Best practices for modeling relational data in DynamoDB
This section provides best practices for modeling relational data in Amazon DynamoDB. First, we introduce traditional data modeling concepts. Then, we describe the advantages of using DynamoDB over traditional relational database management systems—how it eliminates the need for JOIN operations and reduces overhead.
We then explain how to design a DynamoDB table that scales efficiently. Finally, we provide an example of how to model relational data in DynamoDB.
Topics
Traditional relational database models
A traditional relational database management system (RDBMS) stores data in a normalized relational structure. The objective of the relational data model is to reduce the duplication of data (through normalization) to support referential integrity and reduce data anomalies.
The following schema is an example of a relational data model for a generic order-entry application. The application supports a human resources schema that backs the operational and business support systems of a theoretical manufacturer.
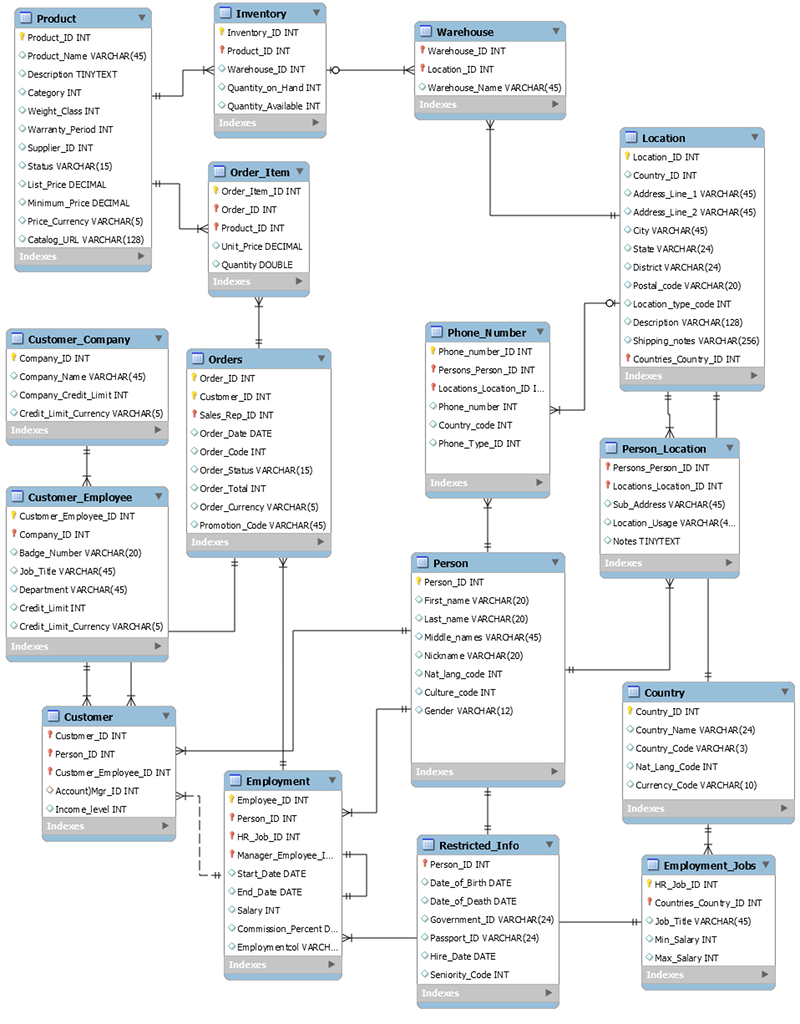
As a non-relational database service, DynamoDB offers many advantages over traditional relational database management systems.
How DynamoDB eliminates the need for JOIN operations
An RDBMS uses a structure query language (SQL) to return data to the application. Because
of the normalization of the data model, such queries typically require the use of the
JOIN operator to combine data from one or more tables.
For example, to generate a list of purchase order items sorted by the quantity in stock at all warehouses that can ship each item, you could issue the following SQL query against the preceding schema.
SELECT * FROM Orders
INNER JOIN Order_Items ON Orders.Order_ID = Order_Items.Order_ID
INNER JOIN Products ON Products.Product_ID = Order_Items.Product_ID
INNER JOIN Inventories ON Products.Product_ID = Inventories.Product_ID
ORDER BY Quantity_on_Hand DESCSQL queries of this kind can provide a flexible API for accessing data, but they require a significant amount of processing. Each join in the query increases the runtime complexity of the query because the data for each table must stage and then be assembled to return the result set.
Additional factors that can impact how long it takes the queries to run are the size of the tables and whether the columns being joined have indexes. The preceding query initiates complex queries across several tables and then sorts the result set.
Eliminating the need for JOINs is at the heart of NoSQL data modeling. This
is why we built DynamoDB to support Amazon.com, and why DynamoDB can deliver consistent performance
at any scale. Given the runtime complexity of SQL queries and JOINs, RDBMS
performance is not constant at scale. This causes performance issues as customer applications
grow.
While normalizing data does reduce the amount of data stored to disk, often the most constrained resources that impact performance are CPU time and network latency.
DynamoDB is built to minimize both constraints by eliminating JOINs (and
encouraging denormalization of data) and optimizing the database architecture to fully answer
an application query with a single request to an item. These qualities enable DynamoDB to provide
single-digit, millisecond performance at any scale. This is because the runtime complexity for
DynamoDB operations is constant, regardless of data size, for common access patterns.
How DynamoDB transactions eliminate overhead to the write process
Another factor that can slow down an RDBMS is the use of transactions to write to a normalized schema. As shown in the example, relational data structures used by most online transaction processing (OLTP) applications must be broken down and distributed across multiple logical tables when they are stored in an RDBMS.
Therefore, an ACID-compliant transaction framework is necessary to avoid race conditions and data integrity issues that could occur if an application tries to read an object that is in the process of being written. Such a transaction framework, when coupled with a relational schema, can add significant overhead to the write process.
The implementation of transactions in DynamoDB prohibits common scaling issues that are found with an RDBMS. DynamoDB does this by issuing a transaction as a single API call and bounding the number of items that can be accessed in that single transaction. Long-running transactions can cause operational issues by holding locks on the data either for a long time, or perpetually, because the transaction is never closed.
To prevent such issues in DynamoDB, transactions were implemented with two distinct API
operations: TransactWriteItems and TransactGetItems. These API
operations do not have begin and end semantics that are common in an RDBMS. Further, DynamoDB has
a 100-item access limit within a transaction to similarly prevent long-running transactions.
To learn more about DynamoDB transactions, see Working with
transactions.
For these reasons, when your business requires a low-latency response to high-traffic queries, taking advantage of a NoSQL system generally makes technical and economic sense. Amazon DynamoDB helps solve the problems that limit relational system scalability by avoiding them.
The performance of an RDBMS does not typically scale well for the following reasons:
-
It uses expensive joins to reassemble required views of query results.
-
It normalizes data and stores it on multiple tables that require multiple queries to write to disk.
-
It generally incurs the performance costs of an ACID-compliant transaction system.
DynamoDB scales well for these reasons:
-
Schema flexibility lets DynamoDB store complex hierarchical data within a single item.
-
Composite key design lets it store related items close together on the same table.
-
Transactions are performed in a single operation. The limit for the number of items that can be accessed is 100, to avoid long-running operations.
Queries against the data store become much simpler, often in the following form:
SELECT * FROM Table_X WHERE Attribute_Y = "somevalue"
DynamoDB does far less work to return the requested data compared to the RDBMS in the earlier example.
