Targeted sentiment
Targeted sentiment provides a granular understanding of the sentiments associated with specific entities (such as brands or products) in your input documents.
The difference between targeted sentiment and sentiment is the level of granularity in the output data. Sentiment analysis determines the dominant sentiment for each input document, but doesn't provide data for further analysis. Targeted sentiment analysis determines the entity-level sentiment for specific entities in each input document. You can analyze the output data to determine the specific products and services that get positive or negative feedback.
For example, in a set of restaurant reviews, a customer provides the following review: "The tacos were delicious and the staff was friendly.” Analysis of this review produces the following results:
Sentiment analysis determines whether the overall sentiment of each restaurant review is positive, negative, neutral, or mixed. In this example, the overall sentiment is positive.
Targeted sentiment analysis determines sentiment for entities and attributes of the restaurant that customers mention in the reviews. In this example, the customer made positive comments about “tacos” and “staff”.
Targeted sentiment provides the following outputs for each analysis job:
Identity of the entities mentioned in the documents.
-
Classification of the entity type for each entity mention.
The sentiment and a sentiment score for each entity mention.
Groups of mentions (co-reference groups) that correspond to a single entity.
You can use the console or the API to run targeted sentiment analysis. The console and the API support real-time analysis and asynchronous analysis for targeted sentiment.
Amazon Comprehend supports targeted sentiment for documents in the English language.
For additional information about targeted sentiment, including a tutorial, see Extract
granular sentiment in text with Amazon Comprehend Targeted Sentiment
Topics
Entity types
Targeted sentiment identifies the following entity types. It assigns entity type OTHER if the entity doesn’t
belong in any other category. Each entity mention in the output file includes the entity type, such as
"Type": "PERSON".
| Entity Type | Definition |
|---|---|
| PERSON | Examples include individuals, groups of people, nicknames, fictional characters, and animal names. |
| LOCATION | Geographical locations such as countries, cities, states, addresses, geological formations, bodies of water, natural landmarks, and astronomical locations. |
| ORGANIZATION | Examples include governments, companies, sports teams, and religions. |
| FACILITY | Buildings, airports, highways, bridges, and other permanent man-made structures and real estate improvements. |
| BRAND | Organization, group, or producer of a specific commercial item or line of products. |
| COMMERCIAL_ITEM | Any non-generic purchasable or acquirable item, including vehicles, and large products that had only one item produced. |
| MOVIE | A movie or television show. Entity could be the full name, a nickname, or a subtitle. |
| MUSIC | A song, full or partial. Also, collections of individual music creations, such as an album or an anthology. |
| BOOK | A book, published professionally or self-published. |
| SOFTWARE | An officially released software product. |
| GAME | A game, such as video games, board games, common games, or sports. |
| PERSONAL_TITLE | Official titles and honorifics such as President, PhD, or Dr. |
| EVENT | Examples include festival, concert, election, war, conference, and promotional event. |
| DATE | Any reference to a date or time, whether specific or general, whether absolute or relative. |
| QUANTITY | All measurements along with their units (currency, percent, number, bytes, etc.). |
| ATTRIBUTE | An attribute, characteristic, or trait of an entity, such as the "quality" of a product, the "price" of a phone, or the "speed" of a CPU. |
| OTHER | Entities that don’t belong in any of the other categories. |
Co-reference group
Targeted sentiment identifies co-reference groups in each input document. A co-reference group is a group of mentions in a document that correspond to one real-world entity.
In the following example of a customer review, “spa” is the entity, which has entity type
FACILITY. The entity has two additional mentions as a pronoun ("it").

Output file organization
The targeted sentiment analysis job creates a JSON text output file. The file contains one JSON object for each of the input documents. Each JSON object contains the following fields:
-
Entities – An array of entities found in the document.
-
File – The file name of the input document.
-
Line – If the input file is one document per line, Entities contains the line number of the document in the file.
Note
If targeted sentiment doesn't identify any entities in the input text, it returns an empty array as the Entities result.
The following example shows Entities for an input file with three lines of input. The input format is ONE_DOC_PER_LINE, so each line of input is a document.
{ "Entities":[
{entityA},
{entityB},
{entityC}
],
"File": "TargetSentimentInputDocs.txt",
"Line": 0
}
{ "Entities": [
{entityD},
{entityE}
],
"File": "TargetSentimentInputDocs.txt",
"Line": 1
}
{ "Entities": [
{entityF},
{entityG}
],
"File": "TargetSentimentInputDocs.txt",
"Line": 2
}An entity in the Entities array includes a logical grouping (called a co-reference group) of the entity mentions detected in the document. Each entity has the following overall structure:
{"DescriptiveMentionIndex": [0],
"Mentions": [
{mentionD},
{mentionE}
]
} An entity contains these fields:
-
Mentions – An array of mentions of the entity in the document. The array represents a co-reference group. See Co-reference group for an example. The order of mentions in the Mentions array is the order of their location (offset) in the document. Each mention includes the sentiment score and group score for that mention. The group score indicates the confidence level that these mentions belong to the same entity.
-
DescriptiveMentionIndex – One or more index into the Mentions array that provides the best name for the entity group. For example, an entity could have three mentions with Text values "ABC Hotel," “ABC Hotel,” and “it.” The best name is “ABC Hotel,” which has a DescriptiveMentionIndex value of [0,1].
Each mention includes the following fields
-
BeginOffset – The offset into the document text where the mention begins.
-
EndOffset – The offset into the document text where the mention ends.
GroupScore – The confidence that all the entities mentioned in the group relate to the same entity.
Text – The text in the document that identifies the entity.
Type – The type of the entity. Amazon Comprehend supports a variety of entity types.
Score – Model confidence that the entity is relevant. Value range is zero to one, where one is highest confidence.
MentionSentiment – Contains the sentiment and sentiment score for the mention.
Sentiment – The sentiment of the mention. Values include: POSITIVE, NEUTRAL, NEGATIVE, and MIXED.
SentimentScore – Provides model confidence for each of the possible sentiments. Value range is zero to one, where one is highest confidence.
The Sentiment values have the following meaning:
-
Positive – The entity mention expresses a positive sentiment.
-
Negative – The entity mention expresses a negative sentiment.
-
Mixed – The entity mention expresses both positive and negative sentiments.
-
Neutral – The entity mention does not express either positive or negative sentiments.
In the following example, an entity has only one mention in the input document, so the DescriptiveMentionIndex is zero (the first mention in the Mentions array). The identified entity is a PERSON with the name "I." The sentiment score is neutral.
{"Entities":[ { "DescriptiveMentionIndex": [0], "Mentions": [ { "BeginOffset": 0, "EndOffset": 1, "Score": 0.999997, "GroupScore": 1, "Text": "I", "Type": "PERSON", "MentionSentiment": { "Sentiment": "NEUTRAL", "SentimentScore": { "Mixed": 0, "Negative": 0, "Neutral": 1, "Positive": 0 } } } ] } ], "File": "Input.txt", "Line": 0 }
Real time analysis using the console
You can use the Amazon Comprehend console to run Targeted sentiment in real-time. Use the sample text or paste your own text into the input text box, then choose Analyze.
In the Insights panel, the console displays three views of the targeted sentiment analysis:
-
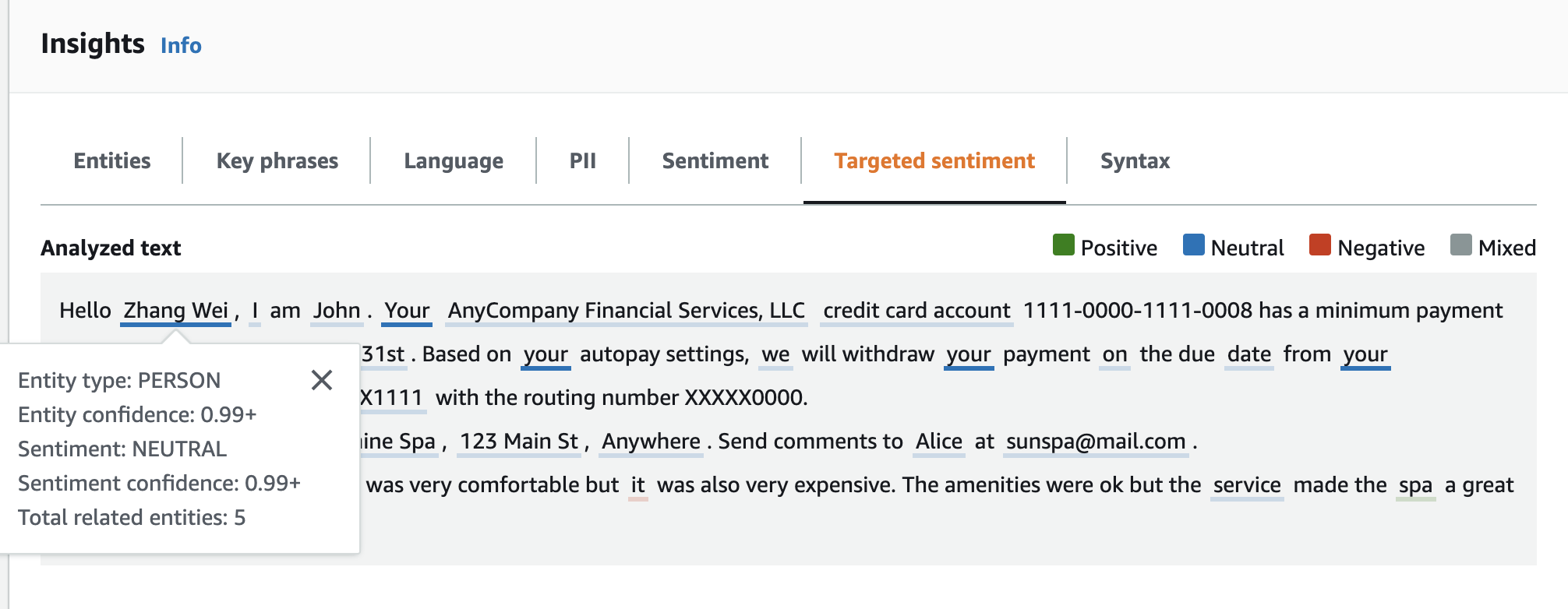
Analyzed text – Displays the analyzed text and underlines each entity. The color of the underline indicates the sentiment value (positive, neutral, negative, or mixed) that the analysis assigned to the entity. The console displays the color mappings at the top right corner of the analzed text box. If you hover your cursor over an entity, the console displays a popup panel containing analysis values (entity type, sentiment score) for the entity.
-
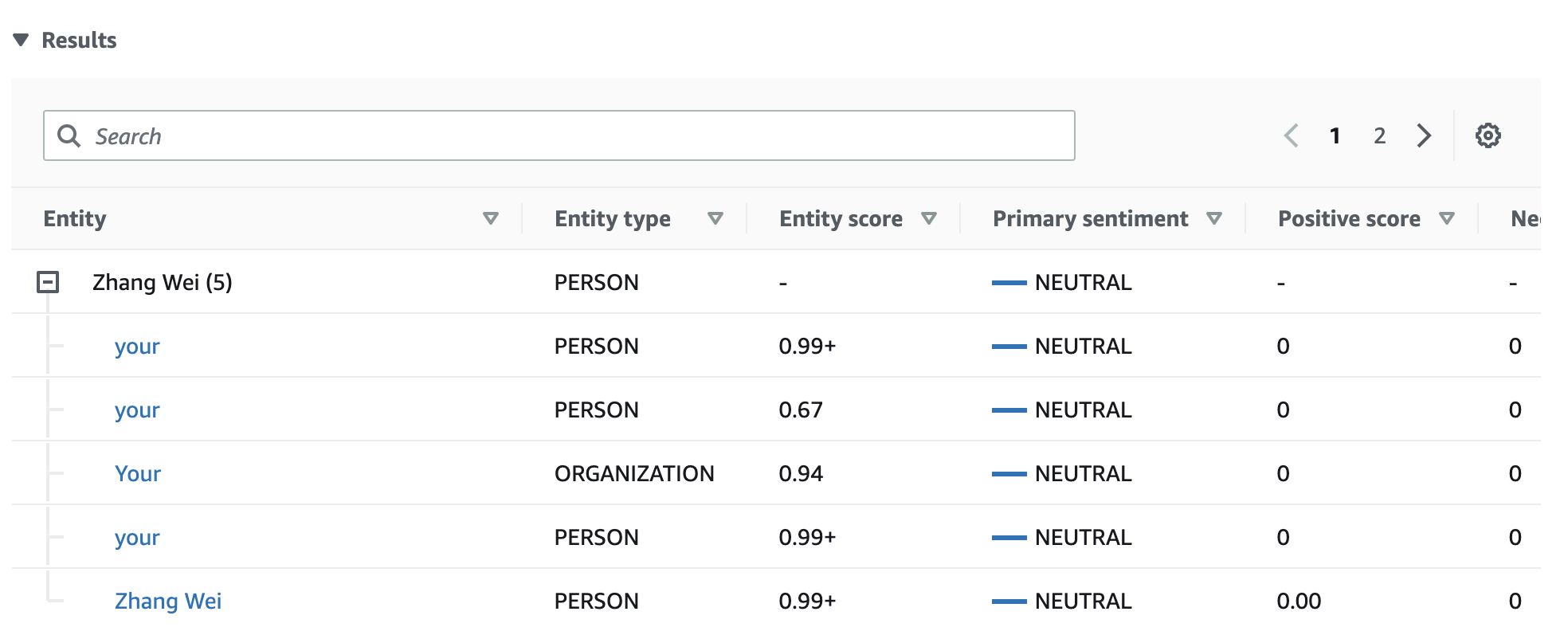
Results – Displays a table containing a row for each entity mention identified in the text. For each entity, the table shows the entity and entity score. The row also includes the primary sentiment and the score for each sentiment value. If there are multiple mentions of the same entity, known as a Co-reference group, the table displays these mentions as a collapsible set of rows associated with the main entity.
If you hover over an entity row in the Results table, the console highlights the entity mention in the Analyzed text panel.
-
Application integration – Displays the parameter values of the API request and the structure of the JSON object returned in the API response. For a description of the fields in the JSON object, see Output file organization.
Console real-time analysis example
This example uses the following text as input, which is the default input text that the console provides.
Hello Zhang Wei, I am John. Your AnyCompany Financial Services, LLC credit card account 1111-0000-1111-0008 has a minimum payment of $24.53 that is due by July 31st. Based on your autopay settings, we will withdraw your payment on the due date from your bank account number XXXXXX1111 with the routing number XXXXX0000. Customer feedback for Sunshine Spa, 123 Main St, Anywhere. Send comments to Alice at sunspa@mail.com. I enjoyed visiting the spa. It was very comfortable but it was also very expensive. The amenities were ok but the service made the spa a great experience.
The Analyzed text panel shows the following output for this example. Hover your mouse
over the text Zhang Wei to view the popup panel for this entity.
The Results table provides additional detail about each entity, including the entity score, the primary sentiment, and the score for each sentiment.

In our example, targeted sentiment analysis recognizes that each mention of your in the input text is a reference to the person entity Zhang Wei. The console displays these mentions as a set of collapsible rows associated with the main entity.
The Application integration panel displays the JSON object that the DetectTargetedSentiment API generates. See the following section for a full example.
Targeted sentiment output example
The following example shows the output file from a targeted sentiment analysis job. The input file consists of three simple documents:
The burger was very flavorful and the burger bun was excellent. However, customer service was slow. My burger was good, and it was warm. The burger had plenty of toppings. The burger was cooked perfectly but it was cold. The service was OK.
The targeted sentiment analysis of this input file produces the following output.
{"Entities":[
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 4,
"EndOffset": 10,
"Score": 0.999991,
"GroupScore": 1,
"Text": "burger",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "POSITIVE",
"SentimentScore": {
"Mixed": 0,
"Negative": 0,
"Neutral": 0,
"Positive": 1
}
}
}
]
},
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 38,
"EndOffset": 44,
"Score": 1,
"GroupScore": 1,
"Text": "burger",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "NEUTRAL",
"SentimentScore": {
"Mixed": 0.000005,
"Negative": 0.000005,
"Neutral": 0.999591,
"Positive": 0.000398
}
}
}
]
},
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 45,
"EndOffset": 48,
"Score": 0.961575,
"GroupScore": 1,
"Text": "bun",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "POSITIVE",
"SentimentScore": {
"Mixed": 0.000327,
"Negative": 0.000286,
"Neutral": 0.050269,
"Positive": 0.949118
}
}
}
]
},
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 73,
"EndOffset": 89,
"Score": 0.999988,
"GroupScore": 1,
"Text": "customer service",
"Type": "ATTRIBUTE",
"MentionSentiment": {
"Sentiment": "NEGATIVE",
"SentimentScore": {
"Mixed": 0.000001,
"Negative": 0.999976,
"Neutral": 0.000017,
"Positive": 0.000006
}
}
}
]
}
],
"File": "TargetSentimentInputDocs.txt",
"Line": 0
}
{
"Entities": [
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 0,
"EndOffset": 2,
"Score": 0.99995,
"GroupScore": 1,
"Text": "My",
"Type": "PERSON",
"MentionSentiment": {
"Sentiment": "NEUTRAL",
"SentimentScore": {
"Mixed": 0,
"Negative": 0,
"Neutral": 1,
"Positive": 0
}
}
}
]
},
{
"DescriptiveMentionIndex": [
0,
2
],
"Mentions": [
{
"BeginOffset": 3,
"EndOffset": 9,
"Score": 0.999999,
"GroupScore": 1,
"Text": "burger",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "POSITIVE",
"SentimentScore": {
"Mixed": 0.000002,
"Negative": 0.000001,
"Neutral": 0.000003,
"Positive": 0.999994
}
}
},
{
"BeginOffset": 24,
"EndOffset": 26,
"Score": 0.999756,
"GroupScore": 0.999314,
"Text": "it",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "POSITIVE",
"SentimentScore": {
"Mixed": 0,
"Negative": 0.000003,
"Neutral": 0.000006,
"Positive": 0.999991
}
}
},
{
"BeginOffset": 41,
"EndOffset": 47,
"Score": 1,
"GroupScore": 0.531342,
"Text": "burger",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "POSITIVE",
"SentimentScore": {
"Mixed": 0.000215,
"Negative": 0.000094,
"Neutral": 0.00008,
"Positive": 0.999611
}
}
}
]
},
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 52,
"EndOffset": 58,
"Score": 0.965462,
"GroupScore": 1,
"Text": "plenty",
"Type": "QUANTITY",
"MentionSentiment": {
"Sentiment": "NEUTRAL",
"SentimentScore": {
"Mixed": 0,
"Negative": 0,
"Neutral": 1,
"Positive": 0
}
}
}
]
},
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 62,
"EndOffset": 70,
"Score": 0.998353,
"GroupScore": 1,
"Text": "toppings",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "NEUTRAL",
"SentimentScore": {
"Mixed": 0,
"Negative": 0,
"Neutral": 0.999964,
"Positive": 0.000036
}
}
}
]
}
],
"File": "TargetSentimentInputDocs.txt",
"Line": 1
}
{
"Entities": [
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 4,
"EndOffset": 10,
"Score": 1,
"GroupScore": 1,
"Text": "burger",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "POSITIVE",
"SentimentScore": {
"Mixed": 0.001515,
"Negative": 0.000822,
"Neutral": 0.000243,
"Positive": 0.99742
}
}
},
{
"BeginOffset": 36,
"EndOffset": 38,
"Score": 0.999843,
"GroupScore": 0.999661,
"Text": "it",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "NEGATIVE",
"SentimentScore": {
"Mixed": 0,
"Negative": 0.999996,
"Neutral": 0.000004,
"Positive": 0
}
}
}
]
},
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 53,
"EndOffset": 60,
"Score": 1,
"GroupScore": 1,
"Text": "service",
"Type": "ATTRIBUTE",
"MentionSentiment": {
"Sentiment": "NEUTRAL",
"SentimentScore": {
"Mixed": 0.000033,
"Negative": 0.000089,
"Neutral": 0.993325,
"Positive": 0.006553
}
}
}
]
}
],
"File": "TargetSentimentInputDocs.txt",
"Line": 2
}
}