Restoring a backup into an Amazon RDS for MySQL DB instance
Amazon RDS supports importing MySQL databases with backup files. You can create a backup of your database, store the backup file on Amazon S3, and then restore the backup file to a new Amazon RDS DB instance running MySQL. Amazon RDS supports importing backup files from Amazon S3 in all AWS Regions.
The scenario described in this section restores a backup of an on-premises database. As long as the database is accessible, you can use this technique for databases in other locations, such as Amazon EC2 or other cloud services.
The following diagram shows the supported scenario.

If your on-premises database can be offline while you create, copy, and restore backup files, then we recommend that you use backup files to import your database to Amazon RDS. If your database can't be offline, then you can use one of the following methods:
-
Binary logs – First, import backup files from Amazon S3 and to Amazon RDS, as explained in this topic. Then use binary log (binlog) replication to update your database. For more information, see Configuring binary log file position replication with an external source instance.
-
AWS Database Migration Service – Use AWS Database Migration Service to migrate your database to Amazon RDS. For more information, see What is AWS Database Migration Service?
Overview of setup to import backup files from Amazon S3 to Amazon RDS
To import backup files from Amazon S3 to Amazon RDS, you need the following components:
An Amazon S3 bucket to store your backup files.
If you already have an Amazon S3 bucket, you can use that bucket. If you don't have an Amazon S3 bucket, create a new one. For more information, see Creating a bucket.
A backup of your on-premises database created by Percona XtraBackup.
For more information, see Creating your database backup.
-
An AWS Identity and Access Management (IAM) role to allow Amazon RDS to access the S3 bucket.
If you already have an IAM role, you can use that role and attach trust and permissions policies to it. For more information, see Creating an IAM role manually.
If you don't have an IAM role, you have two options:
-
You can manually create a new IAM role. For more information, see Creating an IAM role manually.
-
You can choose for Amazon RDS to create a new IAM role for you. If you want Amazon RDS to create a new IAM role for you, follow the procedure that uses the AWS Management Console in Importing data from Amazon S3 to a new MySQL DB instance section.
-
Creating your database backup
Use the Percona XtraBackup software to create your backup. We recommend that you use
the latest version of Percona XtraBackup. You can install Percona XtraBackup from Software Downloads
Warning
When creating a database backup, XtraBackup might save credentials in the
xtrabackup_info file. Make sure to confirm that the tool_command
setting in the xtrabackup_info file doesn't contain any sensitive
information.
The Percona XtraBackup version that you use depends on the MySQL version that you are backing up.
-
MySQL 8.4 – Use Percona XtraBackup version 8.4.
-
MySQL 8.0 – Use Percona XtraBackup version 8.0.
Note
Percona XtraBackup 8.0.12 and higher versions support migration of all versions of MySQL 8.0. If you are migrating to RDS for MySQL 8.0.32 or higher, you must use Percona XtraBackup 8.0.12 or higher.
-
MySQL 5.7 – Use Percona XtraBackup version 2.4.
You can use Percona XtraBackup to create a full backup of your MySQL database files. Alternatively, if you already use Percona XtraBackup to back up your MySQL database files, you can upload your existing full and incremental backup directories and files.
For more information about backing up your database with Percona XtraBackup, see
Percona XtraBackup - Documentation
Creating a full backup with Percona XtraBackup
To create a full backup of your MySQL database files that Amazon RDS can restore from
Amazon S3, use the Percona XtraBackup utility (xtrabackup).
For example, the following command creates a backup of a MySQL database
and stores the files in the folder /on-premises/s3-restore/backup folder.
xtrabackup --backup --user=myuser--password=password--target-dir=/on-premises/s3-restore/backup
If you want to compress your backup into a single file—which you can split into multiple files later, if needed—you can save your backup in one of the following formats based on your MySQL version:
Gzip (.gz) – For MySQL 5.7 and lower versions
tar (.tar) – For MySQL 5.7 and lower versions
Percona xbstream (.xbstream) – For all MySQL versions
Note
Percona XtraBackup 8.0 and higher only supports Percona xbstream for compression.
MySQL 5.7 and lower versions
The following command creates a backup of your MySQL database split into multiple Gzip files. Replace values with your own information.
xtrabackup --backup --user=my_user--password=password--stream=tar \ --target-dir=/on-premises/s3-restore/backup| gzip - | split -d --bytes=500MB \ -/on-premises/s3-restore/backup/backup.tar.gz
MySQL 5.7 and lower versions
The following command creates a backup of your MySQL database split into multiple tar files. Replace values with your own information.
xtrabackup --backup --user=my_user--password=password--stream=tar \ --target-dir=/on-premises/s3-restore/backup| split -d --bytes=500MB \ -/on-premises/s3-restore/backup/backup.tar
All MySQL versions
The following command creates a backup of your MySQL database split into multiple xbstream files. Replace values with your own information.
xtrabackup --backup --user=myuser--password=password--stream=xbstream \ --target-dir=/on-premises/s3-restore/backup| split -d --bytes=500MB \ -/on-premises/s3-restore/backup/backup.xbstream
Note
If you see the following error, it might be because you mixed file formats in your command:
ERROR:/bin/tar: This does not look like a tar archive
Using incremental backups with Percona XtraBackup
If you already use Percona XtraBackup to perform full and incremental backups of
your MySQL database files, you don't need to create a full backup and upload the
backup files to Amazon S3. Instead, to save time, copy your existing backup directories
and files to your Amazon S3 bucket. For more information about creating incremental
backups using Percona XtraBackup, see Create an incremental backup
When copying your existing full and incremental backup files to an Amazon S3 bucket,
you must recursively copy the contents of the base directory. Those contents include
both the full backup and all incremental backup directories and files. This copy
must preserve the directory structure in the Amazon S3 bucket. Amazon RDS iterates through all
files and directories. Amazon RDS uses the xtrabackup-checkpoints
file that is included with each incremental backup to identify the base directory
and to order incremental backups by log sequence number (LSN) range.
Backup considerations for Percona XtraBackup
Amazon RDS consumes your backup files based on the file name. Name your backup files
with the appropriate file extension based on the file format. For example, use
.xbstream for files stored using the Percona xbstream format.
Amazon RDS consumes your backup files in alphabetical order and also in natural number
order. To ensure that your backup files are written and named in the proper order,
use the split option when you issue the xtrabackup
command.
Amazon RDS doesn't support partial backups created using Percona XtraBackup. You can't use the following options to create a partial backup when you back up the source files for your database:
-
--tables -
--tables-exclude -
--tables-file -
--databases -
--databases-exclude -
--databases-file
Creating an IAM role manually
If you don't have an IAM role, you can create a new one manually. However, if you restore the database by using the AWS Management Console, we recommend that you choose to have Amazon RDS create this new IAM role for you. For Amazon RDS to create this role for you, follow the procedure in the Importing data from Amazon S3 to a new MySQL DB instance section.
To create a new IAM role manually for importing your database from Amazon S3, create a role to delegate permissions from Amazon RDS to your Amazon S3 bucket. When you create an IAM role, you attach trust and permissions policies. To import your backup files from Amazon S3, use trust and permissions policies similar to the following examples. For more information about creating the role, see Creating a role to delegate permissions to an AWS service.
The trust and permissions policies require that you provide an Amazon Resource Name (ARN). For more information about ARN formatting, see Amazon Resource Names (ARNs) and AWS service namespaces.
Example trust policy for importing from Amazon S3
Example permissions policy for importing from Amazon S3 — IAM user permissions
In the following example, replace iam_user_id with your own value.
Example permissions policy for importing from Amazon S3 — role permissions
In the following example, replace amzn-s3-demo-bucket
and prefix with your own values.
Note
If you include a file name prefix, include the asterisk (*) after the prefix. If you don't want to specify a prefix, specify only an asterisk.
Importing data from Amazon S3 to a new MySQL DB instance
You can import data from Amazon S3 to a new MySQL DB instance using the AWS Management Console, AWS CLI, or RDS API.
To import data from Amazon S3 to a new MySQL DB instance
-
Sign in to the AWS Management Console and open the Amazon RDS console at https://console.aws.amazon.com/rds/
. -
In the Amazon RDS console, choose the AWS Region where you want to create your DB instance. Choose the same AWS Region as the Amazon S3 bucket that contains your database backup.
-
In the navigation pane, choose Databases.
-
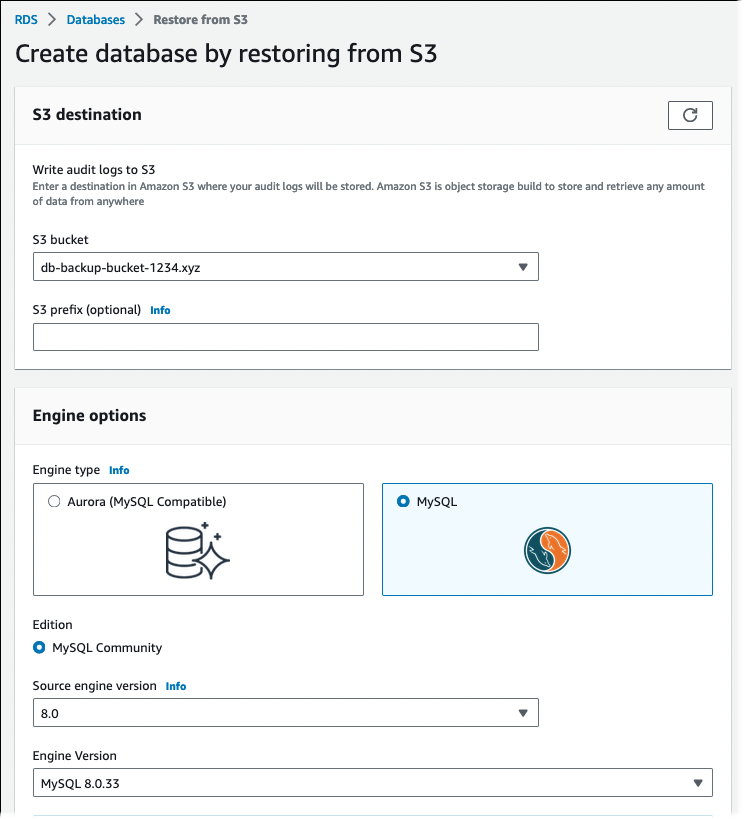
Choose Restore from S3.
The Create database by restoring from S3 page appears.
-
Under S3 source:
-
Choose the S3 bucket that contains the backup.
-
(Optional) For S3 prefix, enter the file path prefix for the files stored in your Amazon S3 bucket.
If you don't specify a prefix, then Amazon RDS creates your DB instance using all of the files and folders in the root folder of the S3 bucket. If you do specify a prefix, then Amazon RDS creates your DB instance using the files and folders in the S3 bucket where the path for the file begins with the specified prefix.
For example, you store your backup files on S3 in a subfolder named backups, and you have multiple sets of backup files, each in its own directory (gzip_backup1, gzip_backup2, and so on). In this case, to restore from the files in the gzip_backup1 folder, you specify the prefix backups/gzip_backup1.
-
-
Under Engine options:
-
For Engine type, choose MySQL.
-
For Source engine version, choose the MySQL major version of your source database.
-
For Engine Version, choose the default minor version of your MySQL major version in your AWS Region.
In the AWS Management Console, only the default minor version is available. After you complete the import, you can upgrade your DB instance.
-
-
For IAM role, create or choose IAM role with the required trust policy and permissions policy that allows Amazon RDS to access your Amazon S3 bucket. Perform one of the following actions:
(Recommended) Choose Create a new role, and enter the IAM role name. With this option, Amazon RDS automatically creates the role with the trust policy and permissions policy for you.
Choose an existing IAM role. Make sure that this role meets all of the criteria in Creating an IAM role manually.
Note
If role manager is enabled in your account, Amazon RDS attaches the role for you, and the role options described here are replaced by a Customize option. To use a different role, choose Customize. For more information, see IAM role creation in the IAM User Guide.
-
Specify your DB instance information. For information about each setting, see Settings for DB instances.
Note
Be sure to allocate enough storage for your new DB instance so that the restore operation can succeed.
To allow for future growth automatically, under Additional storage configuration, choose Enable storage autoscaling.
-
Choose additional settings as needed.
-
Choose Create database.
To import data from Amazon S3 to a new MySQL DB instance by using the AWS CLI, run the restore-db-instance-from-s3 command with the following options. For information about each setting, see Settings for DB instances.
Note
Be sure to allocate enough storage for your new DB instance so that the restore operation can succeed.
To enable storage autoscaling and allow for future growth automatically,
use the --max-allocated-storage option.
--allocated-storage--db-instance-identifier--db-instance-class--engine--master-username--manage-master-user-password--s3-bucket-name--s3-ingestion-role-arn--s3-prefix--source-engine--source-engine-version
Example
For Linux, macOS, or Unix:
aws rds restore-db-instance-from-s3 \ --allocated-storage250\ --db-instance-identifiermy_identifier\ --db-instance-classdb.m5.large\ --enginemysql\ --master-usernameadmin\ --manage-master-user-password \ --s3-bucket-nameamzn-s3-demo-bucket\ --s3-ingestion-role-arnarn:aws:iam::account-number:role/rolename\ --s3-prefixbucket_prefix\ --source-enginemysql\ --source-engine-version8.0.32\ --max-allocated-storage1000
For Windows:
aws rds restore-db-instance-from-s3 ^ --allocated-storage250^ --db-instance-identifiermy_identifier^ --db-instance-classdb.m5.large^ --enginemysql^ --master-usernameadmin^ --manage-master-user-password ^ --s3-bucket-nameamzn-s3-demo-bucket^ --s3-ingestion-role-arnarn:aws:iam::account-number:role/rolename^ --s3-prefixbucket_prefix^ --source-enginemysql^ --source-engine-version8.0.32^ --max-allocated-storage1000
To import data from Amazon S3 to a new MySQL DB instance by using the Amazon RDS API, call the RestoreDBInstanceFromS3 operation.
Limitations and considerations for importing backup files from Amazon S3 to Amazon RDS
The following limitations and considerations apply to importing backup files from Amazon S3 to an RDS for MySQL DB instance:
-
You can only migrate your data to a new DB instance, not to an existing DB instance.
-
You must use Percona XtraBackup to back up your data to Amazon S3. For more information, see Creating your database backup.
-
The Amazon S3 bucket and the RDS for MySQL DB instance must be in the same AWS Region.
-
You can't restore from the following sources:
-
A DB instance snapshot export to Amazon S3. You also can't migrate data from a DB instance snapshot export to your Amazon S3 bucket.
-
An encrypted source database. However, you can encrypt the data being migrated. You can also leave the data unencrypted during the migration process.
-
A MySQL 5.5 or 5.6 database.
-
-
RDS for MySQL doesn't support Percona Server for MySQL as a source database because it can contain
compression_dictionary*tables in themysql schema. -
RDS for MySQL doesn't support backward migration for either major versions or minor versions. For example, you can't migrate from MySQL version 8.0 to RDS for MySQL 5.7, and you can't migrate from MySQL version 8.0.32 to RDS for MySQL version 8.0.26.
-
Amazon RDS doesn't support importing on the db.t2.micro DB instance class from Amazon S3. However, you can restore to a different DB instance class, and then change the DB instance class later. For more information about instance classes, see Hardware specifications for DB instance classes.
-
Amazon S3 limits the size of a file uploaded to an Amazon S3 bucket to 5 TB. If a backup file exceeds 5 TB, then you must split the backup file into smaller files.
-
Amazon RDS limits the number of files uploaded to an Amazon S3 bucket to 1 million. If the backup data for your database, including all full and incremental backups, exceeds 1 million files, use a Gzip (.gz), tar (.tar.gz), or Percona xbstream (.xbstream) file to store full and incremental backup files in the Amazon S3 bucket. Percona XtraBackup 8.0 only supports Percona xbstream for compression.
-
To provide management services for each DB instance, Amazon RDS creates the
rdsadminuser when it creates the DB instance. Becauserdsaminis a reserved user in Amazon RDS, the following limitations apply:-
Amazon RDS doesn't import functions, procedures, views, events, and triggers with the
'rdsadmin'@'localhost'definer. For more information, see Stored objects with 'rdsamin'@'localhost' as the definer and Master user account privileges. -
When creating the DB instance, Amazon RDS creates a master user with the maximum supported privileges. When restoring from backup, Amazon RDS automatically removes any unsupported privileges assigned to users being imported.
To identify users that might be affected by this, see User accounts with unsupported privileges. For more information on supported privileges in RDS for MySQL, see Role-based privilege model for RDS for MySQL.
-
-
Amazon RDS doesn't migrate user-created tables in the
mysqlschema. -
You must configure the
innodb_data_file_pathparameter with only one data file that uses the default data file nameibdata1:12M:autoextend. You can migrate databases with two data files, or with a data file with a different name, using this method.The following examples are file names that Amazon RDS doesn't allow:
-
innodb_data_file_path=ibdata1:50M -
ibdata2:50M:autoextend -
innodb_data_file_path=ibdata01:50M:autoextend
-
-
You can't migrate from a source database that has tables defined outside of the default MySQL data directory.
-
The maximum supported size for uncompressed backups using this method is limited to 64 TiB. For compressed backups, this limit is lower to account for uncompression space requirements. In such cases, the maximum supported backup size is
64 TiB - compressed backup size.For information about the maximum supported database size that RDS for MySQL supports, see General Purpose SSD storage and Provisioned IOPS SSD storage.
-
Amazon RDS doesn't support the importing of MySQL and other external components and plugins.
-
Amazon RDS doesn't restore everything from your database. We recommend that you save the database schema and values for the following items from your source MySQL system database, and then add them to your restored RDS for MySQL DB instance after it has been created:
-
User accounts
-
Functions
-
Stored procedures
-
Time zone information. Time zone information is loaded from the local operating system of your RDS for MySQL DB instance. For more information, see Local time zone for MySQL DB instances.
-
Stored objects with 'rdsamin'@'localhost' as the definer
Amazon RDS doesn't import functions, procedures, views, events, and triggers with
'rdsadmin'@'localhost' as the definer.
You can use the following SQL script on your source MySQL database to list the stored objects that have the unsupported definer.
-- This SQL query lists routines with `rdsadmin`@`localhost` as the definer. SELECT ROUTINE_SCHEMA, ROUTINE_NAME FROM information_schema.routines WHERE definer = 'rdsadmin@localhost'; -- This SQL query lists triggers with `rdsadmin`@`localhost` as the definer. SELECT TRIGGER_SCHEMA, TRIGGER_NAME, DEFINER FROM information_schema.triggers WHERE DEFINER = 'rdsadmin@localhost'; -- This SQL query lists events with `rdsadmin`@`localhost` as the definer. SELECT EVENT_SCHEMA, EVENT_NAME FROM information_schema.events WHERE DEFINER = 'rdsadmin@localhost'; -- This SQL query lists views with `rdsadmin`@`localhost` as the definer. SELECT TABLE_SCHEMA, TABLE_NAME FROM information_schema.views WHERE DEFINER = 'rdsadmin@localhost';
User accounts with unsupported privileges
User accounts with privileges that RDS for MySQL doesn't supported are imported without the unsupported privileges. For the list of supported privileges, see Role-based privilege model for RDS for MySQL.
You can run the following SQL query on your source database to list the user accounts that have unsupported privileges.
SELECT user, host FROM mysql.user WHERE Shutdown_priv = 'y' OR File_priv = 'y' OR Super_priv = 'y' OR Create_tablespace_priv = 'y';
