自 2025 年 11 月 1 日起,Amazon Redshift 將不再支援建立新的 Python UDFs。如果您想要使用 Python UDFs,請在該日期之前建立 UDFs。現有的 Python UDFs將繼續如常運作。如需詳細資訊,請參閱部落格文章
本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
開始使用 Amazon Redshift Serverless 資料倉儲
若您是 Amazon Redshift Serverless 新手,建議您閱讀以下章節,以協助您開始使用 Amazon Redshift Serverless。Amazon Redshift Serverless 的基本流程是建立無伺服器資源、連接到 Amazon Redshift Serverless、載入範例資料,然後對資料執行查詢。在本指南中,您可以選擇從 Amazon Redshift Serverless 或從 Amazon S3 儲存貯體載入範例資料。範例資料會在 Amazon Redshift 文件中使用,以示範 功能。若要開始使用 Amazon Redshift 佈建的資料倉儲,請參閱 開始使用 Amazon Redshift 佈建的資料倉儲。
註冊 AWS
如果您還沒有 AWS 帳戶,請註冊一個帳戶。如果您已有帳戶,則可略過此事前準備,並使用現有的帳戶。
請遵循線上指示進行。
當您註冊 AWS 帳戶時,會建立 AWS 帳戶根使用者。根使用者可存取帳戶中的所有 AWS 服務和資源。作為安全最佳實務,將管理存取權指派給管理使用者,並且僅使用根使用者來執行需要根使用者存取權的任務。
使用 Amazon Redshift Serverless 建立資料倉儲
第一次登入 Amazon Redshift Serverless 主控台時,系統會提示您存取入門體驗,您可以使用該體驗來建立和管理無伺服器資源。在本指南中,您將使用 Amazon Redshift Serverless 的預設設定來建立無伺服器資源。
若要更精細地控制您的設定,請選擇自訂設定。
注意
Redshift Serverless 需要三個不同可用區域中具有三個子網路的 Amazon VPC。Redshift Serverless 也需要至少 3 個可用的 IP 地址。請確定您用於 Redshift Serverless 的 Amazon VPC 在三個不同的可用區域中有三個子網路,以及至少 3 個可用的 IP 地址,然後再繼續。如需在 Amazon VPC 中建立子網路的詳細資訊,請參閱《Amazon Virtual Private Cloud 使用者指南》中的建立子網路。如需 Amazon VPC 中 IP 地址的詳細資訊,請參閱 VPCs和子網路的 IP 定址。
若要使用預設設定進行設定:
登入 AWS Management Console ,並在 https://console.aws.amazon.com/redshiftv2/
:// 開啟 Amazon Redshift 主控台。 選擇嘗試 Redshift Serverless 免費試用。
-
在組態下選擇使用預設設定。Amazon Redshift Serverless 會建立預設命名空間,其中包含與此命名空間相關聯的預設工作群組。選擇 Save configuration (儲存組態)。
注意
命名空間是資料庫物件和使用者的集合。命名空間會將您在 Redshift Serverless 中使用的所有資源分組在一起,例如結構描述、資料表、使用者、資料共用和快照。
Workgroup 是運算資源的集合。工作群組包含 Redshift Serverless 用來執行運算任務的運算資源。
下列螢幕擷取畫面顯示 Amazon Redshift Serverless 的預設設定。
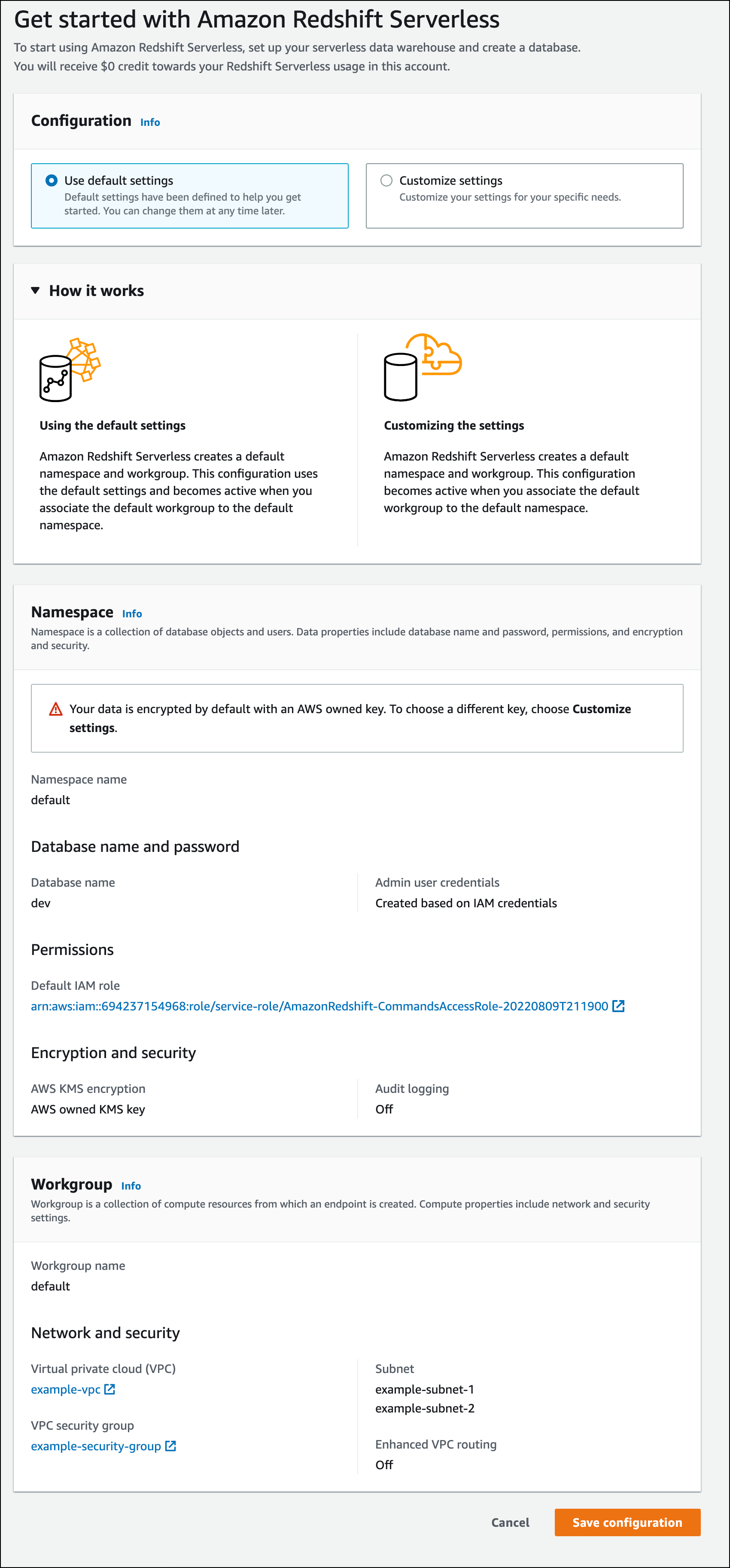
-
設定完成後,選擇繼續以前往您的Serverless 儀表板。您可以看到無伺服器工作群組和命名空間可用。
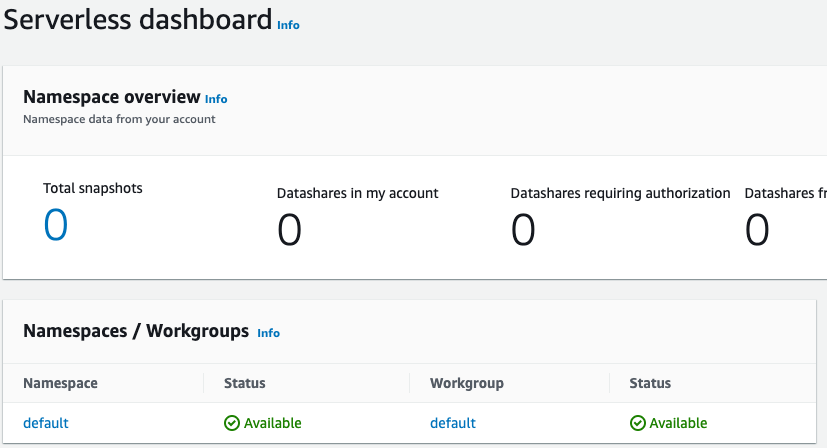
注意
如果 Redshift Serverless 未成功建立工作群組,您可以執行下列動作:
解決 Redshift Serverless 報告的任何錯誤,例如 Amazon VPC 中的子網路太少。
在 Redshift Serverless 儀表板中選擇預設命名空間,然後選擇動作、刪除命名空間,以刪除命名空間。刪除命名空間需要幾分鐘的時間。
當您再次開啟 Redshift Serverless 主控台時,會顯示歡迎畫面。
載入範例資料
現在您已經使用 Amazon Redshift Serverless 設定資料倉儲,您可以使用 Amazon Redshift 查詢編輯器 v2 載入範例資料。
-
若要從 Amazon Redshift Serverless 主控台啟動查詢編輯器 v2,請選擇查詢資料。當您從 Amazon Redshift Serverless 主控台調用查詢編輯器 v2 時,新的瀏覽器索引標籤會開啟並顯示查詢編輯器。查詢編輯器 v2 會從您的用戶端機器連線到 Amazon Redshift Serverless 環境。
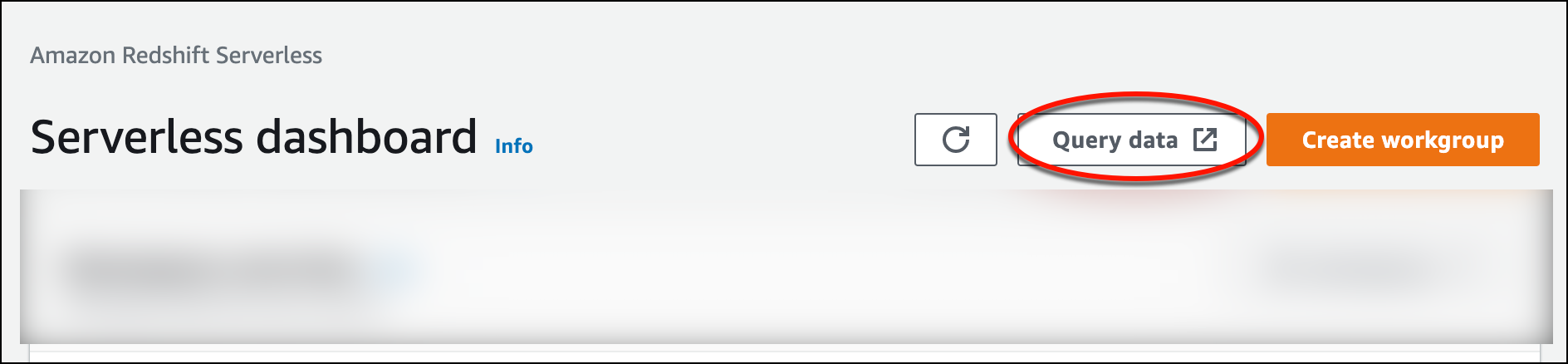
-
針對本指南,您將使用您的 AWS 管理員帳戶和預設值 AWS KMS key。如需有關設定查詢編輯器 v2 的資訊,包括需要哪些許可,請參閱《Amazon Redshift 管理指南》中的設定您的 AWS 帳戶 。如需有關將 Amazon Redshift 設定為使用客戶受管金鑰,或變更 Amazon Redshift 使用的 KMS 金鑰的詳細資訊,請參閱變更命名空間的 AWS KMS 金鑰。
-
若要連接至工作群組,請在樹狀檢視面板中選擇工作群組名稱。

-
第一次在查詢編輯器 v2 中連線至新工作群組時,您必須選取要用於連線至工作群組的驗證類型。在本指南中,請保持聯合身分使用者為選取狀態,然後選擇建立連線。
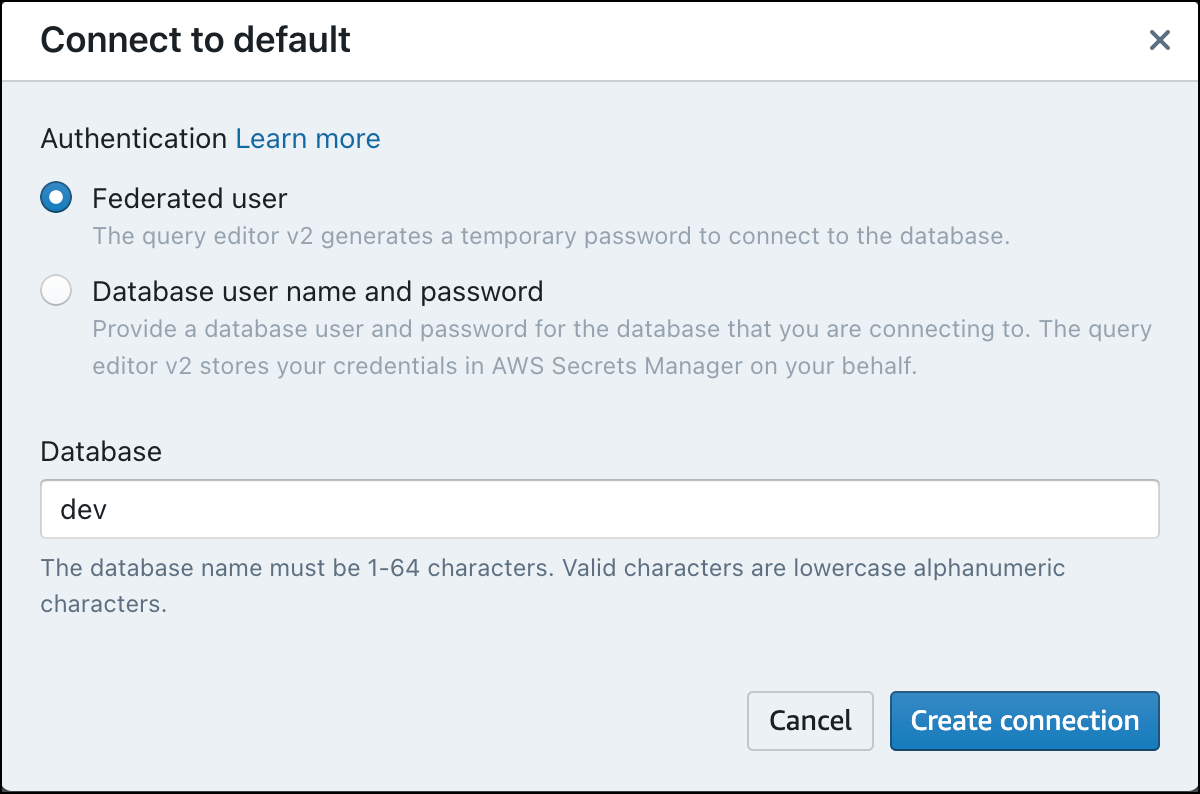
連線之後,您可以選擇從 Amazon Redshift Serverless 或從 Amazon S3 儲存貯體載入範例資料。
-
在 Amazon Redshift Serverless 預設工作群組下,展開 sample_data_dev 資料庫。有三個範例結構描述與三個範例資料集相對應,您可以將這些範例資料集載入 Amazon Redshift Serverless 資料庫。選擇您要載入的範例資料集,然後選擇開啟範例筆記本。
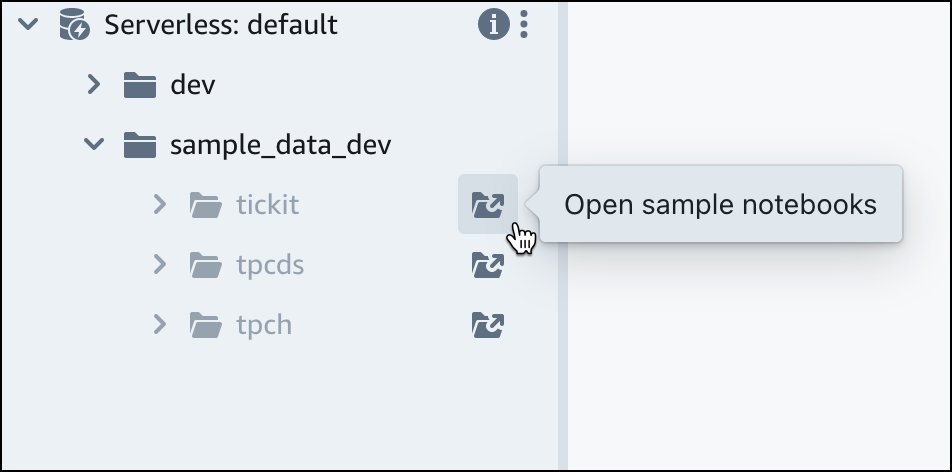
注意
SQL 筆記本是 SQL 和 Markdown 儲存格的容器。您可以使用筆記本在單一文件中組織、註釋和共用多個 SQL 命令。
-
第一次載入資料時,查詢編輯器 v2 會提示您建立範例資料庫。選擇建立。

執行範例查詢
設定 Amazon Redshift Serverless 之後,您就可以開始在 Amazon Redshift Serverless 中使用範例資料集。Amazon Redshift Serverless 會自動載入範例資料集 (例如 tickit 資料集),而且您可以立即查詢資料。
-
Amazon Redshift Serverless 完成範例資料的載入後,所有範例查詢都會載入到編輯器中。您可以選擇全部執行,從範例筆記本執行所有查詢。
![選擇 [全部執行] 按鈕以執行所有範例查詢。](images/serverless-running-sample-notebook.png)
您也可以將結果匯出為 JSON 或 CSV 檔案,或在圖表中檢視結果。

您亦可從 Amazon S3 儲存貯體載入資料。如需進一步了解,請參閱從 Amazon S3 載入資料。
從 Amazon S3 載入資料
建立資料倉儲之後,您可以從 Amazon S3 載入資料。
此時,您已經有了一個名為 dev 的資料庫。接下來,您會在資料庫中建立一些資料表、將資料上傳至資料表,然後嘗試執行查詢。為方便起見,在 Amazon S3 儲存貯體中會提供您載入的範例資料。
-
您必須先建立具有必要權限的 IAM 角色,然後將其附加至無伺服器命名空間,才能從 Amazon S3 載入資料。若要這麼做,請返回 Redshift Serverless 主控台,然後選擇命名空間組態。從導覽功能表中,選擇您的命名空間,然後選擇安全和加密。選擇管理 IAM 角色。
![在命名空間設定頁面中,選擇 [安全和加密],然後選擇 [管理 IAM 角色]。](images/serverless-namespace-configuration.png)
展開管理 IAM 角色功能表,然後選擇建立 IAM 角色。
![展開 [管理 IAM 角色] 功能表,然後選擇 [建立 IAM 角色]。](images/serverless-manage-iam-role.png)
選擇您要授與此角色的 S3 儲存貯體存取層級,然後選擇建立 IAM 角色做為預設值。

-
選擇儲存變更。您現在可以從 Amazon S3 載入範例資料。
下列步驟會使用公有 Amazon Redshift S3 儲存貯體內的資料,但是您可以使用自己的 S3 儲存貯體和 SQL 命令複寫相同的步驟。
從 Amazon S3 載入範例資料
-
在查詢編輯器 v2 中,選擇
 [新增],然後選擇筆記本以建立新的 SQL 筆記本。
[新增],然後選擇筆記本以建立新的 SQL 筆記本。
-
切換到
dev資料庫。
-
建立資料表。
如果您使用查詢編輯器 v2,請複製並執行以下建立資料表陳述式,以在
dev資料庫中建立資料表。如需語法的相關資訊,請參閱《Amazon Redshift 資料庫開發人員指南》中的 CREATE TABLE。create table users( userid integer not null distkey sortkey, username char(8), firstname varchar(30), lastname varchar(30), city varchar(30), state char(2), email varchar(100), phone char(14), likesports boolean, liketheatre boolean, likeconcerts boolean, likejazz boolean, likeclassical boolean, likeopera boolean, likerock boolean, likevegas boolean, likebroadway boolean, likemusicals boolean); create table event( eventid integer not null distkey, venueid smallint not null, catid smallint not null, dateid smallint not null sortkey, eventname varchar(200), starttime timestamp); create table sales( salesid integer not null, listid integer not null distkey, sellerid integer not null, buyerid integer not null, eventid integer not null, dateid smallint not null sortkey, qtysold smallint not null, pricepaid decimal(8,2), commission decimal(8,2), saletime timestamp); -
在查詢編輯器 v2 中,在筆記本中建立新的 SQL 儲存格。
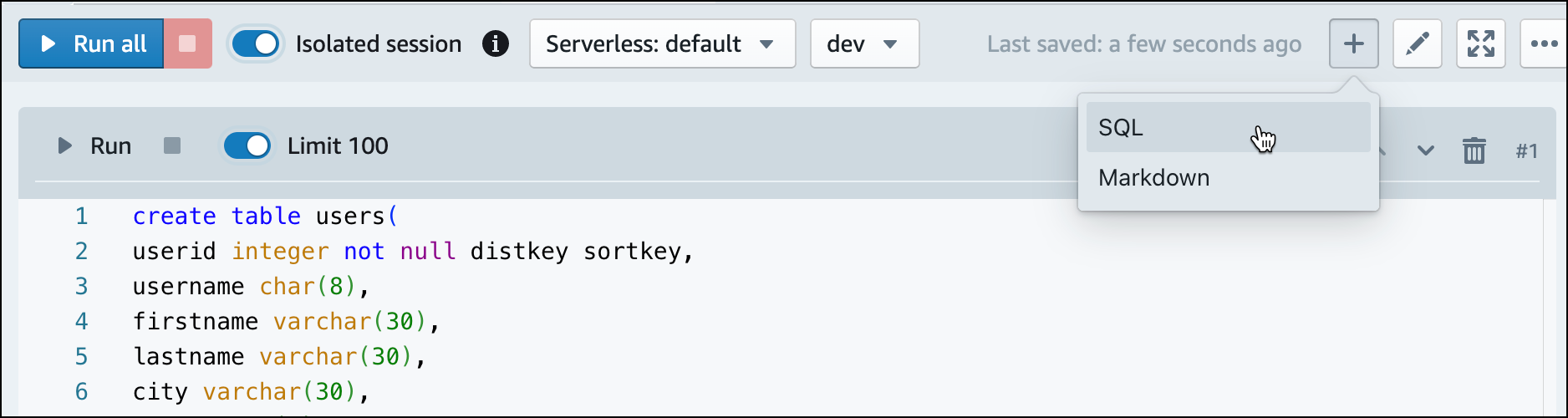
-
現在,使用查詢編輯器 v2 中的 COPY 命令,將大型資料集從 Amazon S3 或 Amazon DynamoDB 載入到 Amazon Redshift。如需 COPY 語法的相關資訊,請參閱《Amazon Redshift 資料庫開發人員指南》中的 COPY。
您可以使用公有 S3 儲存貯體中提供的一些範例資料來執行 COPY 命令。在查詢編輯器 v2 中執行下列 SQL 命令。
COPY users FROM 's3://redshift-downloads/tickit/allusers_pipe.txt' DELIMITER '|' TIMEFORMAT 'YYYY-MM-DD HH:MI:SS' IGNOREHEADER 1 REGION 'us-east-1' IAM_ROLE default; COPY event FROM 's3://redshift-downloads/tickit/allevents_pipe.txt' DELIMITER '|' TIMEFORMAT 'YYYY-MM-DD HH:MI:SS' IGNOREHEADER 1 REGION 'us-east-1' IAM_ROLE default; COPY sales FROM 's3://redshift-downloads/tickit/sales_tab.txt' DELIMITER '\t' TIMEFORMAT 'MM/DD/YYYY HH:MI:SS' IGNOREHEADER 1 REGION 'us-east-1' IAM_ROLE default; -
載入資料後,請在筆記本中建立另一個 SQL 儲存格,並嘗試一些範例查詢。如需使用 SELECT 命令的相關資訊,請參閱《Amazon Redshift 開發人員指南》中的 SELECT。若要瞭解範例資料的結構和結構描述,請使用查詢編輯器 v2 進行探索。
-- Find top 10 buyers by quantity. SELECT firstname, lastname, total_quantity FROM (SELECT buyerid, sum(qtysold) total_quantity FROM sales GROUP BY buyerid ORDER BY total_quantity desc limit 10) Q, users WHERE Q.buyerid = userid ORDER BY Q.total_quantity desc; -- Find events in the 99.9 percentile in terms of all time gross sales. SELECT eventname, total_price FROM (SELECT eventid, total_price, ntile(1000) over(order by total_price desc) as percentile FROM (SELECT eventid, sum(pricepaid) total_price FROM sales GROUP BY eventid)) Q, event E WHERE Q.eventid = E.eventid AND percentile = 1 ORDER BY total_price desc;
現在您已載入資料並執行了一些範例查詢,您可以探索 Amazon Redshift Serverless 的其他區域。請參閱下列清單,進一步了解如何使用 Amazon Redshift Serverless。
-
您可以從 Amazon S3 儲存貯體載入資料。如需詳細資訊,請參閱從 Amazon S3 載入資料。
-
您可以使用查詢編輯器 v2,從小於 5 MB 的本機字元分隔檔案載入資料。如需詳細資訊,請參閱從本機檔案載入資料。
-
您可以使用第三方 SQL 工具使用 JDBC 和 ODBC 驅動程式連線到 Amazon Redshift Serverless。如需詳細資訊,請參閱連線至 Amazon Redshift Serverless。
-
您也可以使用 Amazon Redshift 資料 API 連接到 Amazon Redshift Serverless。如需詳細資訊,請參閱使用 Amazon Redshift 資料 API
。 -
您可以將 Amazon Redshift Serverless 中的資料與 Redshift ML 搭配使用,透過 CREATE MODEL 命令建立機器學習模型。請參閱教學課程:建立客戶流失模型,以了解如何建立 Redshift ML 模型。
-
您可以從 Amazon S3 資料湖查詢資料,而無需將任何資料載入 Amazon Redshift Serverless。如需詳細資訊,請參閱查詢資料湖。
