本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
自動化資料標籤
如果您選擇這麼做,Amazon SageMaker Ground Truth 可以使用主動學習功能,自動化將特定內建任務類型的輸入資料加上標籤。主動學習是一種機器學習技術,可識別應由您工作者標籤的資料。在 Ground Truth 中,此功能稱為自動化資料標籤。相較於人工,自動資料標籤有助於降低標籤資料集所需的成本和時間。使用自動化標籤時,會產生 SageMaker 訓練和推論成本。
建議您對大型資料集使用自動資料標籤,因為與主動學習搭配使用的神經網路需要每個新資料集都有大量資料。通常,提供越多資料,高準確性預測的可能性就會隨之增加。只有在自動標籤模型中使用的神經網路可以實現可接受的高準確度時,才會自動標籤資料。因此,資料集越大,就越有可能自動標籤資料,因為神經網路可以實現足夠高的準確度進行自動標籤。當您擁有數千個資料物件時,自動資料標籤最為合適。自動資料標籤允許的物件數目下限為 1,250,但強烈建議您至少提供 5,000 個物件。
自動資料標籤僅適用於下列 Ground Truth 內建任務類型:
串流標籤工作不支援自動化資料標籤。
若要了解如何使用您自己的模型來建立自訂主動式學習工作流程,請參閱使用您自己的模型,設定主動學習工作流程。
輸入資料配額適用於自動資料標籤工作。如需資料集大小、輸入資料大小和解析度限制的資訊,請參閱輸入資料配額。
注意
在生產中使用自動化標籤模型之前,您需要對其進行微調或測試,或兩者皆有。您可以在標籤工作產生的資料集上微調模型 (或建立和調校您選擇的另一個監督模型),以最佳化模型的架構和超參數。如果您決定不微調而直接使用模型進行推論,則強烈建議務必根據 Ground Truth 所標籤之資料集的代表性 (例如,隨機選取) 子集來評估其準確性,而且符合您的預期。
運作方式
您可以在建立標籤工作時啟用自動資料標籤。以下是此選項的運作方式:
-
當 Ground Truth 啟動自動資料標籤工作時,它會選取輸入資料 (物件) 的隨機樣本,然後將樣本傳送給人力工作者。如果超過 10% 的資料物件失敗,標籤工作將會失敗。如果標籤工作失敗,除了檢視 Ground Truth 傳回的任何錯誤訊息外,請檢查您的輸入資料是否正確顯示在工作者使用者介面中、指示是否清楚,以及您是否給予工作者足夠的時間來完成任務。
-
標籤資料傳回後,將會用來建立訓練集和驗證集。Ground Truth 使用這些資料集來訓練和驗證用於自動標籤的模型。
-
Ground Truth 會執行批次轉換工作,使用已驗證的模型,對驗證資料進行推論。批次推論會為驗證資料中的每個物件產生可信度分數和品質指標。
-
自動標籤元件將使用這些品質指標和可信度分數,來建立可信度分數閾值,以確保標籤品質無虞。
-
Ground Truth 會在資料集中未標籤的資料上執行批次轉換任務,並使用相同的驗證模型進行推論。這將產生每個物件的可信度分數。
-
Ground Truth 自動標籤元件會決定步驟 5 中為每個物件產生的可信度分數是否符合步驟 4 所決定的必要閾值。如果可信度分數符合閾值,預期的自動標籤品質會超過已請求的準確度,且該物件會被視為已自動標籤。
-
步驟 6 生成具有可信度分數的未標籤資料的資料集。Ground Truth 會從此資料集中選取具有低可信度分數的資料點,並將其傳送給人力工作者。
-
Ground Truth 會使用現有的人工標籤資料,以及這組人力工作者提供的額外標籤資料,為模型進行更新。
-
此過程會重複,直到完全標籤資料集,或者直到滿足另一個停止條件。例如,如果達到人工註釋預算上限,自動標籤就會停止。
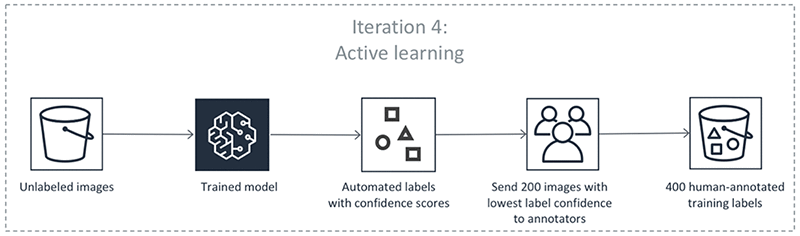
前面的步驟會反覆迭代進行。選取下表中的每個分頁,檢視物件偵測自動化標籤工作在每個迭代中發生的程序範例。這些影像中特定步驟中使用的資料物件數量(例如 200)是此範例所特有的。如果要標籤的物件少於 5,000 個,則驗證集大小為整個資料集的 20%。如果輸入資料集的物件多於 5,000 個,則驗證集大小為整個資料集的 10%。您可以透過變更使用 API 作業CreateLabelingJob時的MaxConcurrentTaskCount值,控制每次使用中學習迭代收集的人工標籤數量。當您使用主控台建立標籤工作時,此值設定為 1,000。在主動學習分頁下所示的主動學習流程中,此值設定為 200。


自動化標籤的準確性
準確度的定義取決於您搭配自動化標籤使用的內建任務類型。對於所有任務類型,這些準確性要求均由 Ground Truth 預先確定,無法手動設定。
-
對於影像分類和文字分類,Ground Truth 使用邏輯來查找標籤預測信賴水準,其對應至少 95% 標籤準確度。這表示 Ground Truth 預計相較於人工標籤提供的範例,自動化標籤的準確性至少為 95%。
-
如為邊界框,自動標籤影像的預期平均交併比 (IoU)
為 0.6。為了找到平均 IoU,Ground Truth 計算每個類別影像上所有預測和遺漏框的平均 IOU,然後跨類別地平均這些值。 -
如為語意分割,自動標籤影像的預期平均 IOU 為 0.7。為了找到平均 IoU,Ground Truth 採用影像中所有類別 IoU 值的平均值 (不包括背景)。
在主動學習的每一次迭代 (上面清單中的步驟 3-6),可以使用人工註釋的驗證集找到可信度閾值,以便自動標籤物件的預期準確性,滿足某些預先定義的準確性要求。
建立自動化資料標籤任務 (主控台)
若要在 SageMaker AI 主控台中建立使用自動標籤的標籤工作,請使用下列程序。
建立自動資料標籤工作 (主控台)
-
開啟 SageMaker AI 主控台的 Ground Truth 標籤工作區段:https://console.aws.amazon.com/sagemaker/groundtruth
。 -
使用 建立標籤工作 (主控台) 作為指南,完成工作概觀和任務類型區段。請注意,自訂任務類型不支援自動標籤。
-
在工作者下,選擇您的人力資源類型。
-
在同一區段中,選擇啟用自動資料標籤。
-
使用設定週框方塊工具作為指南,在
任務類型標籤工具區段中建立工作者指示。例如,如果您選擇 語意分割作為標籤工作類型,則此區段將稱為語意分割標籤工具。 -
若要預覽工作者指示和儀表板,請選擇預覽。
-
選擇建立。這將建立並啟動您的標籤工作和自動標籤程序。
您可以在 SageMaker AI 主控台的標籤工作區段中看到您的標籤工作。您的輸出資料將出現在建立標籤工作時指定的 Amazon S3 儲存貯體中。如需標籤工作輸出資料之格式和檔案結構的詳細資訊,請參閱標記任務輸出資料。
建立自動化資料標籤工作 (API)
若要使用 SageMaker API 建立自動資料標籤工作,請使用 CreateLabelingJob 操作的 LabelingJobAlgorithmsConfig 參數。若要了解如何運用CreateLabelingJob作業啟動標籤工作,請參閱建立標籤工作 (API)。
在 LabelingJobAlgorithmSpecificationArn 參數中,指定用於自動資料標籤之演算法的 Amazon Resource Name (ARN)。從自動標籤支援的四種 Ground Truth 內建演算法中選擇一種:
自動化資料標籤工作完成時,Ground Truth 會傳回它用於自動化資料標籤工作的模型 ARN。藉由在 InitialActiveLearningModelArn 參數中提供字串格式的 ARN,使用此模型作為類似自動標籤工作類型的起始模型。若要擷取模型的 ARN,請使用類似以下的 a AWS Command Line Interface (AWS CLI) 命令。
# Fetch the mARN of the model trained in the final iteration of the previous labeling job.Ground Truth pretrained_model_arn = sagemaker_client.describe_labeling_job(LabelingJobName=job_name)['LabelingJobOutput']['FinalActiveLearningModelArn']
若要加密連接至 ML 運算執行個體的儲存磁碟區 (用於自動標記) 上的資料,請在 VolumeKmsKeyId 參數中包含 AWS Key Management Service (AWS KMS) 金鑰。如需有關 AWS KMS 金鑰的資訊,請參閱 AWS Key Management Service 開發人員指南中的什麼是 Key Management Service?。 AWS
如需使用 CreateLabelingJob操作建立自動化資料標籤任務的範例,請參閱 SageMaker AI 筆記本執行個體的 SageMaker AI 範例 Ground Truth 標籤任務區段中的 object_detection_tutorial 範例。 SageMaker 若要了解如何建立和開啟筆記本執行個體,請參閱建立 Amazon SageMaker 筆記本執行個體。若要了解如何存取 SageMaker AI 範例筆記本,請參閱 存取範例筆記本。
自動化資料標籤所需的 Amazon EC2 執行個體
下表列出為訓練和批次推論任務執行自動資料標籤所需的 Amazon Elastic Compute Cloud (Amazon EC2) 執行個體。
| 自動資料標籤工作類型 | 訓練執行個體類型 | 推論執行個體類型 |
|---|---|---|
|
Image classification |
ml.p3.2xlarge* |
ml.c5.xlarge |
|
物件偵測 (邊界框) |
ml.p3.2xlarge* |
ml.c5.4xlarge |
|
文字分類 |
ml.c5.2xlarge |
ml.m4.xlarge |
|
語意分割 |
ml.p3.2xlarge* |
ml.p3.2xlarge* |
* 在亞太區域 (孟買) (ap-south-1) 中,改用 ml.p2.8xlarge。
Ground Truth 管理您用於自動化資料標籤工作的執行個體。它會視需要建立、設定和終止執行個體來執行您的任務。這些執行個體不會出現在 Amazon EC2 執行個體儀表板中。
使用您自己的模型,設定主動學習工作流程
您可以使用自己的演算法建立主動學習工作流程,在該工作流程中執行訓練和推論,以自動標籤您的資料。筆記本 bring_your_own_model_for_sagemaker_labeling_workflows_with_active_learning.ipynb 使用 SageMaker AI 內建演算法 BlazingText 來示範這一點。此筆記本提供了一個 AWS CloudFormation 堆疊,您可以使用它來執行此工作流程 AWS Step Functions。您可以在此 GitHub 儲存庫
您也可以在 SageMaker AI 範例儲存庫中找到此筆記本。請參閱使用範例筆記本,了解如何尋找 Amazon SageMaker AI 範例筆記本。
