Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Multi-AZ DB-Cluster-Bereitstellungen für Amazon RDS
Eine Multi-AZ DB-Cluster-Bereitstellung ist ein halbsynchroner, hochverfügbarer Bereitstellungsmodus von Amazon RDS mit zwei lesbaren Replikat-DB-Instances. Ein Multi-AZ DB-Cluster hat eine Writer-DB-Instance und zwei Reader-DB-Instances in drei separaten Availability Zones in derselben. AWS-Region Multi-AZ DB-Cluster bieten im Vergleich zu Multi-AZ DB-Instance-Bereitstellungen eine hohe Verfügbarkeit, eine höhere Kapazität für Lese-Workloads und eine geringere Schreiblatenz.
Sie können Daten aus einer lokalen Datenbank in einen Multi-AZ DB-Cluster importieren, indem Sie die Anweisungen unter befolgen. Importieren von Daten in eine Datenbank von Amazon RDS für MySQL mit reduzierter Ausfallzeit
Sie können reservierte DB-Instances für einen Multi-AZ DB-Cluster erwerben. Weitere Informationen finden Sie unter Reservierte DB-Instances für einen Multi-AZ DB-Cluster.
Die Verfügbarkeit von Funktionen und der Support variieren zwischen bestimmten Versionen der einzelnen Datenbank-Engines und in allen AWS-Regionen. Weitere Informationen zur Version und regionalen Verfügbarkeit von Amazon RDS mit Multi-AZ DB-Clustern finden Sie unterUnterstützte Regionen und DB-Engines für Multi-AZ DB-Cluster in Amazon RDS.
Themen
Verbindung zu einem Multi-AZ DB-Cluster für Amazon RDS herstellen
Automatisches Verbinden einer AWS Rechenressource und eines Multi-AZ DB-Clusters für Amazon RDS
Aktualisierung der Engine-Version eines Multi-AZ DB-Clusters für Amazon RDS
Einen Multi-AZ DB-Cluster und Reader-DB-Instances für Amazon RDS neu starten
Einrichtung der logischen PostgreSQL-Replikation mit Multi-AZ DB-Clustern für Amazon RDS
Arbeiten mit Multi-AZ DB-Cluster-Read Replicas für Amazon RDS
Einrichtung der externen Replikation aus Multi-AZ DB-Clustern für Amazon RDS
Wichtig
Multi-AZ DB-Cluster sind nicht dasselbe wie Aurora-DB-Cluster. Informationen zu Aurora-DB-Clustern finden Sie im Amazon-Aurora-Benutzerhandbuch.
Verfügbarkeit der Instanzklasse für Multi-AZ DB-Cluster
Multi-AZ DB-Cluster-Bereitstellungen werden für die folgenden DB-Instance-Klassen unterstützt: db.m5ddb.m6gd,db.m6id,db.m6idn,db.r5d,db.r6gd,db.x2iedn,db.r6id, unddb.r6idn, unddb.c6gd.
Anmerkung
Die c6gd-Instance-Klassen sind die einzigen, die die Instance-Größe medium unterstützen.
Weitere Informationen zu DB-Instance-Klassen finden Sie unter .
Multi-AZ DB-Cluster-Architektur
Mit einem Multi-AZ DB-Cluster repliziert Amazon RDS Daten von der Writer-DB-Instance auf beide Leser-DB-Instances mithilfe der nativen Replikationsfunktionen der DB-Engine. Wenn eine Änderung an der Writer-DB-Instance vorgenommen wird, wird sie an jede Reader-DB-Instance gesendet.
Multi-AZ DB-Cluster-Bereitstellungen verwenden halbsynchrone Replikation, bei der die Bestätigung durch mindestens eine Reader-DB-Instance erforderlich ist, damit eine Änderung festgeschrieben werden kann. Es ist keine Bestätigung dafür erforderlich, dass die Ereignisse vollständig ausgeführt wurden und ein Commit für alle Replikate ausgeführt wurde.
Reader-DB-Instances fungieren als automatische Failover-Ziele und dienen auch dem Leseverkehr, um den Lesedurchsatz der Anwendung zu erhöhen. Wenn auf Ihrer Writer-DB-Instance ein Ausfall auftritt, verwaltet RDS das Failover auf eine der Reader-DB-Instances. RDS tut dies basierend darauf, welche Reader-DB-Instance über den neuesten Änderungsdatensatz verfügt.
Das folgende Diagramm zeigt einen DB-Cluster. Multi-AZ
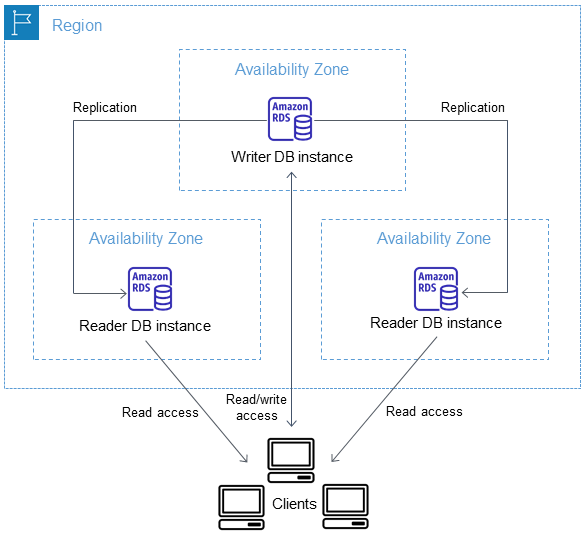
Multi-AZ DB-Cluster weisen im Vergleich zu Multi-AZ DB-Instance-Bereitstellungen in der Regel eine geringere Schreiblatenz auf. Auch schreibgeschützte Workloads dürfen auf Reader-DB-Instances ausgeführt werden. Die RDS-Konsole zeigt die Availability Zone der Schreib-DB-Instance und die Availability Zones der Reader DB-Instances an. Sie können diese Informationen auch mit dem CLI-Befehl describe-db-clusters oder der API-Operation DescribeDBClusters finden.
Wichtig
Um Replikationsfehler in RDS für Multi-AZ MySQL-DB-Cluster zu vermeiden, empfehlen wir dringend, dass alle Tabellen über einen Primärschlüssel verfügen.
Parametergruppen für Multi-AZ DB-Cluster
In einem Multi-AZ DB-Cluster fungiert eine DB-Cluster-Parametergruppe als Container für Engine-Konfigurationswerte, die auf jede DB-Instance im Multi-AZ DB-Cluster angewendet werden.
In einem Multi-AZ DB-Cluster ist eine DB-Parametergruppe auf die Standard-DB-Parametergruppe für die DB-Engine und die DB-Engine-Version festgelegt. Die Einstellungen in der Parametergruppe des DB-Clusters werden für alle DB-Instances im Cluster verwendet.
Informationen zu Parametergruppen finden Sie unter Arbeiten mit DB-Cluster-Parametergruppen für Multi-AZ DB-Cluster.
RDS-Proxy mit Multi-AZ DB-Clustern
Sie können Amazon RDS Proxy verwenden, um einen Proxy für Ihre Multi-AZ DB-Cluster zu erstellen. Durch die Verwendung des RDS-Proxys können die Anwendungen Datenbankverbindungen bündeln und gemeinsam nutzen, um ihre Skalierbarkeit zu verbessern. Jeder Proxy führt Multiplexing von Verbindungen aus, auch bekannt als Wiederverwendung von Verbindungen. Beim Multiplexing führt RDS-Proxy alle Operationen für eine Transaktion mit einer zugrunde liegenden Datenbankverbindung aus. RDS Proxy kann auch die Ausfallzeit für ein kleineres Versions-Upgrade eines Multi-AZ DB-Clusters auf eine Sekunde oder weniger reduzieren. Weitere Informationen zu den Vorteilen von RDS-Proxy finden Sie unter Amazon RDS-Proxy .
Um einen Proxy für einen Multi-AZ DB-Cluster einzurichten, wählen Sie bei der Erstellung des Clusters Create an RDS-Proxy. Anweisungen zum Erstellen und Verwalten von RDS-Proxy-Endpunkten finden Sie unter Arbeiten mit Amazon-RDS-Proxy-Endpunkten.
Replikatverzögerung und Multi-AZ DB-Cluster
Die Replikatverzögerung ist der Zeitunterschied zwischen der neuesten Transaktion auf der Writer-DB-Instance und der zuletzt angewendeten Transaktion auf einer Reader-DB-Instance. Die CloudWatch Amazon-Metrik ReplicaLag repräsentiert diesen Zeitunterschied. Weitere Informationen zu CloudWatch Metriken finden Sie unterÜberwachung von Amazon RDS mit Amazon CloudWatch.
Obwohl Multi-AZ DB-Cluster eine hohe Schreibleistung ermöglichen, kann es aufgrund der Natur der Engine-basierten Replikation dennoch zu Verzögerungen bei der Replikation kommen. Da jedes Failover zuerst die Replikatverzögerung auflösen muss, bevor es eine neue Writer-DB-Instance fördert, ist die Überwachung und Verwaltung dieser Replikatverzögerung eine Überlegung wert.
Bei RDS for Multi-AZ MySQL-DB-Clustern hängt die Failover-Zeit von der Replikatverzögerung der beiden verbleibenden Reader-DB-Instances ab. Beide Reader-DB-Instances müssen nicht angewendete Transaktionen anwenden, bevor eine von ihnen auf die neue Writer-DB-Instance befördert wird.
Bei RDS for Multi-AZ PostgreSQL-DB-Clustern hängt die Failover-Zeit von der niedrigsten Replikatverzögerung der beiden verbleibenden Reader-DB-Instances ab. Die Reader-DB-Instance mit der kleinsten Replikatverzögerung muss nicht angewendete Transaktionen anwenden, bevor sie auf die neue Writer-DB-Instance befördert wird.
Ein Tutorial, das Ihnen zeigt, wie Sie einen CloudWatch Alarm auslösen, wenn die Replikatverzögerung einen bestimmten Zeitraum überschreitet, finden Sie unter. Tutorial: Erstellen eines CloudWatch Amazon-Alarms für Multi-AZ DB-Cluster-Replikatverzögerungen für Amazon RDS
Häufige Ursachen für Replikatverzögerung
Im Allgemeinen tritt eine Replikatverzögerung auf, wenn die Write-Workload zu hoch ist, als dass die Reader-DB-Instances die Transaktionen effizient anwenden könnten. Verschiedene Workloads können eine vorübergehende oder kontinuierliche Replikatverzögerung verursachen. Einige gängige Beispiele:
-
Hohe Write-Parallelität oder starke Batch-Aktualisierung auf der Writer-DB-Instance, wodurch der Anwendungsprozess auf den Reader-DB-Instances zurückbleibt.
-
Starke Read-Workload, die Ressourcen auf einer oder mehreren Reader-DB-Instances verwendet. Das Ausführen langsamer oder großer Abfragen kann sich auf den Anwendungsprozess auswirken und die Replikatverzögerung verursachen.
-
Transaktionen, die große Datenmengen oder DDL-Anweisungen ändern, können manchmal zu einer vorübergehenden Zunahme der Replikatverzögerung führen, da die Datenbank die Commit-Reihenfolge beibehalten muss.
Minderung der Replikatverzögerung
Bei Multi-AZ DB-Clustern für RDS für MySQL und RDS für PostgreSQL können Sie die Replikatverzögerung verringern, indem Sie die Belastung Ihrer Writer-DB-Instance reduzieren. Sie können auch die Flusssteuerung verwenden, um Replikatverzögerung zu reduzieren. Die Flusssteuerung funktioniert, indem Schreibvorgänge auf der Writer-DB-Instance gedrosselt werden, wodurch sichergestellt wird, dass die Replikatverzögerung nicht unbegrenzt weiter zunimmt. Die Schreibdrosselung wird erreicht, indem am Ende einer Transaktion eine Verzögerung hinzugefügt wird, wodurch der Schreibdurchsatz auf der Writer-DB-Instance verringert wird. Obwohl die Flusskontrolle nicht garantiert, Verzögerungen zu verhindern, kann sie dazu beitragen, die allgemeine Verzögerung bei vielen Workloads zu reduzieren. Die folgenden Abschnitte enthalten Informationen zur Verwendung der Flusssteuerung mit RDS für MySQL und RDS für PostgreSQL.
Minderung der Replikatverzögerung durch Flusssteuerung für RDS für MySQL
Wenn Sie RDS für Multi-AZ MySQL-DB-Cluster verwenden, ist die Flusskontrolle standardmäßig mithilfe des dynamischen Parameters aktiviertrpl_semi_sync_master_target_apply_lag. Dieser Parameter gibt die Obergrenze an, die für die Replikatverzögerung gewünscht wird. Wenn sich die Replikatverzögerung diesem konfigurierten Limit nähert, drosselt die Flusssteuerung die Schreibtransaktionen auf der Writer-DB-Instance, um zu versuchen, die Replikatverzögerung unter dem angegebenen Wert einzudämmen. In einigen Fällen kann die Replikatverzögerung den angegebenen Grenzwert überschreiten. Standardmäßig ist dieser Parameter auf 120 Sekunden eingestellt. Um die Flusssteuerung zu deaktivieren, legen Sie diesen Parameter auf seinen Maximalwert von 86 400 Sekunden (ein Tag) fest.
Um die aktuelle Verzögerung anzuzeigen, die von der Flusssteuerung injiziert wird, zeigen Sie den Parameter Rpl_semi_sync_master_flow_control_current_delay an, indem Sie die folgende Abfrage ausführen.
SHOW GLOBAL STATUS like '%flow_control%';
Ihre Ausgabe sollte in etwa wie folgt aussehen.
+-------------------------------------------------+-------+
| Variable_name | Value |
+-------------------------------------------------+-------+
| Rpl_semi_sync_master_flow_control_current_delay | 2010 |
+-------------------------------------------------+-------+
1 row in set (0.00 sec)Anmerkung
Die Verzögerung wird in Mikrosekunden angezeigt.
Wenn Sie Performance Insights für einen RDS for Multi-AZ MySQL-DB-Cluster aktiviert haben, können Sie das Wartungsereignis überwachen, das einer SQL-Anweisung entspricht, die angibt, dass die Abfragen durch eine Flusssteuerung verzögert wurden. Wenn eine Verzögerung durch ein Flusssteuerungselement eingeführt wurde, können Sie das Wait-Rreignis /wait/synch/cond/semisync/semi_sync_flow_control_delay_cond anzeigen, das der SQL-Anweisung im Performance-Insights-Dashboard entspricht. Stellen Sie sicher, dass das Leistungsschema aktiviert ist, um diese Metriken anzuzeigen. Weitere Informationen zu Performance Insights finden Sie unter Überwachung mit Performance Insights auf Amazon RDS.
Minderung der Replikatverzögerung durch Flusssteuerung für RDS für PostgreSQL
Wenn Sie RDS für Multi-AZ PostgreSQL-DB-Cluster verwenden, wird die Flusskontrolle als Erweiterung bereitgestellt. Sie aktiviert einen Hintergrund-Worker für alle DB-Instances im DB-Cluster. Standardmäßig kommunizieren die Hintergrund-Worker auf den Reader-DB-Instances die aktuelle Replikatverzögerung mit dem Hintergrund-Worker auf der Writer-DB-Instance. Wenn die Verzögerung bei einer Reader-DB-Instance zwei Minuten überschreitet, fügt der Hintergrund-Worker der Writer-DB-Instance am Ende einer Transaktion eine Verzögerung hinzu. Um den Verzögerungsschwellenwert zu steuern, verwenden Sie den Parameter flow_control.target_standby_apply_lag.
Wenn eine Flusskontrolle einen PostgreSQL-Prozess drosselt, weist das Warteereignis Extension in pg_stat_activity und Performance Insights darauf hin. Die Funktion get_flow_control_stats zeigt Details darüber an, wie viel Verzögerung gerade hinzugefügt wird.
Die Flusskontrolle kann den meisten Workloads bei der Online-Transaktionsverarbeitung (OLTP) zugute kommen, die kurze, aber sehr gleichzeitige Transaktionen aufweisen. Wenn die Verzögerung durch lang andauernde Transaktionen wie Batchvorgänge verursacht wird, bietet die Flusskontrolle keinen so starken Vorteil.
Sie können die Flusskontrolle ausschalten, indem Sie die Erweiterung aus shared_preload_libraries entfernen und Ihre DB-Instance neu starten.
Multi-AZ DB-Cluster-Snapshots
Amazon RDS erstellt und speichert automatische Backups Ihres Multi-AZ DB-Clusters während des konfigurierten Backup-Fensters. RDS erstellt einen Snapshot für das Speichervolume des DB-Clusters, sodass der gesamte Cluster gesichert wird und nicht nur einzelne Instances.
Sie können auch manuelle Backups Ihres Multi-AZ DB-Clusters erstellen. Für sehr langfristige Backups empfehlen wir den Export von Snapshot-Daten in Amazon S3. Weitere Informationen finden Sie unter Erstellen eines Multi-AZ DB-Cluster-Snapshots für Amazon RDS.
Sie können einen Multi-AZ DB-Cluster bis zu einem bestimmten Zeitpunkt wiederherstellen und so einen neuen Multi-AZ DB-Cluster erstellen. Detaillierte Anweisungen finden Sie unter Wiederherstellung eines Multi-AZ DB-Clusters zu einem bestimmten Zeitpunkt.
Alternativ können Sie einen Multi-AZ DB-Cluster-Snapshot in einer Single-AZ Bereitstellung oder Multi-AZ DB-Instance-Bereitstellung wiederherstellen. Detaillierte Anweisungen finden Sie unter Wiederherstellung von einem Multi-AZ DB-Cluster-Snapshot auf eine DB-Instance.
