本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
使用 Amazon Textract 從 PDF 檔案自動擷取內容
Tianxia Jia,Amazon Web Services
Summary
許多組織需要從上傳到其商業應用程式的 PDF 檔案擷取資訊。例如,組織可能需要準確從稅務或醫療 PDF 檔案擷取資訊,以進行稅務分析或醫療索賠處理。
在 Amazon Web Services (AWS) 雲端上,Amazon Textract 會自動從 PDF 檔案擷取資訊 (例如,列印的文字、表單和資料表),並產生 JSON 格式的檔案,其中包含原始 PDF 檔案的資訊。您可以在 AWS 管理主控台中或透過實作 API 呼叫來使用 Amazon Textract。我們建議您使用程式設計 API 呼叫
當 Amazon Textract 處理檔案時,會建立下列Block物件清單:頁面、行和文字、表單 (索引鍵/值對)、資料表和儲存格,以及選取元素。還包括其他物件資訊,例如週框方塊、可信度間隔、IDs和關係。Amazon Textract 會將內容資訊擷取為字串。正確識別和轉換的資料值是必要的,因為下游應用程式可以更輕鬆地使用這些值。
此模式描述使用 Amazon Textract 從 PDF 檔案自動擷取內容並將其處理為乾淨的輸出step-by-step工作流程。模式使用範本比對技術來正確識別必要欄位、金鑰名稱和資料表,然後將後置處理更正套用至每個資料類型。您可以使用此模式來處理不同類型的 PDF 檔案,然後您可以擴展和自動化此工作流程,以處理格式相同的 PDF 檔案。
先決條件和限制
先決條件
作用中的 AWS 帳戶
現有的 Amazon Simple Storage Service (Amazon S3) 儲存貯體,用於儲存轉換為 JPEG 格式供 Amazon Textract 處理後的 PDF 檔案。如需 S3 儲存貯體的詳細資訊,請參閱 Amazon S3 文件中的儲存貯體概觀。
已安裝和設定的
Textract_PostProcessing.ipynbJupyter 筆記本 (已連接)。如需 Jupyter 筆記本的詳細資訊,請參閱 Amazon SageMaker 文件中的建立 Jupyter 筆記本。 Amazon SageMaker具有相同格式的現有 PDF 檔案。
了解 Python。
限制
您的 PDF 檔案必須品質良好且清晰可讀。建議使用原生 PDF 檔案,但如果所有個別單字都清晰,您可以使用轉換為 PDF 格式的掃描文件。如需詳細資訊,請參閱 AWS Machine Learning 部落格上的使用 Amazon Textract:視覺效果偵測和移除進行 PDF 文件預先處理
。 對於多頁檔案,您可以使用非同步操作,或將 PDF 檔案分割成單一頁面並使用同步操作。如需這兩個選項的詳細資訊,請參閱 Amazon Textract 文件中的偵測和分析多頁文件中的文字,以及偵測和分析單頁文件中的文字。
架構
此模式的工作流程會先在範例 PDF 檔案上執行 Amazon Textract (第一次執行),然後在與第一個 PDF 格式相同的 PDF 檔案上執行它 (重複執行)。下圖顯示合併的第一次執行和重複執行工作流程,該工作流程會自動且重複地從具有相同格式的 PDF 檔案擷取內容。
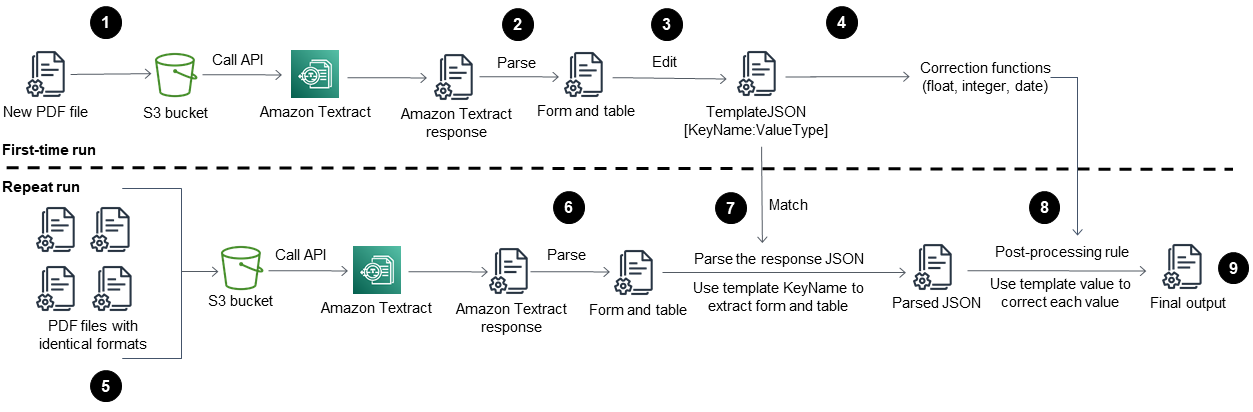
此圖表顯示此模式的下列工作流程:
將 PDF 檔案轉換為 JPEG 格式,並將其存放在 S3 儲存貯體中。
呼叫 Amazon Textract API 並剖析 Amazon Textract 回應 JSON 檔案。
透過為每個必要欄位新增正確的
KeyName:DataType配對來編輯 JSON 檔案。建立重複執行階段TemplateJSON的檔案。定義每個資料類型的後製處理更正函數 (例如浮點數、整數和日期)。
準備與您第一個 PDF 檔案格式相同的 PDF 檔案。
呼叫 Amazon Textract API 並剖析 Amazon Textract 回應 JSON。
比對剖析的 JSON 檔案與
TemplateJSON檔案。實作後置處理更正。
最終 JSON 輸出檔案Value的每個必要欄位都有正確的 KeyName和 。
目標技術堆疊
Amazon SageMaker
Amazon S3
Amazon Textract
自動化和擴展
您可以使用 AWS Lambda 函數來自動化重複執行工作流程,該函數會在新的 PDF 檔案新增至 Amazon S3 時啟動 Amazon Textract。然後,Amazon Textract 會執行處理指令碼,並將最終輸出儲存到儲存位置。如需詳細資訊,請參閱 Lambda 文件中的使用 Amazon S3 觸發來叫用 Lambda 函數。
工具
Amazon SageMaker 是一項全受管 ML 服務,可協助您快速輕鬆地建置和訓練 ML 模型,然後將它們直接部署到生產就緒的託管環境中。
Amazon Simple Storage Service (Amazon S3) 是一種雲端型物件儲存服務,可協助您儲存、保護和擷取任何數量的資料。
Amazon Textract 可讓您輕鬆地將文件文字偵測和分析新增至應用程式。
史詩
| 任務 | 描述 | 所需的技能 |
|---|---|---|
轉換 PDF 檔案。 | 將 PDF 檔案分割為單一頁面並將其轉換為 JPEG 格式以進行 Amazon Textract 同步操作 (),以準備初次執行的 PDF 檔案 注意您也可以將 Amazon Textract 非同步操作 ( | 資料科學家、開發人員 |
剖析 Amazon Textract 回應 JSON。 | 開啟
使用下列程式碼,將回應 JSON 剖析為表單和資料表:
| 資料科學家、開發人員 |
編輯 TemplateJSON 檔案。 | 編輯每個 此範本用於每個個別的 PDF 檔案類型,這表示範本可以重複使用於格式相同的 PDF 檔案。 | 資料科學家、開發人員 |
定義後製處理更正函數。 | Amazon Textract 對 使用下列程式碼,根據
| 資料科學家、開發人員 |
| 任務 | 描述 | 所需的技能 |
|---|---|---|
準備 PDF 檔案。 | 將 PDF 檔案分割成單一頁面,並將其轉換為 JPEG 格式以進行 Amazon Textract 同步操作 (),以準備 PDF 檔案 注意您也可以將 Amazon Textract 非同步操作 ( | 資料科學家、開發人員 |
呼叫 Amazon Textract API。 | 使用下列程式碼呼叫 Amazon Textract API:
| 資料科學家、開發人員 |
剖析 Amazon Textract 回應 JSON。 | 使用下列程式碼,將回應 JSON 剖析為表單和資料表:
| 資料科學家、開發人員 |
載入 TemplateJSON 檔案,並將其與剖析的 JSON 比對。 | 使用以下命令,使用
| 資料科學家、開發人員 |
後置處理更正。 | 在
| 資料科學家、開發人員 |
相關資源
附件
若要存取與本文件相關聯的其他內容,請解壓縮下列檔案: attachment.zip
