Amazon Athena Apache Kafka connector
The Amazon Athena connector for Apache Kafka enables Amazon Athena to run SQL queries on your
Apache Kafka topics. Use this connector to view Apache Kafka
This connector does not use Glue Connections to centralize configuration properties in Glue. Connection configuration is done through Lambda.
Prerequisites
Deploy the connector to your AWS account using the Athena console or the AWS Serverless Application Repository. For more information, see Create a data source connection or Use the AWS Serverless Application Repository to deploy a data source connector.
Limitations
-
Write DDL operations are not supported.
-
Any relevant Lambda limits. For more information, see Lambda quotas in the AWS Lambda Developer Guide.
-
Date and timestamp data types in filter conditions must be cast to appropriate data types.
-
Date and timestamp data types are not supported for the CSV file type and are treated as varchar values.
-
Mapping into nested JSON fields is not supported. The connector maps top-level fields only.
-
The connector does not support complex types. Complex types are interpreted as strings.
-
To extract or work with complex JSON values, use the JSON-related functions available in Athena. For more information, see Extract JSON data from strings.
-
The connector does not support access to Kafka message metadata.
Terms
-
Metadata handler – A Lambda handler that retrieves metadata from your database instance.
-
Record handler – A Lambda handler that retrieves data records from your database instance.
-
Composite handler – A Lambda handler that retrieves both metadata and data records from your database instance.
-
Kafka endpoint – A text string that establishes a connection to a Kafka instance.
Cluster compatibility
The Kafka connector can be used with the following cluster types.
-
Standalone Kafka – A direct connection to Kafka (authenticated or unauthenticated).
-
Confluent – A direct connection to Confluent Kafka. For information about using Athena with Confluent Kafka data, see Visualize Confluent data in QuickSight using Amazon Athena
in the AWS Business Intelligence Blog.
Connecting to Confluent
Connecting to Confluent requires the following steps:
-
Generate an API key from Confluent.
-
Store the username and password for the Confluent API key into AWS Secrets Manager.
-
Provide the secret name for the
secrets_manager_secretenvironment variable in the Kafka connector. -
Follow the steps in the Setting up the Kafka connector section of this document.
Supported authentication methods
The connector supports the following authentication methods.
-
SASL/PLAIN
-
SASL/PLAINTEXT
-
NO_AUTH
-
Self-managed Kafka and Confluent Platform – SSL, SASL/SCRAM, SASL/PLAINTEXT, NO_AUTH
-
Self-managed Kafka and Confluent Cloud – SASL/PLAIN
For more information, see Configuring authentication for the Athena Kafka connector.
Supported input data formats
The connector supports the following input data formats.
-
JSON
-
CSV
-
AVRO
-
PROTOBUF (PROTOCOL BUFFERS)
Parameters
Use the parameters in this section to configure the Athena Kafka connector.
-
auth_type – Specifies the authentication type of the cluster. The connector supports the following types of authentication:
-
NO_AUTH – Connect directly to Kafka (for example, to a Kafka cluster deployed over an EC2 instance that does not use authentication).
-
SASL_SSL_PLAIN – This method uses the
SASL_SSLsecurity protocol and thePLAINSASL mechanism. For more information, see SASL configurationin the Apache Kafka documentation. -
SASL_PLAINTEXT_PLAIN – This method uses the
SASL_PLAINTEXTsecurity protocol and thePLAINSASL mechanism. For more information, see SASL configurationin the Apache Kafka documentation. -
SASL_SSL_SCRAM_SHA512 – You can use this authentication type to control access to your Apache Kafka clusters. This method stores the user name and password in AWS Secrets Manager. The secret must be associated with the Kafka cluster. For more information, see Authentication using SASL/SCRAM
in the Apache Kafka documentation. -
SASL_PLAINTEXT_SCRAM_SHA512 – This method uses the
SASL_PLAINTEXTsecurity protocol and theSCRAM_SHA512 SASLmechanism. This method uses your user name and password stored in AWS Secrets Manager. For more information, see the SASL configurationsection of the Apache Kafka documentation. -
SSL – SSL authentication uses key store and trust store files to connect with the Apache Kafka cluster. You must generate the trust store and key store files, upload them to an Amazon S3 bucket, and provide the reference to Amazon S3 when you deploy the connector. The key store, trust store, and SSL key are stored in AWS Secrets Manager. Your client must provide the AWS secret key when the connector is deployed. For more information, see Encryption and Authentication using SSL
in the Apache Kafka documentation. For more information, see Configuring authentication for the Athena Kafka connector.
-
-
certificates_s3_reference – The Amazon S3 location that contains the certificates (the key store and trust store files).
-
disable_spill_encryption – (Optional) When set to
True, disables spill encryption. Defaults toFalseso that data that is spilled to S3 is encrypted using AES-GCM – either using a randomly generated key or KMS to generate keys. Disabling spill encryption can improve performance, especially if your spill location uses server-side encryption. -
kafka_endpoint – The endpoint details to provide to Kafka.
-
schema_registry_url – The URL address for the schema registry (for example,
http://schema-registry.example.org:8081). Applies to theAVROandPROTOBUFdata formats. Athena only supports Confluent schema registry. -
secrets_manager_secret – The name of the AWS secret in which the credentials are saved.
-
Spill parameters – Lambda functions temporarily store ("spill") data that do not fit into memory to Amazon S3. All database instances accessed by the same Lambda function spill to the same location. Use the parameters in the following table to specify the spill location.
Parameter Description spill_bucketRequired. The name of the Amazon S3 bucket where the Lambda function can spill data. spill_prefixRequired. The prefix within the spill bucket where the Lambda function can spill data. spill_put_request_headers(Optional) A JSON encoded map of request headers and values for the Amazon S3 putObjectrequest that is used for spilling (for example,{"x-amz-server-side-encryption" : "AES256"}). For other possible headers, see PutObject in the Amazon Simple Storage Service API Reference. -
Subnet IDs – One or more subnet IDs that correspond to the subnet that the Lambda function can use to access your data source.
-
Public Kafka cluster or standard Confluent Cloud cluster – Associate the connector with a private subnet that has a NAT Gateway.
-
Confluent Cloud cluster with private connectivity – Associate the connector with a private subnet that has a route to the Confluent Cloud cluster.
-
For AWS Transit Gateway
, the subnets must be in a VPC that is attached to the same transit gateway that Confluent Cloud uses. -
For VPC Peering
, the subnets must be in a VPC that is peered to Confluent Cloud VPC. -
For AWS PrivateLink
, the subnets must be in a VPC that a has route to the VPC endpoints that connect to Confluent Cloud.
-
-
Note
If you deploy the connector into a VPC in order to access private resources and also want to connect to a publicly accessible service like Confluent, you must associate the connector with a private subnet that has a NAT Gateway. For more information, see NAT gateways in the Amazon VPC User Guide.
Data type support
The following table shows the corresponding data types supported for Kafka and Apache Arrow.
| Kafka | Arrow |
|---|---|
| CHAR | VARCHAR |
| VARCHAR | VARCHAR |
| TIMESTAMP | MILLISECOND |
| DATE | DAY |
| BOOLEAN | BOOL |
| SMALLINT | SMALLINT |
| INTEGER | INT |
| BIGINT | BIGINT |
| DECIMAL | FLOAT8 |
| DOUBLE | FLOAT8 |
Partitions and splits
Kafka topics are split into partitions. Each partition is ordered. Each message in a partition has an incremental ID called an offset. Each Kafka partition is further divided to multiple splits for parallel processing. Data is available for the retention period configured in Kafka clusters.
Best practices
As a best practice, use predicate pushdown when you query Athena, as in the following examples.
SELECT * FROM "kafka_catalog_name"."glue_schema_registry_name"."glue_schema_name" WHERE integercol = 2147483647
SELECT * FROM "kafka_catalog_name"."glue_schema_registry_name"."glue_schema_name" WHERE timestampcol >= TIMESTAMP '2018-03-25 07:30:58.878'
Setting up the Kafka connector
Before you can use the connector, you must set up your Apache Kafka cluster, use the AWS Glue Schema Registry to define your schema, and configure authentication for the connector.
When working with the AWS Glue Schema Registry, note the following points:
-
Make sure that the text in Description field of the AWS Glue Schema Registry includes the string
{AthenaFederationKafka}. This marker string is required for AWS Glue Registries that you use with the Amazon Athena Kafka connector. -
For best performance, use only lowercase for your database names and table names. Using mixed casing causes the connector to perform a case insensitive search that is more computationally intensive.
To set up your Apache Kafka environment and AWS Glue Schema Registry
-
Set up your Apache Kafka environment.
-
Upload the Kafka topic description file (that is, its schema) in JSON format to the AWS Glue Schema Registry. For more information, see Integrating with AWS Glue Schema Registry in the AWS Glue Developer Guide.
-
To use the
AVROorPROTOBUFdata format when you define the schema in the AWS Glue Schema Registry:-
For Schema name, enter the Kafka topic name in the same casing as the original.
-
For Data format, choose Apache Avro or Protocol Buffers.
For example schemas, see the following section.
-
Use the format of the examples in this section when you upload your schema to the AWS Glue Schema Registry.
JSON type schema example
In the following example, the schema to be created in the AWS Glue Schema
Registry specifies json as the value for
dataFormat and uses datatypejson for
topicName.
Note
The value for topicName should use the same casing as the
topic name in Kafka.
{ "topicName": "datatypejson", "message": { "dataFormat": "json", "fields": [ { "name": "intcol", "mapping": "intcol", "type": "INTEGER" }, { "name": "varcharcol", "mapping": "varcharcol", "type": "VARCHAR" }, { "name": "booleancol", "mapping": "booleancol", "type": "BOOLEAN" }, { "name": "bigintcol", "mapping": "bigintcol", "type": "BIGINT" }, { "name": "doublecol", "mapping": "doublecol", "type": "DOUBLE" }, { "name": "smallintcol", "mapping": "smallintcol", "type": "SMALLINT" }, { "name": "tinyintcol", "mapping": "tinyintcol", "type": "TINYINT" }, { "name": "datecol", "mapping": "datecol", "type": "DATE", "formatHint": "yyyy-MM-dd" }, { "name": "timestampcol", "mapping": "timestampcol", "type": "TIMESTAMP", "formatHint": "yyyy-MM-dd HH:mm:ss.SSS" } ] } }
CSV type schema example
In the following example, the schema to be created in the AWS Glue Schema
Registry specifies csv as the value for dataFormat
and uses datatypecsvbulk for topicName. The value
for topicName should use the same casing as the topic name in
Kafka.
{ "topicName": "datatypecsvbulk", "message": { "dataFormat": "csv", "fields": [ { "name": "intcol", "type": "INTEGER", "mapping": "0" }, { "name": "varcharcol", "type": "VARCHAR", "mapping": "1" }, { "name": "booleancol", "type": "BOOLEAN", "mapping": "2" }, { "name": "bigintcol", "type": "BIGINT", "mapping": "3" }, { "name": "doublecol", "type": "DOUBLE", "mapping": "4" }, { "name": "smallintcol", "type": "SMALLINT", "mapping": "5" }, { "name": "tinyintcol", "type": "TINYINT", "mapping": "6" }, { "name": "floatcol", "type": "DOUBLE", "mapping": "7" } ] } }
AVRO type schema example
The following example is used to create an AVRO-based schema in the AWS Glue
Schema Registry. When you define the schema in the AWS Glue Schema Registry,
for Schema name, you enter the Kafka topic name in the
same casing as the original, and for Data format, you
choose Apache Avro. Because you specify this
information directly in the registry, the dataformatand
topicName fields are not required.
{ "type": "record", "name": "avrotest", "namespace": "example.com", "fields": [{ "name": "id", "type": "int" }, { "name": "name", "type": "string" } ] }
PROTOBUF type schema example
The following example is used to create an PROTOBUF-based schema in the
AWS Glue Schema Registry. When you define the schema in the AWS Glue Schema
Registry, for Schema name, you enter the Kafka topic
name in the same casing as the original, and for Data
format, you choose Protocol Buffers.
Because you specify this information directly in the registry, the
dataformatand topicName fields are not
required. The first line defines the schema as PROTOBUF.
syntax = "proto3"; message protobuftest { string name = 1; int64 calories = 2; string colour = 3; }
For more information about adding a registry and schemas in the AWS Glue Schema Registry, see Getting started with Schema Registry in the AWS Glue documentation.
Configuring authentication for the Athena Kafka connector
You can use a variety of methods to authenticate to your Apache Kafka cluster, including SSL, SASL/SCRAM, SASL/PLAIN, and SASL/PLAINTEXT.
The following table shows the authentication types for the connector and the
security protocol and SASL mechanism for each. For more information, see the Security
| auth_type | security.protocol | sasl.mechanism | Cluster type compatibility |
|---|---|---|---|
SASL_SSL_PLAIN |
SASL_SSL |
PLAIN |
|
SASL_PLAINTEXT_PLAIN |
SASL_PLAINTEXT |
PLAIN |
|
SASL_SSL_SCRAM_SHA512 |
SASL_SSL |
SCRAM-SHA-512 |
|
SASL_PLAINTEXT_SCRAM_SHA512 |
SASL_PLAINTEXT |
SCRAM-SHA-512 |
|
SSL |
SSL |
N/A |
|
SSL
If the cluster is SSL authenticated, you must generate the trust store and key store files and upload them to the Amazon S3 bucket. You must provide this Amazon S3 reference when you deploy the connector. The key store, trust store, and SSL key are stored in the AWS Secrets Manager. You provide the AWS secret key when you deploy the connector.
For information on creating a secret in Secrets Manager, see Create an AWS Secrets Manager secret.
To use this authentication type, set the environment variables as shown in the following table.
| Parameter | Value |
|---|---|
auth_type |
SSL |
certificates_s3_reference |
The Amazon S3 location that contains the certificates. |
secrets_manager_secret |
The name of your AWS secret key. |
After you create a secret in Secrets Manager, you can view it in the Secrets Manager console.
To view your secret in Secrets Manager
Open the Secrets Manager console at https://console.aws.amazon.com/secretsmanager/
. -
In the navigation pane, choose Secrets.
-
On the Secrets page, choose the link to your secret.
-
On the details page for your secret, choose Retrieve secret value.
The following image shows an example secret with three key/value pairs:
keystore_password,truststore_password, andssl_key_password.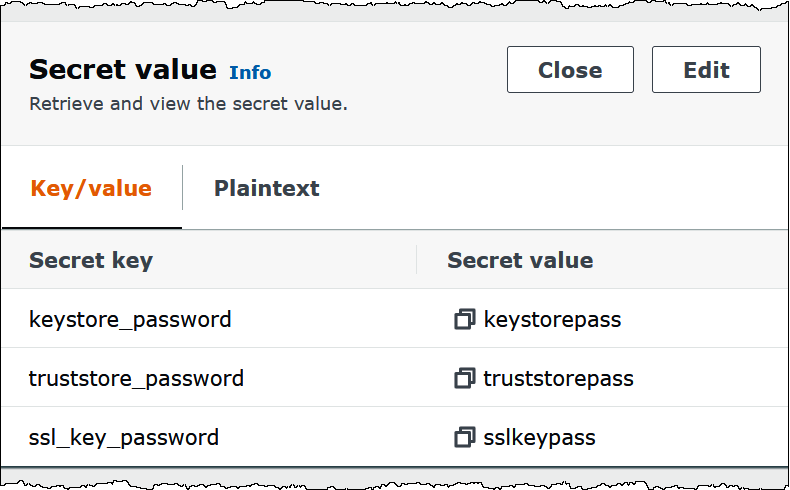
For more information about using SSL with Kafka, see Encryption and
Authentication using SSL
SASL/SCRAM
If your cluster uses SCRAM authentication, provide the Secrets Manager key that is associated with the cluster when you deploy the connector. The user's AWS credentials (secret key and access key) are used to authenticate with the cluster.
Set the environment variables as shown in the following table.
| Parameter | Value |
|---|---|
auth_type |
SASL_SSL_SCRAM_SHA512 |
secrets_manager_secret |
The name of your AWS secret key. |
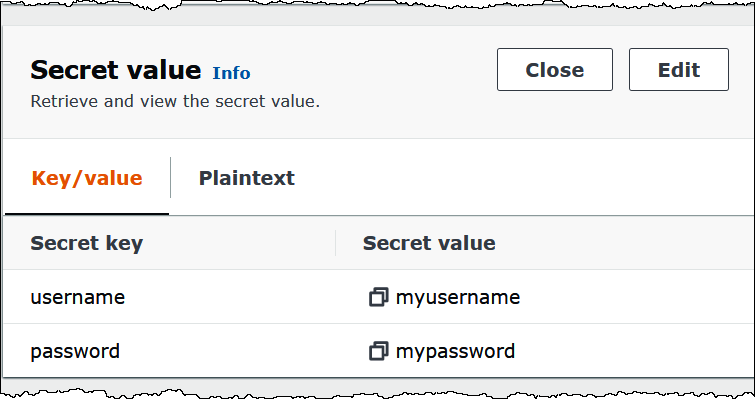
The following image shows an example secret in the Secrets Manager console with two
key/value pairs: one for username, and one for
password.
For more information about using SASL/SCRAM with Kafka, see Authentication using SASL/SCRAM
License information
By using this connector, you acknowledge the inclusion of third party components, a list
of which can be found in the pom.xml
Additional resources
For additional information about this connector, visit the corresponding site
