終止支援通知:2026 年 5 月 31 日, AWS 將終止對 的支援 AWS Panorama。2026 年 5 月 31 日之後,您將無法再存取 AWS Panorama 主控台或 AWS Panorama 資源。如需詳細資訊,請參閱AWS Panorama 終止支援。
本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
電腦視覺模型
電腦視覺模型是經過訓練的軟體程式,可偵測影像中的物件。模型會學習透過訓練先分析這些物件的影像,以辨識一組物件。電腦視覺模型會將影像做為輸入,並輸出其偵測到之物件的相關資訊,例如物件類型及其位置。AWS Panorama 支援使用 PyTorch、Apache MXNet 和 TensorFlow 建置的電腦視覺模型。
注意
如需已使用 AWS Panorama 測試的預先建置模型清單,請參閱模型相容性
在程式碼中使用模型
模型會傳回一或多個結果,其中可能包括偵測到的類別、位置資訊和其他資料的概率。下列範例示範如何從影片串流對影像執行推論,並將模型的輸出傳送至處理函數。
範例 application.py
def process_media(self, stream): """Runs inference on a frame of video.""" image_data = preprocess(stream.image,self.MODEL_DIM) logger.debug('Image data: {}'.format(image_data)) # Run inference inference_start = time.time()inference_results = self.call({"data":image_data}, self.MODEL_NODE)# Log metrics inference_time = (time.time() - inference_start) * 1000 if inference_time > self.inference_time_max: self.inference_time_max = inference_time self.inference_time_ms += inference_time # Process results (classification)self.process_results(inference_results, stream)
下列範例顯示處理基本分類模型結果的函數。範例模型會傳回機率陣列,這是結果陣列中第一個且唯一的值。
範例 application.py
def process_results(self, inference_results, stream): """Processes output tensors from a computer vision model and annotates a video frame.""" if inference_results is None: logger.warning("Inference results are None.") return max_results = 5 logger.debug('Inference results: {}'.format(inference_results)) class_tuple = inference_results[0] enum_vals = [(i, val) for i, val in enumerate(class_tuple[0])] sorted_vals = sorted(enum_vals, key=lambda tup: tup[1]) top_k = sorted_vals[::-1][:max_results] indexes = [tup[0] for tup in top_k] for j in range(max_results): label = 'Class [%s], with probability %.3f.'% (self.classes[indexes[j]], class_tuple[0][indexes[j]]) stream.add_label(label, 0.1, 0.1 + 0.1*j)
應用程式程式碼會尋找機率最高的值,並將其映射到初始化期間載入的資源檔案中的標籤。
建置自訂模型
您可以在 AWS Panorama 應用程式中使用在 PyTorch、Apache MXNet 和 TensorFlow 中建置的模型。除了在 SageMaker AI 中建置和訓練模型之外,您也可以使用訓練模型,或使用支援的架構建置和訓練自己的模型,並在本機環境或 Amazon EC2 中匯出模型。
注意
如需 SageMaker AI Neo 支援的架構版本和檔案格式的詳細資訊,請參閱《Amazon SageMaker AI 開發人員指南》中的支援的架構。
本指南的 儲存庫提供範例應用程式,以 TensorFlow SavedModel 格式示範 Keras 模型的此工作流程。它使用 TensorFlow 2,並且可以在虛擬環境或 Docker 容器中在本機執行。範例應用程式也包含範本和指令碼,用於在 Amazon EC2 執行個體上建置模型。
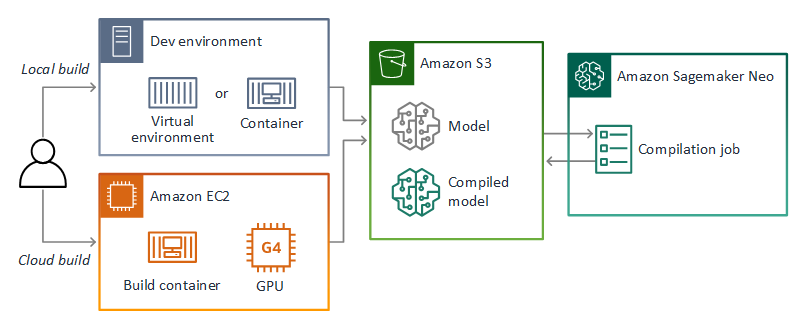
AWS Panorama 使用 SageMaker AI Neo 編譯模型,用於 AWS Panorama 設備。對於每個架構,請使用 SageMaker AI Neo 支援的格式,並將模型封裝在.tar.gz封存中。
如需詳細資訊,請參閱《Amazon SageMaker AI 開發人員指南》中的使用 Neo 編譯和部署模型。
封裝模型
模型套件包含描述項、套件組態和模型封存。與應用程式映像套件一樣,套件組態會通知 AWS Panorama 服務,模型和描述符存放在 Amazon S3 中。
範例 packages/123456789012-SQUEEZENET_PYTORCH-1.0/descriptor.json
{ "mlModelDescriptor": { "envelopeVersion": "2021-01-01", "framework": "PYTORCH", "frameworkVersion": "1.8", "precisionMode": "FP16", "inputs": [ { "name": "data", "shape": [ 1, 3, 224, 224 ] } ] } }
注意
僅指定架構版本的主要和次要版本。如需支援的 PyTorch、Apache MXNet 和 TensorFlow 版本清單,請參閱支援的架構。
若要匯入模型,請使用 AWS Panorama Application CLI import-raw-model命令。如果您對模型或其描述項進行任何變更,則必須重新執行此命令來更新應用程式的資產。如需詳細資訊,請參閱變更電腦視覺模型。
如需描述項檔案的 JSON 結構描述,請參閱 assetDescriptor.schema.json
訓練模型
當您訓練模型時,請使用目標環境的影像,或從與目標環境非常相似的測試環境。請考慮可能影響模型效能的下列因素:
-
照明 – 主體反射的光線量決定模型必須分析的細節。使用光線良好的主題影像訓練的模型可能無法在光線不足或背光的環境中正常運作。
-
解析度 – 模型的輸入大小通常以方形長寬比固定為 224 到 512 像素寬的解析度。將影片影格傳遞至模型之前,您可以縮減或裁切影片,以符合所需的大小。
-
影像失真 – 相機的焦距和鏡頭形狀可能會導致影像偏離影格中心。攝影機的位置也會決定可看見主體的哪些功能。例如,具有廣角鏡頭的頭頂攝影機會在主體位於影格中心時顯示其頂部,並在主體遠離中心時顯示其側面的傾斜檢視。
若要解決這些問題,您可以在將影像傳送到模型之前預先處理影像,並在反映真實環境中差異的更廣泛影像上訓練模型。如果模型需要在照明情況和各種攝影機中操作,您需要更多資料來進行訓練。除了收集更多影像之外,您還可以透過建立現有影像的變體來取得更多訓練資料,這些變體是偏斜或有不同的光源。
