Scaling policy based on Amazon SQS
Important
The following information and steps shows you how to calculate the Amazon SQS queue
backlog per instance using the ApproximateNumberOfMessages queue
attribute before publishing it as a custom metric to CloudWatch. However, you can now
save the cost and effort put into publishing your own metric by using metric
math. For more information, see Create a target
tracking scaling policy using metric math.
You can scale your Auto Scaling group in response to changes in system load in an Amazon Simple Queue Service (Amazon SQS) queue. To learn more about how you can use Amazon SQS, see the Amazon Simple Queue Service Developer Guide.
There are some scenarios where you might think about scaling in response to activity in an Amazon SQS queue. For example, suppose that you have a web app that lets users upload images and use them online. In this scenario, each image requires resizing and encoding before it can be published. The app runs on EC2 instances in an Auto Scaling group, and it's configured to handle your typical upload rates. Unhealthy instances are terminated and replaced to maintain current instance levels at all times. The app places the raw bitmap data of the images in an SQS queue for processing. It processes the images and then publishes the processed images where they can be viewed by users. The architecture for this scenario works well if the number of image uploads doesn't vary over time. But if the number of uploads changes over time, you might consider using dynamic scaling to scale the capacity of your Auto Scaling group.
Contents
Use target tracking with the right metric
If you use a target tracking scaling policy based on a custom Amazon SQS queue metric, dynamic scaling can adjust to the demand curve of your application more effectively. For more information about choosing metrics for target tracking, see Choose metrics.
The issue with using a CloudWatch Amazon SQS metric like
ApproximateNumberOfMessagesVisible for target tracking is that
the number of messages in the queue might not change proportionally to the size
of the Auto Scaling group that processes messages from the queue. That's because the
number of messages in your SQS queue does not solely define the number of
instances needed. The number of instances in your Auto Scaling group can be driven by
multiple factors, including how long it takes to process a message and the
acceptable amount of latency (queue delay).
The solution is to use a backlog per instance metric with the target value being the acceptable backlog per instance to maintain. You can calculate these numbers as follows:
-
Backlog per instance: To calculate your backlog per instance, start with the
ApproximateNumberOfMessagesqueue attribute to determine the length of the SQS queue (number of messages available for retrieval from the queue). Divide that number by the fleet's running capacity, which for an Auto Scaling group is the number of instances in theInServicestate, to get the backlog per instance. -
Acceptable backlog per instance: To calculate your target value, first determine what your application can accept in terms of latency. Then, take the acceptable latency value and divide it by the average time that an EC2 instance takes to process a message.
As an example, let's say that you currently have an Auto Scaling group with 10
instances and the number of visible messages in the queue
(ApproximateNumberOfMessages) is 1500. If the average
processing time is 0.1 seconds for each message and the longest acceptable
latency is 10 seconds, then the acceptable backlog per instance is 10 / 0.1,
which equals 100 messages. This means that 100 is the target value for your
target tracking policy. When the backlog per instance reaches the target value,
a scale-out event will happen. Because the backlog per instance is already 150
messages (1500 messages / 10 instances), your group scales out, and it scales
out by five instances to maintain proportion to the target value.
The following procedures demonstrate how to publish the custom metric and create the target tracking scaling policy that configures your Auto Scaling group to scale based on these calculations.
Important
Remember, to reduce costs, use metric math instead. For more information, see Create a target tracking scaling policy using metric math.
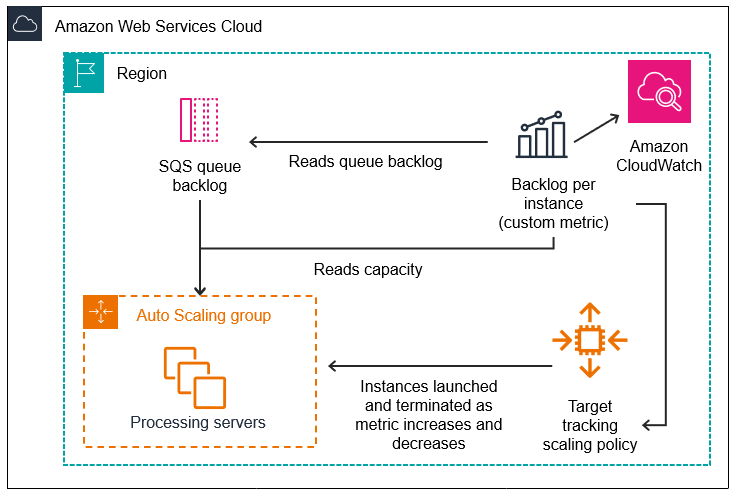
There are three main parts to this configuration:
-
An Auto Scaling group to manage EC2 instances for the purposes of processing messages from an SQS queue.
-
A custom metric to send to Amazon CloudWatch that measures the number of messages in the queue per EC2 instance in the Auto Scaling group.
-
A target tracking policy that configures your Auto Scaling group to scale based on the custom metric and a set target value. CloudWatch alarms invoke the scaling policy.
The following diagram illustrates the architecture of this configuration.
Limitations
You must use the AWS CLI or an SDK to publish your custom metric to CloudWatch. You can then monitor your metric with the AWS Management Console.
In the following sections you use the AWS CLI for the tasks you need to perform.
For example, to get metric data that reflects the present use of the queue, you
use the SQS get-queue-attributes
Amazon SQS and instance scale-in protection
Messages that have not been processed at the time an instance is terminated are returned to the SQS queue where they can be processed by another instance that is still running. For applications where long running tasks are performed, you can optionally use instance scale-in protection to have control over which queue workers are terminated when your Auto Scaling group scales in.
The following pseudocode shows one way to protect long-running, queue-driven worker processes from scale-in termination.
while (true) { SetInstanceProtection(False); Work = GetNextWorkUnit(); SetInstanceProtection(True); ProcessWorkUnit(Work); SetInstanceProtection(False); }
For more information, see Design your applications to gracefully handle instance termination.
