專案設定視窗中 AWS SCT,您可以選擇資料擷取代理程式的設定和 Amazon Redshift COPY命令。
若要選擇這些設定,請選擇設定、專案設定,然後選擇資料遷移。您可以在此編輯擷取設定、Amazon S3 設定和複製設定。
使用下表中的指示來提供擷取設定的資訊。
| 對於此參數 | 執行此作業 |
|---|---|
壓縮格式 |
指定輸入檔案的壓縮格式。選擇下列其中一個選項:GZIP、BZIP2、ZSTD 或無壓縮。 |
分隔符號字元 |
指定 ASCII 字元,以分隔輸入檔案中的欄位。不支援非列印字元。 |
NULL 值做為字串 |
如果您的資料包含 null 終止程式,請開啟此選項。如果關閉此選項,Amazon Redshift |
排序策略 |
使用排序從失敗點重新啟動擷取。選擇下列其中一種排序策略:在第一次失敗後使用排序 (建議)、盡可能使用排序,或從不使用排序。如需詳細資訊,請參閱使用 遷移之前排序資料 AWS SCT。 |
來源臨時結構描述 |
在來源資料庫中輸入結構描述的名稱,擷取代理程式可以在其中建立暫時物件。 |
輸出檔案大小 (MB) |
輸入上傳至 Amazon S3 的檔案大小,以 MB 為單位。 |
Snowball 輸出檔案大小 (MB) |
輸入上傳檔案的大小,以 MB 為單位 AWS Snowball Edge。檔案的大小可以是 1–1,000 MB。 |
使用自動分割。針對 Greenplum 和 Netezza,輸入支援的資料表大小下限 (以 MB 為單位) |
開啟此選項以使用資料表分割,然後為 Greenplum 和 Netezza 來源資料庫輸入要分割的資料表大小。對於 Oracle 到 Amazon Redshift 遷移,您可以保持此欄位空白,因為 會為所有分割資料表 AWS SCT 建立子任務。 |
擷取 LOBs |
開啟此選項可從來源資料庫擷取大型物件 (LOBs)。LOBs 包括 BLOBs、CLOBs、NCLOBs、XML 檔案等。對於每個 LOB, AWS SCT 擷取代理程式都會建立資料檔案。 |
Amazon S3 儲存貯體 LOBs |
輸入 AWS SCT 擷取代理程式存放 LOBs 的位置。 |
將 RTRIM 套用至字串資料欄 |
開啟此選項,從擷取字串結尾修剪一組指定的字元。 |
上傳至 Amazon S3 後,將檔案保留在本機 |
在資料擷取代理程式將檔案上傳至 Amazon S3 之後,開啟此選項以保留本機電腦上的檔案。 |
使用下表中的指示來提供 Amazon S3 設定的資訊。
| 對於此參數 | 執行此作業 |
|---|---|
使用代理 |
開啟此選項以使用代理伺服器將資料上傳至 Amazon S3。然後選擇資料傳輸通訊協定,輸入主機名稱、連接埠、使用者名稱和密碼。 |
端點類型 |
選擇 FIPS 以使用聯邦資訊處理標準 (FIPS) 端點。選擇 VPCE 以使用虛擬私有雲端 (VPC) 端點。然後,針對 VPC 端點,輸入 VPC 端點的網域名稱系統 (DNS)。 |
在複製到 Amazon Redshift 之後,將檔案保留在 Amazon S3 上 |
開啟此選項可在將這些檔案複製到 Amazon Redshift 之後,在 Amazon S3 上保留解壓縮的檔案。 |
使用下表中的指示來提供複製設定的資訊。
| 對於此參數 | 執行此作業 |
|---|---|
錯誤計數上限 |
輸入載入錯誤的數量。操作達到此限制後, AWS SCT 資料擷取代理程式會結束資料載入程序。預設值為 0,這表示 AWS SCT 資料擷取代理程式無論失敗,都會繼續資料載入。 |
取代無效的 UTF-8 字元 |
開啟此選項以使用指定的字元取代無效的 UTF-8 字元,並繼續資料載入操作。 |
使用空白做為 null 值 |
開啟此選項可載入空白欄位,其中包含 null 空白字元。 |
使用空白做為 null 值 |
開啟此選項,將空 |
截斷資料欄 |
開啟此選項可截斷資料欄中的資料,以符合資料類型規格。 |
自動壓縮 |
開啟此選項以在複製操作期間套用壓縮編碼。 |
自動統計資料重新整理 |
開啟此選項可在複製操作結束時重新整理統計資料。 |
載入前檢查檔案 |
開啟此選項以驗證資料檔案,然後再將其載入 Amazon Redshift。 |
使用 遷移之前排序資料 AWS SCT
使用 遷移前排序資料 AWS SCT 可提供一些好處。如果您先排序資料, AWS SCT 可以在失敗後的最後一個儲存點重新啟動擷取代理程式。此外,如果您要將資料遷移至 Amazon Redshift 且先排序資料, AWS SCT 可以更快地將資料插入至 Amazon Redshift。
這些優點與 如何 AWS SCT 建立資料擷取查詢有關。在某些情況下, AWS SCT 會在這些查詢中使用 DENSE_RANK 分析函數。不過,DENSE_RANK 可以使用大量時間和伺服器資源來排序擷取產生的資料集,因此,如果 AWS SCT 可以在沒有資料集的情況下運作,它可以。
在使用 遷移之前排序資料 AWS SCT
開啟 AWS SCT 專案。
開啟物件的內容 (按一下滑鼠右鍵) 選單,然後選擇建立本機任務。
選擇進階索引標籤,然後針對排序策略選擇選項:
永遠不要使用排序 – 擷取代理程式不會使用 DENSE_RANK 分析函數,並在發生失敗時從頭開始重新啟動。
如果可能,請使用排序 – 如果資料表具有主索引鍵或唯一限制條件,則擷取代理程式會使用 DENSE_RANK。
第一次失敗後使用排序 (建議) – 擷取代理程式會先嘗試取得資料,而不使用 DENSE_RANK。如果第一次嘗試失敗,擷取代理程式就會使用 DENSE_RANK 來重建查詢,並且在發生失敗時,保留其位置。

依下列說明設定額外的參數,然後選擇 Create (建立) 來建立您的資料擷取任務。
建立、執行和監控 AWS SCT 資料擷取任務
使用下列程序來建立、執行及監控資料擷取任務。
將任務指派給代理程式並遷移資料
-
在 中 AWS Schema Conversion Tool,轉換結構描述之後,請從專案的左側面板選擇一或多個資料表。
您可以選擇所有資料表,但基於效能考量,建議您不要這麼做。建議您根據資料倉儲中的資料表大小,為多個資料表建立多個任務。
-
開啟每個資料表的內容 (按一下滑鼠右鍵) 選單,然後選擇建立任務。建立本機任務對話方塊隨即開啟。
-
在任務名稱中,輸入任務的名稱。
-
針對遷移模式,選擇下列其中一項:
-
僅限擷取 – 擷取您的資料,並將資料儲存至本機工作資料夾。
-
擷取和上傳 – 擷取您的資料,並將您的資料上傳到 Amazon S3。
-
擷取、上傳和複製 – 擷取資料、將資料上傳至 Amazon S3,並將其複製到 Amazon Redshift 資料倉儲。
-
-
針對加密類型,選擇下列其中一項:
-
NONE – 關閉整個資料遷移程序的資料加密。
-
CSE_SK – 使用用戶端加密搭配對稱金鑰來遷移資料。 AWS SCT 會自動產生加密金鑰,並使用 Secure Sockets Layer (SSL) 將其傳輸到資料擷取代理程式。 AWS SCT 不會在資料遷移期間加密大型物件 LOBs)。
-
-
選擇 Extract LOBs (擷取 LOB),以擷取大型物件。如果您不需要擷取大型物件,可以清除此核取方塊。這麼做可以減少您擷取的資料量。
-
若要查看任務的詳細資訊,請選擇啟用任務記錄。您可以使用任務日誌來進行問題偵錯。
如果您啟用任務記錄功能,請選擇您要查看的詳細層級。各層級如下所示,每個層級都包含上一個層級中的所有訊息:
ERROR– 最小量的細節。WARNINGINFODEBUGTRACE– 最大數量的詳細資訊。
-
若要從 BigQuery 匯出資料, AWS SCT 會使用 Google Cloud Storage 儲存貯體資料夾。在此資料夾中,資料擷取代理程式會存放您的來源資料。
若要輸入 Google Cloud Storage 儲存貯體資料夾的路徑,請選擇進階。針對 Google CS 儲存貯體資料夾,輸入儲存貯體名稱和資料夾名稱。
-
若要為您的資料擷取代理程式使用者擔任角色,請選擇 Amazon S3 設定。針對 IAM 角色,輸入要使用的角色名稱。針對區域,選擇此角色 AWS 區域 的 。
-
選擇測試任務,以確認您可以連線至工作資料夾、Amazon S3 儲存貯體和 Amazon Redshift 資料倉儲。此驗證取決於您選擇的遷移模式。
-
選擇 Create (建立),以建立任務。
-
針對您要遷移的所有資料,重複上述步驟來建立任務。
執行及監控任務
-
針對檢視,選擇資料遷移檢視。Agents (代理程式) 索引標籤隨即出現。
-
選擇 Tasks (任務) 索引標籤。您的任務會出現在網格頂端,如下所示。您可以在頂端網格中查看任務的狀態,以及在底部網格中查看其子任務的狀態。

-
在頂端網格中選擇任務,並將其展開。依據您選擇的遷移模式,您會看到任務區分成 Extract (擷取)、Upload (上傳) 和 Copy (複製)。
-
針對某項任務選擇 Start (啟動),以啟動該任務。您可以在任務進行時,監控其狀態。子任務會平行執行。擷取、上傳和複製也會平行執行。
-
如果在設定任務時,已啟用記錄功能,則可檢視日誌:
-
選擇下載日誌。隨即出現訊息顯示包含該日誌檔的資料夾名稱。請關閉訊息。
-
Task details (任務詳細資訊) 索引標籤中會顯示一個連結。請選擇該連結,以開啟包含日誌檔的資料夾。
-
您可以關閉 AWS SCT,您的代理程式和任務會繼續執行。您可以 AWS SCT 稍後重新開啟,以檢查任務的狀態並檢視任務日誌。
您可以將資料擷取任務儲存至本機磁碟,並使用匯出和匯入將其還原至相同或其他專案。若要匯出任務,請確定您在專案中至少已建立一項擷取任務。您可以匯入單一擷取任務或在專案中建立的所有任務。
匯出擷取任務時, 會為該任務 AWS SCT 建立個別.xml的檔案。.xml 檔案會存放該任務的中繼資料資訊,例如任務屬性、描述和子任務。.xml 檔案不包含有關擷取任務處理的資訊。匯入任務時,會重新建立下列資訊:
-
任務進度
-
子任務和階段狀態
-
依子任務和階段擷取代理程式的分佈
-
任務和子任務 IDs
-
Task name (任務名稱)
匯出和匯入 AWS SCT 資料擷取任務
您可以快速儲存一個專案的現有任務,並使用 AWS SCT 匯出和匯入將其還原到另一個專案 (或相同的專案)。使用下列程序匯出和匯入資料擷取任務。
匯出和匯入資料擷取任務
-
針對檢視,選擇資料遷移檢視。Agents (代理程式) 索引標籤隨即出現。
-
選擇 Tasks (任務) 索引標籤。您的任務會列在顯示的網格中。
-
選擇任務清單右下角的三個垂直對齊點 (省略符號圖示)。
-
從快顯功能表中選擇匯出任務。
-
選擇您要 AWS SCT 放置任務匯出
.xml檔案的資料夾。AWS SCT 會建立檔案名稱格式為 的任務匯出檔案
TASK-DESCRIPTION_TASK-ID.xml -
選擇任務清單右下角的三個垂直對齊點 (省略符號圖示)。
-
從快顯功能表中選擇匯入任務。
您可以將擷取任務匯入至連線至來源資料庫的專案,且該專案至少有一個作用中的已註冊擷取代理程式。
-
選取您匯出之擷取任務
.xml的檔案。AWS SCT 從 檔案取得擷取任務的參數、建立任務,並將任務新增至擷取代理程式。
-
重複這些步驟以匯出和匯入其他資料擷取任務。
在此程序結束時,您的匯出和匯入已完成,且您的資料擷取任務已準備好可供使用。
使用 AWS Snowball Edge Edge 裝置擷取資料
使用 AWS SCT 和 AWS Snowball Edge Edge 的程序有幾個步驟。遷移涉及一個本機任務,其中 AWS SCT 使用資料擷取代理程式將資料移動到 AWS Snowball Edge Edge 裝置,然後是中繼動作,其中 將資料從 AWS Snowball Edge Edge 裝置 AWS 複製到 Amazon S3 儲存貯體。程序完成從 Amazon S3 儲存貯體將資料 AWS SCT 載入 Amazon Redshift。
本概觀後續小節提供以下各項任務的逐步操作指南。此程序假設您 AWS SCT 已安裝 ,且已在專用機器上設定並註冊資料擷取代理程式。
執行下列步驟,使用 AWS Snowball Edge Edge 將資料從本機資料存放區遷移至 AWS 資料存放區。
使用 AWS Snowball Edge 主控台建立 AWS Snowball Edge Edge 任務。
使用本機專用 Linux 機器解鎖 AWS Snowball Edge Edge 裝置。
在 中建立新專案 AWS SCT。
安裝和設定您的資料擷取代理程式。
建立並設定要使用的 Amazon S3 儲存貯體的權限。
將 AWS Snowball Edge 任務匯入您的 AWS SCT 專案。
在 中註冊資料擷取代理程式 AWS SCT。
在 中建立本機任務 AWS SCT。
執行並監控其中的資料遷移任務 AWS SCT。
使用 AWS SCT 和 AWS Snowball Edge Edge 遷移資料的Step-by-step程序
以下小節提供遷移步驟的詳細資訊。
步驟 1:建立 AWS Snowball Edge Edge 任務
遵循 AWS Snowball Edge Edge 開發人員指南中建立邊緣 AWS Snowball Edge 任務一節所述的步驟來建立任務。 AWS Snowball Edge
步驟 2:解鎖 AWS Snowball Edge Edge 裝置
從安裝 AWS DMS 代理程式的機器執行解鎖並提供登入資料給 Snowball Edge 裝置的命令。透過執行這些命令,您可以確定 AWS DMS 代理程式呼叫連線到 AWS Snowball Edge Edge 裝置。如需解除鎖定 AWS Snowball Edge Edge 裝置的詳細資訊,請參閱解除鎖定 Snowball Edge。
aws s3 ls s3://<bucket-name> --profile <Snowball Edge profile> --endpoint http://<Snowball IP>:8080 --recursive
步驟 3:建立新的 AWS SCT 專案
接著,建立新的 AWS SCT 專案。
在 中建立新專案 AWS SCT
-
啟動 AWS Schema Conversion Tool。在檔案功能表上,選擇新增專案。新專案對話方塊隨即出現。
-
輸入專案的名稱,這會儲存在本機電腦上。
-
輸入本機專案檔案的位置。
-
選擇確定以建立您的 AWS SCT 專案。
-
選擇新增來源,將新的來源資料庫新增至您的 AWS SCT 專案。
-
選擇新增目標以在 AWS SCT 專案中新增新的目標平台。
-
在左側面板中選擇來源資料庫結構描述。
-
在右側面板中,指定所選來源結構描述的目標資料庫平台。
-
選擇建立對應。在您選擇來源資料庫結構描述和目標資料庫平台之後,此按鈕會變成作用中。
步驟 4:安裝和設定您的資料擷取代理程式
AWS SCT 使用資料擷取代理程式將資料遷移至 Amazon Redshift。您下載安裝的 .zip 檔案 AWS SCT包含擷取代理程式安裝程式檔案。您可以在 Windows、Red Hat Enterprise Linux 或 Ubuntu 中安裝資料擷取代理程式。如需詳細資訊,請參閱安裝擷取代理程式。
若要設定資料擷取代理程式,請輸入您的來源和目標資料庫引擎。此外,請確定您在執行資料擷取代理程式的電腦上下載來源和目標資料庫的 JDBC 驅動程式。資料擷取代理程式使用這些驅動程式連接到您的來源和目標資料庫。如需詳細資訊,請參閱安裝 的 JDBC 驅動程式 AWS Schema Conversion Tool。
在 Windows 中,資料擷取代理程式安裝程式會在命令提示視窗中啟動組態精靈。在 Linux 中,從您安裝代理程式的位置執行 sct-extractor-setup.sh 檔案。
步驟 5:設定 AWS SCT 以存取 Amazon S3 儲存貯體
如需設定 Amazon S3 儲存貯體的詳細資訊,請參閱《Amazon Simple Storage Service 使用者指南》中的儲存貯體概觀。
步驟 6:將 AWS Snowball Edge 任務匯入 AWS SCT 專案
若要將您的 AWS SCT 專案與 AWS Snowball Edge Edge 裝置連線,請匯入您的 AWS Snowball Edge 任務。
匯入您的 AWS Snowball Edge 任務
-
開啟設定選單,然後選擇全域設定。Global settings (全域設定) 對話方塊隨即出現。
-
選擇AWS 服務設定檔,然後選擇匯入任務。
選擇您的 AWS Snowball Edge 任務。
-
輸入您的 AWS Snowball Edge IP。如需詳細資訊,請參閱AWS Snowball Edge 《 使用者指南》中的變更您的 IP 地址。
-
輸入您的 AWS Snowball Edge 連接埠。如需詳細資訊,請參閱 AWS Snowball Edge Edge 開發人員指南中的在 AWS Snowball Edge Edge 裝置上使用 AWS 服務所需的連接埠。
-
輸入您的AWS Snowball Edge 存取金鑰和AWS Snowball Edge 私密金鑰。如需詳細資訊,請參閱AWS Snowball Edge 《 使用者指南》中的授權和存取控制 AWS Snowball Edge。
選擇 Apply (套用),然後選擇 OK (確定)。
步驟 7:在 中註冊資料擷取代理程式 AWS SCT
在本節中,您會在 中註冊資料擷取代理程式 AWS SCT。
註冊資料擷取代理程式
-
在檢視功能表中,選擇資料遷移檢視 (其他),然後選擇註冊。
-
在描述中,輸入資料擷取代理程式的名稱。
-
針對主機名稱,輸入執行資料擷取代理程式之電腦的 IP 地址。
-
在連接埠中,輸入您設定的接聽連接埠。
-
選擇註冊。
步驟 8:建立本機任務
接著,建立遷移任務。任務包含兩個子任務,一個子任務會將資料從來源資料庫遷移到 AWS Snowball Edge Edge 設備。另一子任務會擷取裝置載入到 Amazon S3 儲存貯體的資料,並將資料遷移到目標資料庫。
建立遷移任務
-
在檢視功能表上,然後選擇資料遷移檢視 (其他)。
左側窗格會顯示您的來源資料庫的結構描述,請選擇要遷移的結構描述物件。開啟物件的內容 (按一下滑鼠右鍵) 選單,然後選擇建立本機任務。
-
在任務名稱中,輸入資料遷移任務的描述性名稱。
-
針對遷移模式,選擇擷取、上傳和複製。
-
選擇 Amazon S3 設定。
-
選取使用 Snowball Edge。
-
在資料擷取代理程式可以存放資料的 Amazon S3 儲存貯體中輸入資料夾和子資料夾。
-
選擇 Create (建立),以建立任務。
步驟 9:在 中執行和監控資料遷移任務 AWS SCT
若要啟動資料遷移任務,請選擇開始。請確定您已建立來源資料庫、Amazon S3 儲存貯體、 AWS Snowball Edge 裝置的連線,以及目標資料庫的連線 AWS。
您可以在任務索引標籤中監控和管理資料遷移任務及其子任務。您可以查看資料遷移進度,以及暫停或重新啟動資料遷移任務。
資料擷取任務輸出
在遷移任務完成後,您的資料即已準備好。利用下列資訊,根據您選擇的遷移模式和資料的位置來決定如何繼續進行。
| 遷移模式 | 資料位置 |
|---|---|
|
擷取、上傳和複製 |
資料已經在您的 Amazon Redshift 資料倉儲中。您可以確認資料在那裡,並開始使用。如需詳細資訊,請參閱從用戶端工具和程式碼連線至叢集。 |
|
擷取和上傳 |
擷取代理程式會將您的資料儲存為 Amazon S3 儲存貯體中的檔案。您可以使用 Amazon Redshift COPY 命令將資料載入 Amazon Redshift。如需詳細資訊,請參閱 Amazon Redshift 文件中的從 Amazon S3 載入資料。 Amazon S3 儲存貯體中有多個資料夾,對應於您設定的擷取任務。當您將資料載入 Amazon Redshift 時,請指定每個任務建立的資訊清單檔案名稱。資訊清單檔案會顯示在 Amazon S3 儲存貯體的任務資料夾中,如下所示。 
|
|
僅擷取 |
擷取代理程式會將您的資料儲存成檔案,放在工作資料夾中。手動將資料複製到 Amazon S3 儲存貯體,然後繼續執行擷取和上傳的指示。 |
搭配 使用虛擬分割 AWS Schema Conversion Tool
通常管理大型未分割資料表的最佳方式,就是建立子任務,以使用篩選規則來建立資料表資料的虛擬分割區。在 中 AWS SCT,您可以為遷移的資料建立虛擬分割區。有三種分割區類型,適用於特定的資料類型:
RANGE 分割區類型適用於數值以及日期和時間資料類型。
LIST 分割區類型適用於數值、字元,以及日期和時間資料類型。
DATE AUTO SPLIT 分割區類型適用於數值、日期和時間資料類型。
AWS SCT 驗證您為建立分割區所提供的值。例如,如果您嘗試分割資料類型為 NUMERIC 的資料欄,但您提供不同資料類型的值,則 會 AWS SCT 擲出錯誤。
此外,如果您使用 AWS SCT 將資料遷移至 Amazon Redshift,您可以使用原生分割來管理大型資料表的遷移。如需詳細資訊,請參閱使用原生分割。
建立虛擬分割時的限制
以下是建立虛擬分割區的限制:
您只能將虛擬分割用於未分割的資料表。
您只能在資料遷移檢視中使用虛擬分割。
您不能將 UNION ALL VIEW 選項與虛擬分割搭配使用。
RANGE 分割區類型
RANGE 分割區類型會根據數值以及日期和時間資料類型的資料欄值範圍來分割資料。這個分割區類型會建立 WHERE 子句,而您要針對每個分割區提供值的範圍。若要指定分割資料欄的值清單,請使用值方塊。您可以使用 .csv 檔案來載入值資訊。
RANGE 分割區類型會在分割區值的兩端建立預設分割區。這些預設分割區會擷取小於或等於指定分割區值的任何資料。
例如,您可以根據您提供的值範圍建立多個分割區。下列範例會指定 LO_TAX 的分割值來建立多個分割區。
Partition1: WHERE LO_TAX <= 10000.9 Partition2: WHERE LO_TAX > 10000.9 AND LO_TAX <= 15005.5 Partition3: WHERE LO_TAX > 15005.5 AND LO_TAX <= 25005.95
建立 RANGE 虛擬分割區
開啟 AWS SCT。
選擇資料遷移檢視 (其他) 模式。
選擇您要在其中設定虛擬分割的資料表。開啟資料表的內容 (按一下滑鼠右鍵) 選單,然後選擇新增虛擬分割。
在新增虛擬分割對話方塊中,輸入資訊,如下所示。
選項 動作 分割區類型
選擇 RANGE。對話方塊 UI 會依據您選擇的類型而變更。
資料欄名稱
選擇您想要分割的資料欄。
資料欄類型
選擇資料欄值的資料類型。
Values (數值)
在 New Value (新值) 方塊中輸入每個值,以新增值,然後選擇加號,以加入該值。
從檔案載入
(選用) 輸入包含分割區值的 .csv 檔案名稱。
-
選擇確定。
LIST 分割區類型
LIST 分割區類型會根據數值、字元以及日期和時間資料類型的資料欄值來分割資料。這個分割區類型會建立 WHERE 子句,而您要針對每個分割區提供值。若要指定分割資料欄的值清單,請使用值方塊。您可以使用 .csv 檔案來載入值資訊。
例如,您可以根據您提供的值來建立多個分割區。下列範例會指定 LO_ORDERKEY 的分割值來建立多個分割區。
Partition1: WHERE LO_ORDERKEY = 1 Partition2: WHERE LO_ORDERKEY = 2 Partition3: WHERE LO_ORDERKEY = 3 … PartitionN: WHERE LO_ORDERKEY = USER_VALUE_N
您也可以針對未包含在指定分割區中的值,建立預設分割區。
如果您想要從遷移中排除特定值,您可以使用 LIST 分割區類型來篩選來源資料。例如,假設您想要省略具有 的資料列LO_ORDERKEY = 4。在此情況下,請勿在分割區值4清單中包含 值,並確保未選擇包含其他值。
建立 LIST 虛擬分割區
開啟 AWS SCT。
選擇資料遷移檢視 (其他) 模式。
選擇您要在其中設定虛擬分割的資料表。開啟資料表的內容 (按一下滑鼠右鍵) 選單,然後選擇新增虛擬分割。
在新增虛擬分割對話方塊中,輸入資訊,如下所示。
選項 動作 分割區類型
選擇 LIST。對話方塊 UI 會依據您選擇的類型而變更。
資料欄名稱
選擇您想要分割的資料欄。
新值
在這裡輸入一個值,以將其新增至一組分割值。
包含其他值
選擇此選項來建立的預設分割區中,會存放不符合分割條件的所有值。
從檔案載入
(選用) 輸入包含分割區值的 .csv 檔案名稱。
選擇確定。
DATE AUTO SPLIT 分割區類型
DATE AUTO SPLIT 分割區類型是一種自動產生 RANGE 分割區的方式。使用 DATA AUTO SPLIT,您可以告知 AWS SCT 分割屬性、開始和結束的位置,以及值之間的範圍大小。然後 AWS SCT , 會自動計算分割區值。
DATA AUTO SPLIT 會自動化許多與建立範圍分割區相關的工作。使用此技術和範圍分割之間的取捨,是您需要對分割區邊界進行多少控制。自動分割程序一律會建立相等大小 (統一) 範圍。範圍分割可讓您根據特定資料分佈的需求,變更每個範圍的大小。例如,您可以使用每日、每週、每兩週、每月等。
Partition1: WHERE LO_ORDERDATE >= ‘1954-10-10’ AND LO_ORDERDATE < ‘1954-10-24’ Partition2: WHERE LO_ORDERDATE >= ‘1954-10-24’ AND LO_ORDERDATE < ‘1954-11-06’ Partition3: WHERE LO_ORDERDATE >= ‘1954-11-06’ AND LO_ORDERDATE < ‘1954-11-20’ … PartitionN: WHERE LO_ORDERDATE >= USER_VALUE_N AND LO_ORDERDATE <= ‘2017-08-13’
建立 DATE AUTO SPLIT 虛擬分割區
開啟 AWS SCT。
選擇資料遷移檢視 (其他) 模式。
選擇您要在其中設定虛擬分割的資料表。開啟資料表的內容 (按一下滑鼠右鍵) 選單,然後選擇新增虛擬分割。
在新增虛擬分割對話方塊中,輸入資訊,如下所示。
選項 動作 分割區類型
選擇 DATE AUTO SPLIT。對話方塊 UI 會依據您選擇的類型而變更。
資料欄名稱
選擇您想要分割的資料欄。
開始日期
輸入開始日期。
結束日期
輸入結束日期。
Interval (間隔)
輸入間隔單位,然後選擇該單位的值。
選擇確定。
使用原生分割
為了加速資料遷移,您的資料擷取代理程式可以在來源資料倉儲伺服器上使用資料表的原生分割區。 AWS SCT 支援原生分割,以便從 Greenplum、Netezza 和 Oracle 遷移至 Amazon Redshift。
例如,建立專案之後,您可以收集結構描述的統計資料,並分析為遷移選取的資料表大小。對於超過指定大小的資料表, AWS SCT 會觸發原生分割機制。
使用原生分割
-
開啟 AWS SCT,然後選擇檔案的新專案。新專案對話方塊隨即出現。
-
建立新的專案、新增來源和目標伺服器,以及建立映射規則。如需詳細資訊,請參閱在 中啟動和管理專案 AWS SCT。
-
選擇檢視,然後選擇主檢視。
-
針對專案設定,選擇資料遷移索引標籤。選擇使用自動分割。對於 Greenplum 和 Netezza 來源資料庫,輸入支援的資料表大小下限,以 MB 為單位 (例如 100)。 AWS SCT 會自動為每個非空白的原生分割區建立個別的遷移子任務。對於 Oracle 到 Amazon Redshift 遷移, 會為所有分割資料表 AWS SCT 建立子任務。
-
在顯示來源資料庫結構描述的左側面板中,選擇結構描述。開啟物件的內容 (按一下滑鼠右鍵) 選單,然後選擇收集統計資料。對於從 Oracle 遷移到 Amazon Redshift 的資料,您可以略過此步驟。
-
選擇要遷移的所有資料表。
-
註冊所需的客服人員數量。如需詳細資訊,請參閱向 註冊擷取代理程式 AWS Schema Conversion Tool。
-
為選取的資料表建立資料擷取任務。如需詳細資訊,請參閱建立、執行和監控 AWS SCT 資料擷取任務。
檢查大型資料表是否分割為子任務,以及每個子任務是否與呈現資料表一部分的資料集相符,該資料表位於來源資料倉儲中的一個配量上。
-
啟動和監控遷移程序,直到 AWS SCT 資料擷取代理程式完成從來源資料表遷移資料。
將 LOBs 遷移至 Amazon Redshift
Amazon Redshift 不支援儲存大型二進位物件 (LOBs)。不過,如果您需要將一或多個 LOBs 遷移至 Amazon Redshift, AWS SCT 可以執行遷移。若要這樣做, AWS SCT 會使用 Amazon S3 儲存貯體來存放 LOBs,並將 Amazon S3 儲存貯體的 URL 寫入存放在 Amazon Redshift 中的遷移資料。
將 LOBs 遷移至 Amazon Redshift
開啟 AWS SCT 專案。
連接到來源和目標資料庫。從目標資料庫重新整理中繼資料,並確認轉換後的資料表存在。
針對動作,選擇建立本機任務。
-
針對遷移模式,選擇下列其中一項:
-
擷取和上傳以擷取您的資料,並將您的資料上傳到 Amazon S3。
-
擷取、上傳和複製以擷取資料、將資料上傳到 Amazon S3,並將其複製到 Amazon Redshift 資料倉儲。
-
選擇 Amazon S3 設定。
對於 Amazon S3 儲存貯體 LOBs,在您要存放 LOBs 的 Amazon S3 儲存貯體中輸入資料夾的名稱。
如果您使用 AWS 服務設定檔,此欄位為選用。 AWS SCT 可以使用設定檔中的預設設定。若要使用另一個 Amazon S3 儲存貯體,請在此處輸入路徑。
-
開啟使用代理選項,使用代理伺服器將資料上傳至 Amazon S3。然後選擇資料傳輸通訊協定,輸入主機名稱、連接埠、使用者名稱和密碼。
-
針對端點類型,選擇 FIPS 以使用聯邦資訊處理標準 (FIPS) 端點。選擇 VPCE 以使用虛擬私有雲端 (VPC) 端點。然後,針對 VPC 端點,輸入 VPC 端點的網域名稱系統 (DNS)。
-
在複製到 Amazon Redshift 之後開啟在 Amazon S3 上保留檔案選項,以便在將這些檔案複製到 Amazon Redshift 之後在 Amazon S3 上保留解壓縮的檔案。
選擇 Create (建立),以建立任務。
資料擷取代理程式的最佳實務和疑難排解
以下是針對使用擷取代理程式的一些最佳實務和故障診斷建議。
| 問題 | 故障診斷建議 |
|---|---|
|
效能緩慢 |
為了改善效能,我們的建議如下:
|
|
爭用延遲 |
避免有太多代理程式同時存取您的資料倉儲。 |
|
代理程式暫時故障 |
如果代理程式故障,其每個任務的狀態會在 AWS SCT中顯示為失敗。如果您稍候一下,在某些情況下,代理程式可以復原。在此情況下,其任務的狀態會在 AWS SCT中更新。 |
|
代理程式永久故障 |
如果執行代理程式的電腦發生永久故障,且該代理程式正在執行任務,您可以更換新的代理程式來繼續執行任務。原始代理程式的工作資料夾,必須位在與原始代理程式不同的電腦上,才可以更換新的代理程式。若要更換新的代理程式,請執行下列動作:
|
