本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
將 Oracle ROWID 功能遷移至 AWS 上的 PostgreSQL
Rakesh Raghav 和 Ramesh Pathuri,Amazon Web Services
Summary
此模式說明將 Oracle 資料庫中的ROWID虛擬資料欄功能遷移至 PostgreSQL (Amazon Relational Database Service RDS) for PostgreSQL、Amazon Aurora PostgreSQL 相容版本或 Amazon Elastic Compute Cloud (Amazon EC2) 中 PostgreSQL 資料庫的選項。
在 Oracle 資料庫中,ROWID虛擬資料欄是資料表中資料列的實體地址。即使資料表上沒有主索引鍵,此虛擬資料欄也會用來唯一識別資料列。PostgreSQL 具有稱為 的類似虛擬資料欄ctid,但無法用作 ROWID。如 PostgreSQL 文件VACUUM程序之後, ctid可能會變更。
您可以透過三種方式在 PostgreSQL ROWID 中建立虛擬資料欄功能:
使用主索引鍵欄而非
ROWID來識別資料表中的資料列。在 資料表中使用邏輯主要/唯一金鑰 (可能是複合金鑰)。
新增具有自動產生值的資料欄,使其成為要模擬的主要/唯一金鑰
ROWID。
此模式會逐步解說這三個實作,並說明每個選項的優點和缺點。
先決條件和限制
先決條件
作用中的 AWS 帳戶
程序語言/PostgreSQL (PL/pgSQL) 編碼專業知識
來源 Oracle 資料庫
Amazon RDS for PostgreSQL 或 Aurora PostgreSQL 相容叢集,或託管 PostgreSQL 資料庫的 EC2 執行個體
限制
此模式提供
ROWID功能的解決方法。PostgreSQL 在ROWIDOracle 資料庫中不提供 的同等 。
產品版本
PostgreSQL 11.9 或更新版本
架構
來源技術堆疊
Oracle Database
目標技術堆疊
Aurora PostgreSQL 相容、Amazon RDS for PostgreSQL 或具有 PostgreSQL 資料庫的 EC2 執行個體
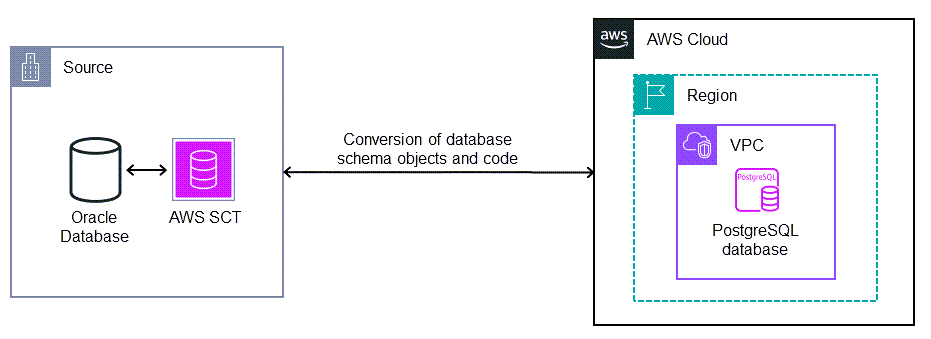
實作選項
根據您的資料表是否具有主索引鍵或唯一索引、邏輯主索引鍵或身分屬性,有三個選項可以解決 PostgreSQL 中缺乏ROWID支援的問題。您的選擇取決於您的專案時間表、目前的遷移階段,以及應用程式和資料庫程式碼的相依性。
選項 | 描述 | 優點 | 缺點 |
|---|---|---|---|
主索引鍵或唯一索引 | 如果您的 Oracle 資料表有主索引鍵,您可以使用此索引鍵的屬性來唯一識別資料列。 |
|
|
邏輯主要/唯一金鑰 | 如果您的 Oracle 資料表具有邏輯主索引鍵,您可以使用此索引鍵的屬性來唯一識別資料列。邏輯主索引鍵包含屬性或一組屬性,可唯一識別資料列,但不會透過限制在資料庫上強制執行。 |
|
|
身分屬性 | 如果您的 Oracle 資料表沒有主索引鍵,您可以將其他欄位建立為 |
|
|
工具
適用於 PostgreSQL 的 Amazon Relational Database Service (Amazon RDS) 可協助您在 AWS 雲端中設定、操作和擴展 PostgreSQL 關聯式資料庫。
Amazon Aurora PostgreSQL 相容版本是完全受管的 ACID 相容關聯式資料庫引擎,可協助您設定、操作和擴展 PostgreSQL 部署。
AWS Command Line Interface (AWS CLI) 是一種開放原始碼工具,可協助您透過命令列 shell 中的命令與 AWS 服務互動。在此模式中,您可以使用 AWS CLI 透過 pgAdmin 執行 SQL 命令。
pgAdmin
是 PostgreSQL 的開放原始碼管理工具。它提供圖形界面,可協助您建立、維護和使用資料庫物件。 AWS Schema Conversion Tool (AWS SCT) 會自動將來源資料庫結構描述和大部分自訂程式碼轉換為與目標資料庫相容的格式,以支援異質資料庫遷移。
史詩
| 任務 | 描述 | 所需的技能 |
|---|---|---|
識別使用 | 使用 AWS Schema Conversion Tool (AWS SCT) 來識別具有 —或— 在 Oracle 中,使用 | DBA 或開發人員 |
識別參考這些資料表的程式碼。 | 使用 AWS SCT 產生遷移評估報告,以識別受 影響的程序 —或— 在來源 Oracle 資料庫中,使用 | DBA 或開發人員 |
| 任務 | 描述 | 所需的技能 |
|---|---|---|
識別沒有主索引鍵的資料表。 | 在來源 Oracle 資料庫中,使用
| DBA 或開發人員 |
相關資源
PostgreSQL CTID
(PostgreSQL 文件) 產生的資料欄
(PostgreSQL 文件) ROWID 虛擬資料欄
(Oracle 文件)
其他資訊
下列各節提供 Oracle 和 PostgreSQL 程式碼範例,以說明這三種方法。
案例 1:使用主要唯一金鑰
在下列範例中,您會使用 建立testrowid_s1資料表emp_id做為主索引鍵。
Oracle 程式碼:
create table testrowid_s1 (emp_id integer, name varchar2(10), CONSTRAINT testrowid_pk PRIMARY KEY (emp_id)); INSERT INTO testrowid_s1(emp_id,name) values (1,'empname1'); INSERT INTO testrowid_s1(emp_id,name) values (2,'empname2'); INSERT INTO testrowid_s1(emp_id,name) values (3,'empname3'); INSERT INTO testrowid_s1(emp_id,name) values (4,'empname4'); commit; SELECT rowid,emp_id,name FROM testrowid_s1; ROWID EMP_ID NAME ------------------ ---------- ---------- AAAF3pAAAAAAAMOAAA 1 empname1 AAAF3pAAAAAAAMOAAB 2 empname2 AAAF3pAAAAAAAMOAAC 3 empname3 AAAF3pAAAAAAAMOAAD 4 empname4 UPDATE testrowid_s1 SET name = 'Ramesh' WHERE rowid = 'AAAF3pAAAAAAAMOAAB' ; commit; SELECT rowid,emp_id,name FROM testrowid_s1; ROWID EMP_ID NAME ------------------ ---------- ---------- AAAF3pAAAAAAAMOAAA 1 empname1 AAAF3pAAAAAAAMOAAB 2 Ramesh AAAF3pAAAAAAAMOAAC 3 empname3 AAAF3pAAAAAAAMOAAD 4 empname4
PostgreSQL 程式碼:
CREATE TABLE public.testrowid_s1 ( emp_id integer, name character varying, primary key (emp_id) ); insert into public.testrowid_s1 (emp_id,name) values (1,'empname1'),(2,'empname2'),(3,'empname3'),(4,'empname4'); select emp_id,name from testrowid_s1; emp_id | name --------+---------- 1 | empname1 2 | empname2 3 | empname3 4 | empname4 update testrowid_s1 set name = 'Ramesh' where emp_id = 2 ; select emp_id,name from testrowid_s1; emp_id | name --------+---------- 1 | empname1 3 | empname3 4 | empname4 2 | Ramesh
案例 2:使用邏輯主索引鍵
在下列範例中,您會使用 建立資料表testrowid_s2emp_id做為邏輯主索引鍵。
Oracle 程式碼:
create table testrowid_s2 (emp_id integer, name varchar2(10) ); INSERT INTO testrowid_s2(emp_id,name) values (1,'empname1'); INSERT INTO testrowid_s2(emp_id,name) values (2,'empname2'); INSERT INTO testrowid_s2(emp_id,name) values (3,'empname3'); INSERT INTO testrowid_s2(emp_id,name) values (4,'empname4'); commit; SELECT rowid,emp_id,name FROM testrowid_s2; ROWID EMP_ID NAME ------------------ ---------- ---------- AAAF3rAAAAAAAMeAAA 1 empname1 AAAF3rAAAAAAAMeAAB 2 empname2 AAAF3rAAAAAAAMeAAC 3 empname3 AAAF3rAAAAAAAMeAAD 4 empname4 UPDATE testrowid_s2 SET name = 'Ramesh' WHERE rowid = 'AAAF3rAAAAAAAMeAAB' ; commit; SELECT rowid,emp_id,name FROM testrowid_s2; ROWID EMP_ID NAME ------------------ ---------- ---------- AAAF3rAAAAAAAMeAAA 1 empname1 AAAF3rAAAAAAAMeAAB 2 Ramesh AAAF3rAAAAAAAMeAAC 3 empname3 AAAF3rAAAAAAAMeAAD 4 empname4
PostgreSQL 程式碼:
CREATE TABLE public.testrowid_s2 ( emp_id integer, name character varying ); insert into public.testrowid_s2 (emp_id,name) values (1,'empname1'),(2,'empname2'),(3,'empname3'),(4,'empname4'); select emp_id,name from testrowid_s2; emp_id | name --------+---------- 1 | empname1 2 | empname2 3 | empname3 4 | empname4 update testrowid_s2 set name = 'Ramesh' where emp_id = 2 ; select emp_id,name from testrowid_s2; emp_id | name --------+---------- 1 | empname1 3 | empname3 4 | empname4 2 | Ramesh
案例 3:使用身分屬性
在下列範例中,您使用身分屬性建立不含主索引鍵的資料表testrowid_s3。
Oracle 程式碼:
create table testrowid_s3 (name varchar2(10)); INSERT INTO testrowid_s3(name) values ('empname1'); INSERT INTO testrowid_s3(name) values ('empname2'); INSERT INTO testrowid_s3(name) values ('empname3'); INSERT INTO testrowid_s3(name) values ('empname4'); commit; SELECT rowid,name FROM testrowid_s3; ROWID NAME ------------------ ---------- AAAF3sAAAAAAAMmAAA empname1 AAAF3sAAAAAAAMmAAB empname2 AAAF3sAAAAAAAMmAAC empname3 AAAF3sAAAAAAAMmAAD empname4 UPDATE testrowid_s3 SET name = 'Ramesh' WHERE rowid = 'AAAF3sAAAAAAAMmAAB' ; commit; SELECT rowid,name FROM testrowid_s3; ROWID NAME ------------------ ---------- AAAF3sAAAAAAAMmAAA empname1 AAAF3sAAAAAAAMmAAB Ramesh AAAF3sAAAAAAAMmAAC empname3 AAAF3sAAAAAAAMmAAD empname4
PostgreSQL 程式碼:
CREATE TABLE public.testrowid_s3 ( rowid_seq bigint generated always as identity, name character varying ); insert into public.testrowid_s3 (name) values ('empname1'),('empname2'),('empname3'),('empname4'); select rowid_seq,name from testrowid_s3; rowid_seq | name -----------+---------- 1 | empname1 2 | empname2 3 | empname3 4 | empname4 update testrowid_s3 set name = 'Ramesh' where rowid_seq = 2 ; select rowid_seq,name from testrowid_s3; rowid_seq | name -----------+---------- 1 | empname1 3 | empname3 4 | empname4 2 | Ramesh
