本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
IAM 存取管理
下列各節說明 Amazon SageMaker 管道的 AWS Identity and Access Management (IAM) 要求。有關如何實現這些權限的範例,請參閱先決條件。
管道角色許可
您的管道需要 IAM 管道執行角色,該角色會在您建立管道時傳遞至管道。建立管道的 SageMaker AI 執行個體的角色必須具有iam:PassRole管道執行角色的許可,才能傳遞它。如需 IAM 角色的詳細資訊,請參閱 IAM 角色。
您的管道執行角色需要下列許可:
-
若要將任何角色傳遞至管道中的 SageMaker AI 任務,則為
iam:PassRole要傳遞之角色的許可。 -
管道中每個任務類型
Create和Describe許可。 -
使用
JsonGet函式的 Amazon S3 許可。您可以控制哪些使用者有權使用以資源為基礎的政策或以身分為基礎的政策來存取 Amazon S3 資源。以資源為基礎的政策會套用至您的 Amazon S3 儲存貯體,並授予管道對儲存貯體的存取權。以身分為基礎的政策可讓您的管道從您的帳戶發起 Amazon S3 呼叫。如需有關以資源為基礎的政策和以身分為基礎的政策的詳細資訊,請參閱以身分為基礎的政策和以資源為基礎的政策。{ "Action": [ "s3:GetObject" ], "Resource": "arn:aws:s3:::<your-bucket-name>/*", "Effect": "Allow" }
管道步驟許可
管道包含執行 SageMaker AI 任務的步驟。為了讓管道步驟執行這些任務,這些管道需要在您的帳戶中具有 IAM 角色,以提供所需資源的存取許可。您的管道會將此角色傳遞給 SageMaker AI 服務主體。如需 IAM 角色的詳細資訊,請參閱 IAM 角色。
依預設,每個步驟都具有管道執行角色。您可以選擇性地將不同的角色傳遞給管道中的任何步驟。這可確保每個步驟中的程式碼不會影響其他步驟中使用的資源,除非管道定義中指定的兩個步驟之間有直接關係。您可以在定義步驟的處理器或估算器時傳遞這些角色。如需如何在這些定義中包含這些角色的範例,請參閱 SageMaker AI Python SDK 文件
使用 Amazon S3 儲存貯體的 CORS 組態
若要確保您的映像以可預測的方式從 Amazon S3 儲存貯體匯入管道,必須將 CORS 組態新增至匯入映像的 Amazon S3 儲存貯體。本節說明如何將所需的 CORS 組態設定為 Amazon S3 儲存貯體。管道CORSConfiguration所需的 XML 與 中的 XML 不同輸入影像資料的 CORS 需求,否則您可以使用其中的資訊來進一步了解 Amazon S3 儲存貯體的 CORS 需求。
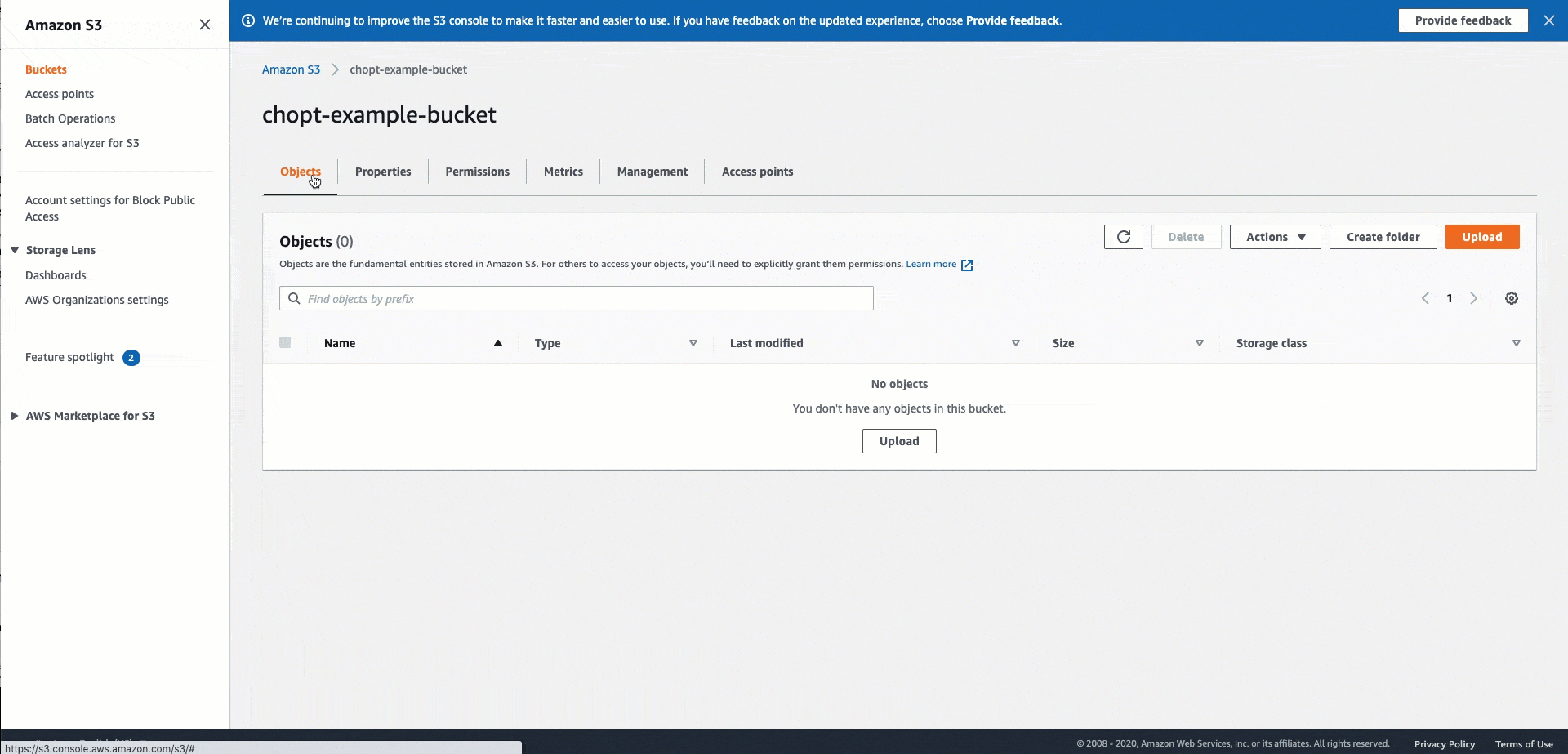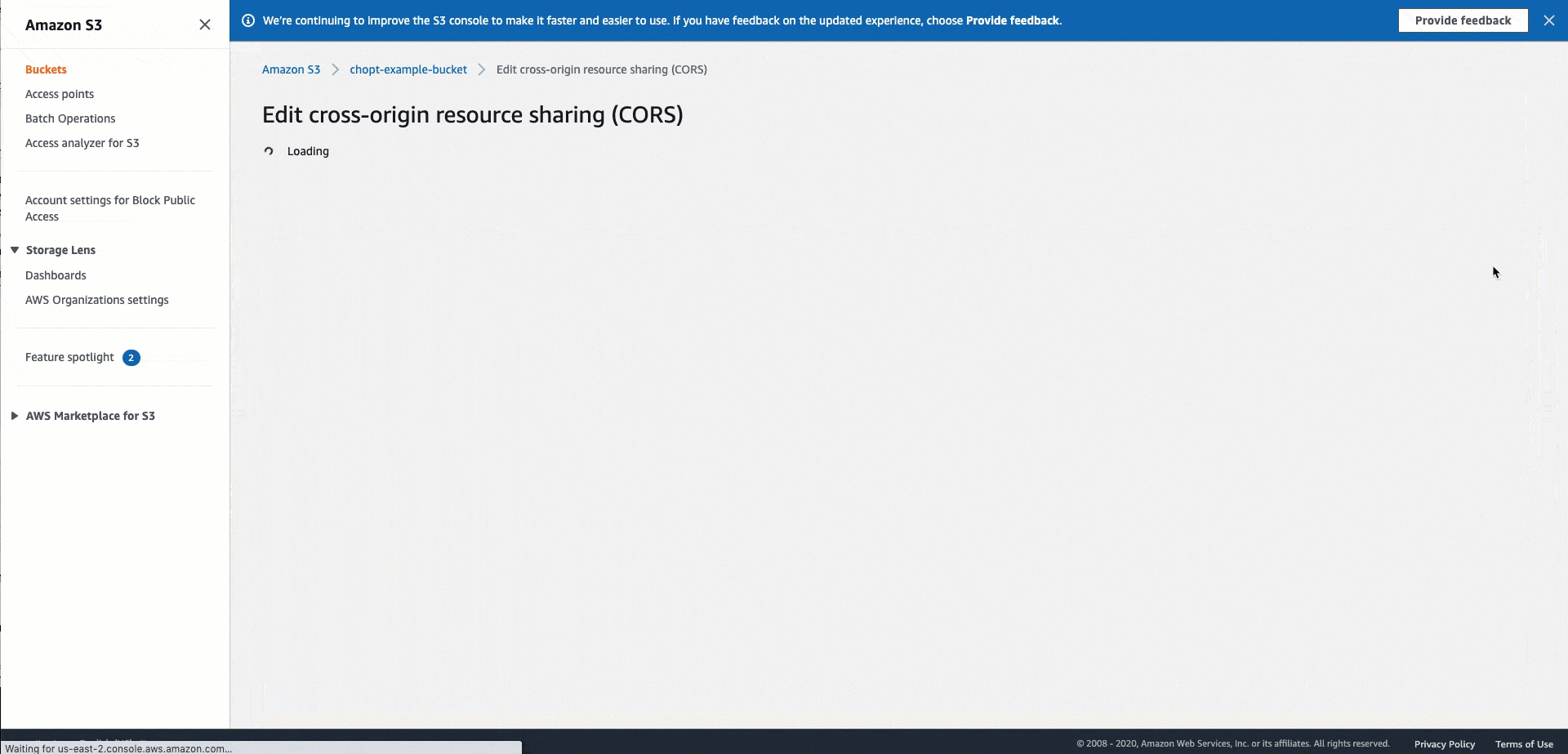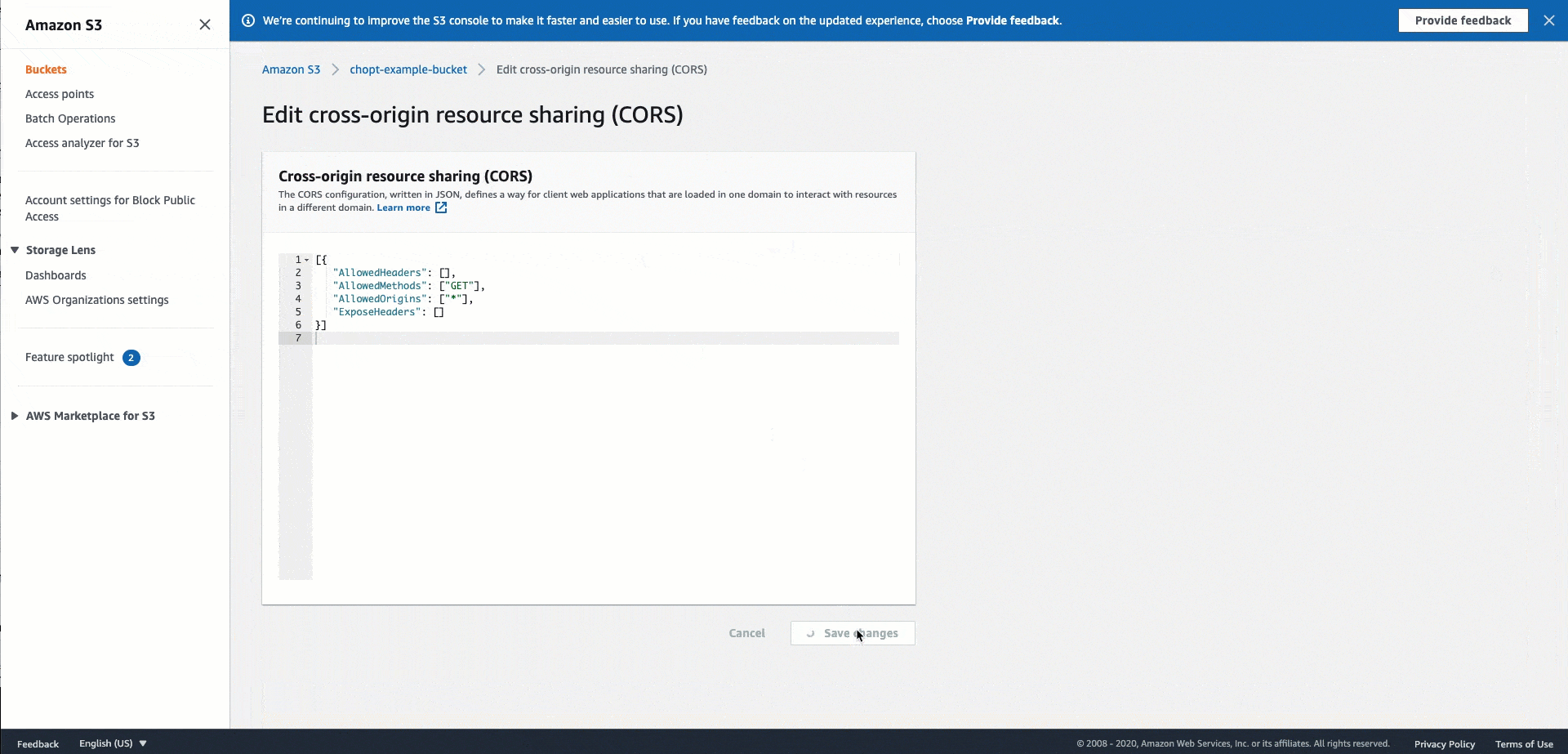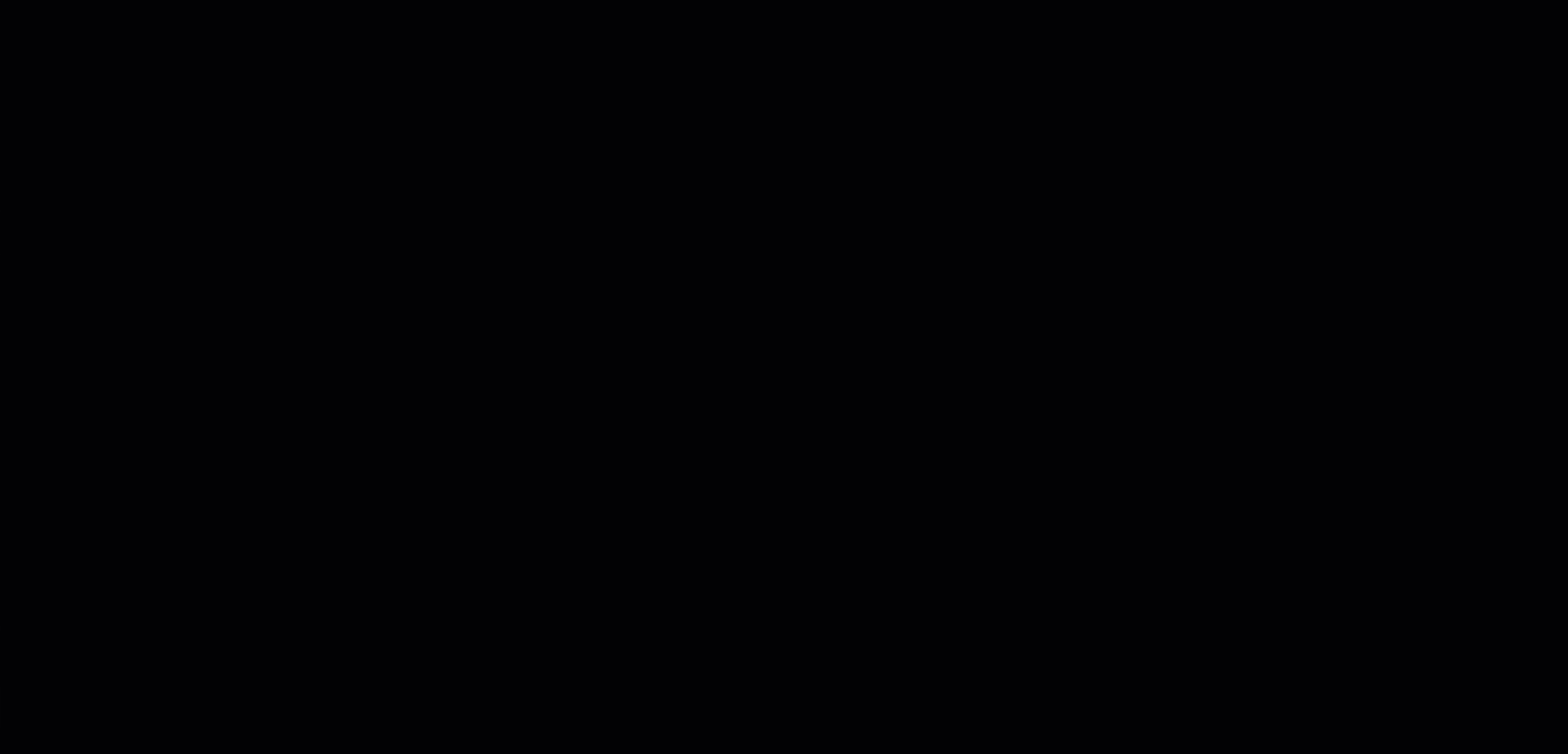
針對託管映像的 Amazon S3 儲存貯體使用下列 CORS 組態代碼。如需設定 CORS 的指示,請參閱《Amazon Simple Storage Service 使用者指南》中的設定跨來源資源共用 (CORS)。如果您使用 Amazon S3 主控台,將政策新增至儲存貯體,則必須使用 JSON 格式。
JSON
[ { "AllowedHeaders": [ "*" ], "AllowedMethods": [ "PUT" ], "AllowedOrigins": [ "*" ], "ExposeHeaders": [ "Access-Control-Allow-Origin" ] } ]
XML
<CORSConfiguration> <CORSRule> <AllowedHeader>*</AllowedHeader> <AllowedOrigin>*</AllowedOrigin> <AllowedMethod>PUT</AllowedMethod> <ExposeHeader>Access-Control-Allow-Origin</ExposeHeader> </CORSRule> </CORSConfiguration>
若要使用 Amazon S3 主控台新增 CORS 標題政策,下列 GIF 會示範在 Amazon S3 文件中找到的指示。
自訂管道任務的存取管理
您可以進一步自訂 IAM 政策,以便您的組織中選定的成員可以執行任何或所有管道步驟。例如,您可以授予特定使用者建立訓練任務的許可,以及另一組使用者建立處理任務的許可,以及所有使用者執行剩餘步驟的許可。要使用此功能,您可以選擇一個自訂字串,其字首位您的任務名稱。您的管理員在允許的 ARN 前面加上字首,而您的資料科學家在管道執行個體中包含此字首。由於允許使用者的 IAM 政策包含具有指定字首的任務 ARN,因此管道步驟的後續任務要有必要的許可才能繼續。任務字首預設為關閉 – 您必須在 Pipeline 類別中開啟此選項才能使用它。
對於關閉字首的任務,任務名稱的格式如圖所示,並且是下表所述欄位的串連:
pipelines-<executionId>-<stepNamePrefix>-<entityToken>-<failureCount>
| 欄位 | 定義 |
|---|---|
|
管道 |
靜態字串始終在前面。此字串會將管道協同運作服務識別為任務的來源。 |
|
executionId |
管道執行中執行個體的隨機緩衝區。 |
|
stepNamePrefix |
使用者指定的步驟名稱 (在管道步驟的 |
|
entityToken |
一個隨機的權杖,用於確保步驟實體的等冪性。 |
|
failureCount |
目前嘗試完成任務的重試次數。 |
在此情況下,任務名稱前面不會加上自訂字首,且對應的 IAM 政策必須與此字串相符。
對於開啟任務字首的使用者,基礎任務名稱會採用下列格式,並將自訂字首指定為 MyBaseJobName:
<MyBaseJobName>-<executionId>-<entityToken>-<failureCount>
自訂字首會取代靜態pipelines字串,以協助您縮小可做為管道一部分執行 SageMaker AI 任務之使用者的選取範圍。
字首長度限制
任務名稱具有特定於個別管道步驟的內部長度限制。此約束也會限制允許字首的長度。字首長度要求如下:
| 管道步驟 | 字首長度 |
|---|---|
|
|
38 |
|
6 |
將任務字首套用至 IAM 政策
您的管理員會建立 IAM 政策,允許特定字首的使用者建立任務。下列範例正策允許資料科學家在使用 MyBaseJobName 字首時建立訓練任務。
{ "Action": "sagemaker:CreateTrainingJob", "Effect": "Allow", "Resource": [ "arn:aws:sagemaker:region:account-id:*/MyBaseJobName-*" ] }
將任務字首套用至管道建立
您可以使用任務執行個體類別的 *base_job_name 引數來指定字首。
注意
您可以在建立管道步驟之前,將任務字首和 *base_job_name 引數傳遞至人任務執行個體。此任務執行個體包含任務在管道中作為步驟執行的必要資訊。此引數會根據使用的任務執行個體而有所不同。下列清單顯示每個管道步驟類型要使用的引數:
-
對於
Estimator(TrainingStep)、Processor(ProcessingStep) 和AutoML(AutoMLStep) 類別,引數為base_job_name -
對於
Tuner(TuningStep) 類別,引數為tuning_base_job_name -
對於
Transformer(TransformStep) 類別,引數為transform_base_job_name -
對於
QualityCheckStep(品質檢查) 和ClarifyCheckstep(澄清檢查) 類別,引數為CheckJobConfig中的base_job_name -
對於
Model類別,使用的引數取決於將結果傳遞給ModelStep之前在模型上執行的是create還是register-
如果您呼叫
create,則自訂字首來自構造模型時的name引數 (即Model(name=)) -
如果您呼叫
register,則自訂字首來自您呼叫register的model_package_name引數 (即my_model.register(model_package_name=)
-
以下範例顯示如何指定新訓練任務執行個體的字首。
# Create a job instance xgb_train = Estimator( image_uri=image_uri, instance_type="ml.m5.xlarge", instance_count=1, output_path=model_path, role=role, subnets=["subnet-0ab12c34567de89f0"], base_job_name="MyBaseJobName" security_group_ids=["sg-1a2bbcc3bd4444e55"], tags = [ ... ] encrypt_inter_container_traffic=True, ) # Attach your job instance to a pipeline step step_train = TrainingStep( name="TestTrainingJob", estimator=xgb_train, inputs={ "train": TrainingInput(...), "validation": TrainingInput(...) } )
任務字首依預設處於關閉狀態。若要選擇使用此功能,請使用 PipelineDefinitionConfig 的 use_custom_job_prefix 選項,如下列程式碼片段所示:
from sagemaker.workflow.pipeline_definition_config import PipelineDefinitionConfig # Create a definition configuration and toggle on custom prefixing definition_config = PipelineDefinitionConfig(use_custom_job_prefix=True); # Create a pipeline with a custom prefix pipeline = Pipeline( name="MyJobPrefixedPipeline", parameters=[...] steps=[...] pipeline_definition_config=definition_config )
建立並執行管道。下列範例會建立並執行管道,並示範如何關閉任務字首並重新執行管道。
pipeline.create(role_arn=sagemaker.get_execution_role()) # Optionally, call definition() to confirm your prefixed job names are in the built JSON pipeline.definition() pipeline.start() # To run a pipeline without custom-prefixes, toggle off use_custom_job_prefix, update the pipeline # via upsert() or update(), and start a new run definition_config = PipelineDefinitionConfig(use_custom_job_prefix=False) pipeline.pipeline_definition_config = definition_config pipeline.update() execution = pipeline.start()
同樣,您可以開啟現有管道的功能,並啟動使用任務字首的新執行。
definition_config = PipelineDefinitionConfig(use_custom_job_prefix=True) pipeline.pipeline_definition_config = definition_config pipeline.update() execution = pipeline.start()
最後,您可以透過呼叫管道執行 list_steps 來查看自訂字首的任務。
steps = execution.list_steps() prefixed_training_job_name = steps['PipelineExecutionSteps'][0]['Metadata']['TrainingJob']['Arn']
自訂管道版本的存取權
您可以使用 sagemaker:PipelineVersionId條件金鑰,授予特定版本的 Amazon SageMaker Pipelines 的自訂存取權。例如,以下政策僅授予版本 ID 6 及更高版本啟動執行或更新管道版本的存取權。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "AllowStartPipelineExecution", "Effect": "Allow", "Action": [ "sagemaker:StartPipelineExecution", "sagemaker:UpdatePipelineVersion" ], "Resource": "*", "Condition": { "NumericGreaterThanEquals": { "sagemaker:PipelineVersionId": 6 } } } }
如需支援的條件金鑰的詳細資訊,請參閱 Amazon SageMaker AI 的條件金鑰。
服務控制政策與 Pipelines
服務控制政策 (SCP) 是一種組織政策類型,可用來管理您的組織中的許可。SCP 可集中控制組織中所有帳戶可用的許可上限。透過在組織內使用管道,您可以確保資料科學家管理您的管道執行,而不必與 AWS 主控台互動。
如果您將 VPC 與 SCP 搭配使用來限制對 Amazon S3 的存取,則需要採取措施來允許管道存取其他 Amazon S3 資源。
若要允許管道使用 JsonGet函數在 VPC 外部存取 Amazon S3,請更新組織的 SCP,以確保使用管道的角色可以存取 Amazon S3。若要這樣做,請使用主體標籤和條件索引鍵,為管道執行器透過管道執行角色使用的角色建立例外狀況。
允許管道在 VPC 外部存取 Amazon S3
-
按照標記 IAM 使用者和角色中的步驟,為您的管道執行角色建立唯一標籤。
-
使用您建立之標籤的
Aws:PrincipalTag IAM條件索引鍵,在 SCP 中授予例外狀況。有關詳細資訊,請參閱建立、更新和刪除服務控制策略。
