從 2025 年 11 月 1 日起,Amazon Redshift 將不再支援建立新的 Python UDFs。如果您想要使用 Python UDFs,請在該日期之前建立 UDFs。現有的 Python UDFs將繼續如常運作。如需詳細資訊,請參閱部落格文章
本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
了解 Amazon Redshift 概念
Amazon Redshift Serverless 可讓您在沒有所佈建資料倉儲的所有組態的情況下,存取和分析資料。系統會自動佈建資源,並有智慧地擴展資料倉儲容量,即使是最嚴苛且無法預測的工作負載,也能為其提供快速的效能。資料倉儲閒置時不會產生費用,因此只需按實際用量支付費用。您可以在 Amazon Redshift 查詢編輯器 v2 或您最愛的商業智慧 (BI) 工具中立即載入資料並開始查詢。在易於使用的零管理環境中,享受最優惠的價格效能和熟悉的 SQL 功能。
如果您是第一次使用 Amazon Redshift,建議您從閱讀下列章節開始:
-
Amazon Redshift Serverless 功能概觀 - 在本主題中,您可以找到 Amazon Redshift Serverless 及其主要功能的概觀。
-
服務重點和定價
- 在此產品詳細資訊頁面上,您可以找到有關 Amazon Redshift Serverless 重點和定價的詳細資訊。 -
開始使用 Amazon Redshift Serverless 資料倉儲. – 在本主題中,您可以進一步了解如何建立 Amazon Redshift Serverless 資料倉儲,以及如何使用查詢編輯器 v2 開始查詢資料。
如果您偏好手動管理 Amazon Redshift 資源,則可以針對資料查詢需求建立佈建叢集。如需詳細資訊,請參閱 Amazon Redshift 叢集。
如果您的組織符合資格,且叢集是在無法使用 Amazon Redshift Serverless AWS 區域 的 中建立,則您可能可以在 Amazon Redshift 免費試用計畫下建立叢集。選擇生產或免費試用來回答問題您打算將此叢集用於什麼目的? 選擇免費試用時,您可以使用 dc2.large 節點類型建立組態。如需選擇免費試用的相關資訊,請參閱 Amazon Redshift 免費試用版
以下是 Amazon Redshift Serverless 的一些關鍵概念。
-
命名空間 – 資料庫物件和使用者的集合。命名空間會將您在 Amazon Redshift Serverless 中使用的所有資源 (例如結構描述、資料表、使用者、資料庫和快照) 群組在一起。
-
工作群組 - 運算資源的集合。工作群組存放 Amazon Redshift Serverless 用來執行運算任務的運算資源。此類資源的一些範例包括 Redshift 處理單元 (RPU)、安全群組、使用限制。工作群組具有網路和安全性設定,您可以使用 Amazon Redshift Serverless 主控台 AWS Command Line Interface、 或 Amazon Redshift Serverless APIs 進行設定。
如需取得規劃命名空間和工作群組資源的相關資訊,請參閱使用命名空間和使用工作群組。
以下是一些關鍵的 Amazon Redshift 佈建的叢集概念:
-
叢集 – Amazon Redshift 資料倉儲的核心基礎設施元件是叢集。
叢集是由一或多個運算節點所組成。運算節點會執行已編譯的程式碼。
如果為叢集佈建了兩個或多個運算節點,則會有另外的領導節點協調運算節點。領導節點可處理與應用程式的外部通訊,例如商業智慧工具和查詢編輯器。您的用戶端應用程式只會直接和領導節點互動,外部應用程式不會知道運算節點的存在。
-
資料庫 – 叢集包含一個或多個資料庫。
使用者資料會儲存在運算節點上的一或多個資料庫中。您的 SQL 用戶端會和領導節點進行通訊,然後再由領導節點統籌使用運算節點的查詢執行作業。如需有關運算節點和領導節點的詳細資訊,請參閱資料倉儲系統架構。在資料庫中,使用者資料會組織成一或多個結構描述。
Amazon Redshift 是關聯式資料庫管理系統 (RDBMS),因此和其他的 RDBMS 應用程式相容。它提供與典型 RD BMS 相同的功能 (包括線上交易處理 (OLTP) 功能,例如插入和刪除資料)。Amazon Redshift 也針對資料集的高效能批次分析和報告進行了最佳化。
接下來,您可以在 Amazon Redshift 中找到典型資料處理流程的說明,以及流程不同部分的說明。如需 Amazon Redshift 系統架構的詳細資訊,請參閱資料倉儲系統架構。
下圖說明 Amazon Redshift 中的典型資料處理流程。
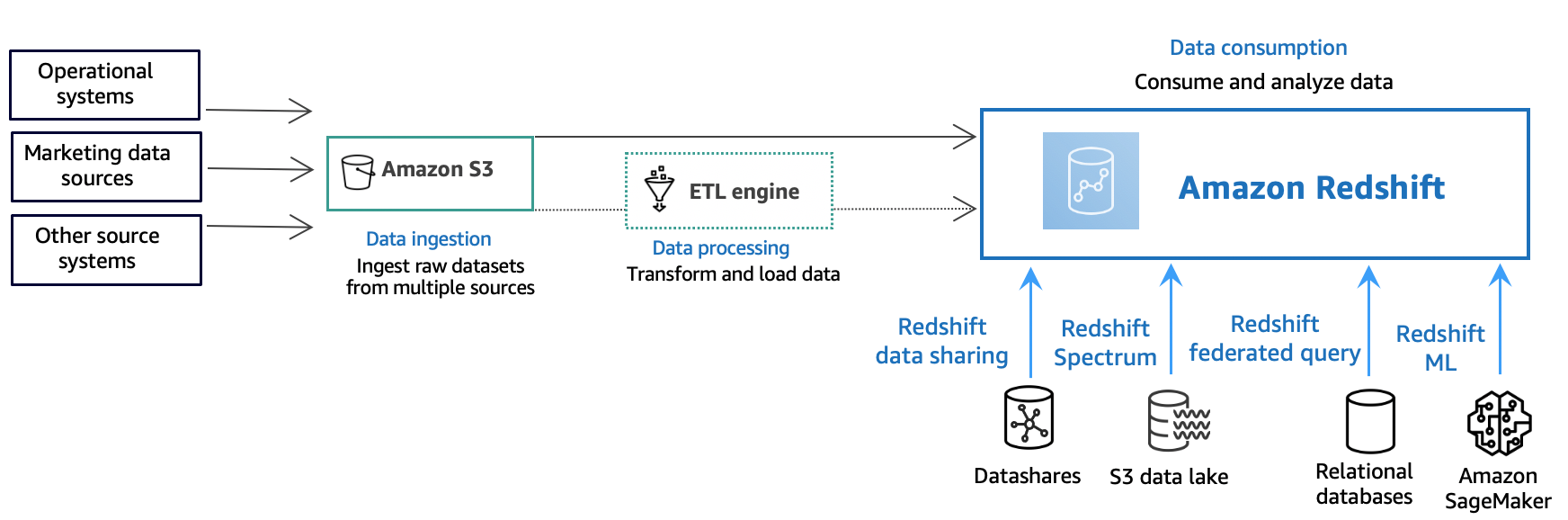
Amazon Redshift 資料倉儲是企業級的關聯式資料庫查詢與管理系統。Amazon Redshift 透過多種類型的應用程式來支援用戶端連線,包括商業智慧 (BI)、報告、資料與分析工具。執行分析查詢時,會以多階段操作的方式,擷取、比較和評估大量的資料,來產生最終的結果。
在資料擷取層,不同類型的資料來源會持續將結構化、半結構化或非結構化資料上傳至資料儲存層。此資料儲存區域可做為暫存區,以不同的使用準備狀態儲存資料。儲存的範例可能是 Amazon Simple Storage Service (Amazon S3) 儲存貯體。
在可選資料處理層,來源資料會使用擷取、轉換、載入 (ETL) 或擷取、載入、轉換 (ELT) 管線進行預處理、驗證和轉換。然後使用 ETL 操作對這些原始資料集進行細化。ETL 引擎的一個範例是 AWS Glue。
在資料消耗層,資料會載入您的 Amazon Redshift 叢集,您可以在其中執行分析工作負載。
如需分析工作負載的一些範例,請參閱查詢外部資料來源。
