步驟 1:收集和彙總資料
下圖顯示預測問題的心理模型。目標是預測時間序列 z_t 的未來,並盡可能使用較多的相關資訊,使預測盡可能準確。因此,首要步驟是盡可能收集較多的正確資料。
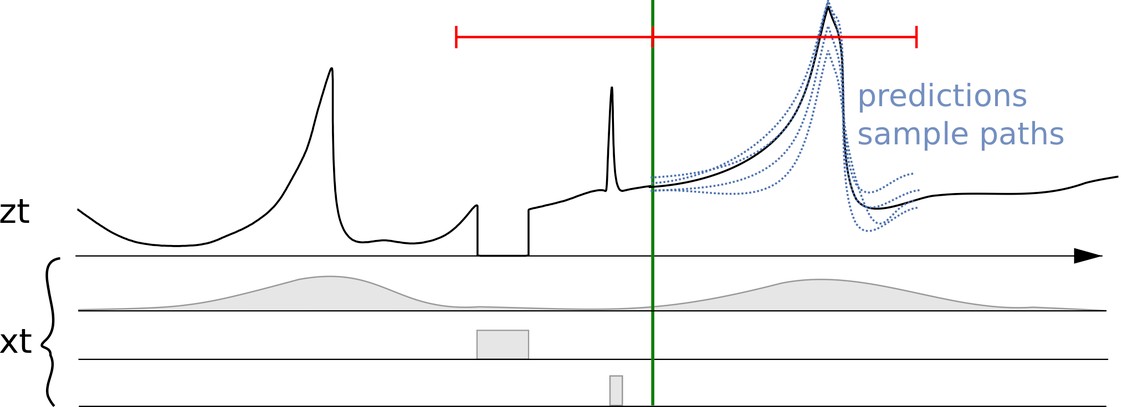
時間序列 z_t 以及相關聯的特徵或共變數 (x_t) 和多個預測
在上圖中,垂直線右側顯示了多個預測。這些預測是機率預測分佈的樣本 (或者,可反過來表示機率預測)。
零售企業應記錄的主要資訊是:
-
交易銷售資料 — 例如,存貨單位 (SKU)、地點、時間戳記和銷售數量。
-
SKU 品項詳細資料 — 品項的中繼資料。範例包括顏色、部門、大小等等。
-
價格資料 — 附有時間戳記的各個品項的價格時間序列。
-
促銷資訊資料 — 不同類型的促銷活動,可能是針對一系列的品項 (類別) 或附有時間戳記的個別品項。
-
庫存資訊資料 — 在每個時間單位,指出某個 SKU 是有庫存/可購買還是缺貨的資訊。
-
位置資料 — 品項或銷售在給定時間點的所在位置可以表示為字串
location_id或store_id,或是表示為實際地理位置。地理位置可以是國家/地區代碼加上五位數的郵遞區號或latitude_longitude座標。位置被視為交易銷售的一個「維度」。
在 Amazon Forecast
請注意,庫存資訊很重要,因為此問題的重點在於預測需求而不是銷售量,但企業僅記錄銷售量。某 SKU 缺貨時,銷售量會低於潛在需求,因此了解並記錄這類缺貨事件何時發生,是非常重要的。
其他需考量的資料集包括網頁造訪次數、搜尋詞彙的詳細資料、社交媒體和天氣資訊。資料在過去和未來都可供使用往往是很重要的,如此才能在模型中使用該資料。這是許多預測模型和回測的要求 (說明請見步驟 4:評估預測一節)。
就某些預測問題而言,原始資料的頻率自然會與預測問題的頻率相符。其範例包括伺服器磁碟區的要求,當您要以分鐘為頻率進行預測時,就會按分鐘對磁碟區取樣。
資料常會以更精細的頻率記錄,或就是在時間範圍內以任意時間戳記記錄,但預測問題的精細程度較粗糙。這是零售案例研究中的常見情況,銷售資料通常會記錄為交易資料;例如,格式中包含以高精細程度指出銷售發生時間的時間戳記。在預測使用案例中可能不需要這種低精細程度,將此資料彙總到每小時或每日銷售額可能會較為適當。此處的彙總層級對應於下游問題;例如,庫存管理或資源規劃。
範例
在下圖中,左圖顯示可在 Amazon Forecast 中輸入為逗號分隔值 (CSV) 檔案的原始客戶銷售資料的範例。在此範例中,銷售資料定義於較精細的每日時間格線上,而問題是要以較粗略的時間格線預測未來的每週需求。Amazon Forecast 會在 create_predictor API 呼叫中執行給定週內每日值的彙總。
結果會將原始資料轉換成格式良好、具有固定每週頻率的時間序列集合。右圖說明使用預設加總和彙總方法在目標時間序列上進行此彙總的情形。其他彙總方法包括平均值、最大值、最小值或選擇單一點 (例如,第一點)。彙總精細程度和方法必須適當選擇,使其最為符合資料的商業使用案例所需。在此範例中,彙總值會與每週彙總相符。使用者可以使用 create_predictor API FeaturizationConfig 參數的 FeaturizationMethodParameters 索引鍵來設定其他彙總方法。
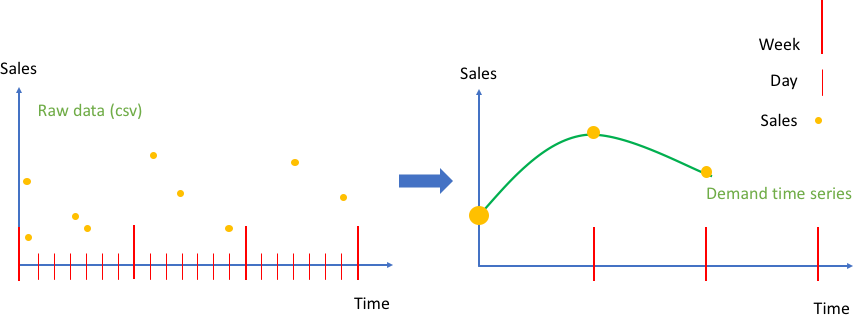
將原始銷售資料以事件的形式 (左) 彙總為等間距時間序列 (右)
