Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Bewährte Methoden für Amazon RDS
Informieren Sie sich über die bewährten Methoden für die Arbeit mit Amazon RDS. Dieser Abschnitt wird mit neuen bewährten Methoden aktualisiert, sobald diese bekannt sind.
Themen
Anmerkung
Allgemeine Empfehlungen für Amazon RDS finden Sie unter Empfehlungen von Amazon RDS.
Grundlegende Anleitungen für den Amazon-RDS-Betrieb
Im Folgenden finden Sie einige grundlegende Anleitungen für die Ausführung, die bei der Arbeit mit Amazon RDS befolgt werden sollten. Beachten Sie, dass das Amazon RDS Service Level Agreement voraussetzt, dass Sie die folgenden Anleitungen befolgen:
-
Verwenden Sie Metriken, um Speicher, CPU, Replikatverzögerung und Speichernutzung zu überwachen. Sie können Amazon so einrichten CloudWatch , dass Sie benachrichtigt werden, wenn sich die Nutzungsmuster ändern oder wenn Ihre Bereitstellung Kapazitätsgrenzen erreicht. Auf diese Weise können Sie leichter die Leistung und Verfügbarkeit des Systems wahren.
-
Skalieren Sie Ihre DB-Instance, wenn Sie die Grenzen der Speicherkapazität beinahe erreicht haben. Sie sollten etwas Puffer in Speicher und Arbeitsspeicher haben, um unvorhergesehene Nachfragesteigerungen seitens Ihrer Anwendungen bewältigen zu können.
-
Aktivieren Sie automatische Sicherungen und richten Sie das Sicherungsfenster so ein, dass Sicherungen während Zeiten mit nur wenigen Schreibvorgangs-IOPS ausgeführt werden. Dann ist eine Sicherung am wenigsten störend für Ihre Datenbanknutzung.
-
Wenn Ihre Datenbank-Arbeitslast mehr erfordert, I/O als Sie bereitgestellt haben, erfolgt die Wiederherstellung nach einem Failover oder Datenbankausfall nur langsam. Um die I/O Kapazität einer DB-Instance zu erhöhen, führen Sie einen oder alle der folgenden Schritte aus:
Migrieren Sie zu einer anderen DB-Instance-Klasse mit hoher I/O Kapazität.
Konvertieren Sie von einem magnetischen Speicher zu einem Speicher für allgemeine Zwecke oder zu einem Speicher mit bereitgestellten IOPS, abhängig davon, wie groß die benötigte Steigerung ist. Weitere Informationen zu den verfügbaren Speichertypen finden Sie unter Amazon-RDS-Speichertypen.
Wenn Sie zu einem Speicher mit bereitgestellten IOPS konvertieren, müssen Sie sicherstellen, dass Sie eine DB-Instance-Klasse verwenden, die für bereitgestellte IOPS optimiert ist. Weitere Informationen zu bereitgestellten IOPS finden Sie unter Bereitgestellter IOPS SSD-Speicher.
Wenn Sie bereits einen Speicher mit bereitgestellten IOPS verwenden, sollten Sie zusätzliche Durchsatzkapazitäten bereitstellen.
-
Wenn Ihre Client-Anwendung die DNS-Daten (Domain Name Service) Ihrer DB-Instances zwischenspeichert, legen Sie einen time-to-live (TTL) -Wert von weniger als 30 Sekunden fest. Die zugrunde liegende IP-Adresse einer DB-Instance kann sich nach einem Failover ändern. Ein längeres Zwischenspeichern der DNS-Daten kann somit zu Verbindungsfehlern führen. Ihre Anwendung versucht möglicherweise, eine Verbindung zu einer IP-Adresse herzustellen, die nicht mehr in Betrieb ist.
-
Testen Sie den Failover für Ihre DB-Instance, um zu verstehen, wie lange der Vorgang für Ihren besonderen Anwendungsfall dauert. Testen Sie außerdem die Failover-Funktion, um sicherzustellen, dass die Anwendung, mit der auf Ihre DB-Instance zugegriffen wird, nach einem Failover automatisch eine Verbindung mit der neuen DB-Instance herstellen kann.
RAM-Empfehlungen für DB-Instances
Eine bewährte Methode im Zusammenhang mit der Verbesserung der Leistung von Amazon RDS besteht in der Zuteilung von ausreichend RAM, damit sich Ihr Arbeitssatz beinahe vollständig im Arbeitsspeicher befindet. Der Arbeitssatz umfasst die Daten und Indizes, die häufig auf Ihrer Instance verwendet werden. Je häufiger Sie die DB-Instance verwenden, desto größer wird der Arbeitssatz.
Um festzustellen, ob sich Ihr Arbeitssatz fast vollständig im Arbeitsspeicher befindet, überprüfen Sie die ReadIOps-Metrik (mit Amazon CloudWatch), während die DB-Instance ausgelastet ist. Der Wert von ReadIOPS sollte klein und stabil sein. In einigen Fällen führt die Skalierung der DB-Instance-Klasse auf eine Klasse mit mehr RAM zu einer deutlichen Abnahme des ReadIOPS-Werts. In diesen Fällen war Ihr Arbeitssatz nicht fast vollständig im Speicher. Skalieren Sie weiter, bis der ReadIOPS-Wert nach einer Skalierungsoperation nicht mehr deutlich abnimmt oder zu einem sehr kleinen Wert reduziert wird. Informationen zur Überwachung der Metriken einer DB-Instance finden Sie unter Anzeigen von Metriken in der Amazon-RDS-Konsole.
Die Versionen der Datenbank-Engine auf dem neuesten Stand halten
Aktualisieren Sie Ihre Datenbank-Engine-Version regelmäßig, um Sicherheit, Leistung und Compliance zu gewährleisten. Amazon RDS veröffentlicht neue Neben- und Hauptversionen, die Sicherheits-Patches, Leistungsverbesserungen und neue Funktionen enthalten. Wenn Sie eine veraltete Datenbank-Engine ausführen, können Ihre Workloads bekannten Sicherheitslücken, Kompatibilitätsproblemen und eingeschränktem Support durch Datenbankanbieter ausgesetzt sein. AWS
Um Unterbrechungen zu minimieren, sollten Sie bei der Planung von Upgrades Folgendes berücksichtigen:
-
Testen in einer Staging-Umgebung – Überprüfen Sie die neue Version anhand Ihrer Workload, bevor Sie die Produktionsdatenbanken aktualisieren.
-
Verwenden der von Amazon RDS verwalteten Upgrades – Aktivieren Sie automatische Upgrades für kleinere Versionen, um das Patchen zu vereinfachen.
-
Planen von größere Versions-Upgrades – Lesen Sie die Versionshinweise, testen Sie die Anwendungskompatibilität und planen Sie ein kontrolliertes Upgrade-Fenster ein.
Regelmäßige Upgrades tragen dazu bei, dass Ihre Datenbank sicher und optimiert bleibt und den bewährten Methoden bei AWS entspricht.
AWS Datenbanktreiber
Wir empfehlen die AWS Treibersuite für die Anwendungskonnektivität. Die Treiber wurden so konzipiert, dass sie schnellere Switchover- und Failover-Zeiten sowie Authentifizierung mit AWS Secrets Manager, AWS Identity and Access Management (IAM) und Federated Identity unterstützen. Die AWS -Treiber müssen den Status der DB-Instance überwachen und die Instance-Topologie kennen, um den neuen Writer zu ermitteln. Dieser Ansatz reduziert die Umstellungs- und Failover-Zeiten auf Werte im einstelligen Sekundenbereich, im Vergleich zu Werten im zweistelligen Bereich bei Open-Source-Treibern.
Im Zuge der Einführung neuer Servicefunktionen besteht das Ziel der AWS Treibersuite darin, eine integrierte Unterstützung für diese Servicefunktionen zu bieten.
Weitere Informationen finden Sie unter Mit den AWS Treibern eine Verbindung zu DB-Instances herstellen.
Verwendung von „Enhanced Monitoring“ (Erweiterte Überwachung) zur Identifizierung von Betriebssystemproblemen
Wenn „Enhanced Monitoring“ (Erweiterte Überwachung) aktiviert ist, stellt Amazon RDS Metriken in Echtzeit für das Betriebssystem (OS) bereit, auf dem Ihre DB-Instance ausgeführt wird. Sie können die Metriken für Ihre DB-Instance über die Konsole anzeigen. Sie können die JSON-Ausgabe von Enhanced Monitoring von Amazon CloudWatch Logs auch in einem Überwachungssystem Ihrer Wahl verwenden. Weitere Informationen zu „Enhanced Monitoring“ (Erweiterte Überwachung) finden Sie unter Überwachen von Betriebssystem-Metriken mithilfe von „Enhanced Monitoring“·(Erweiterte·Überwachung).
Verwendung von Metriken zur Identifizierung von Problemen mit der Leistung
Sie können die Metriken überwachen, die für Ihre Amazon-RDS-DB-Instance verfügbar sind, um Leistungsprobleme aufgrund unzureichender Ressourcen und anderer häufiger Engpässe zu identifizieren.
Anzeigen von Leistungsmetriken
Sie sollten die Leistungsmetriken regelmäßig überwachen, um die Durchschnitts-, Höchst- und Mindestwerte für eine Vielzahl von Zeitbereichen anzuzeigen. Wenn Sie dies tun, können Sie feststellen, wenn die Leistung nachlässt. Sie können CloudWatch Amazon-Alarme auch für bestimmte Metrik-Schwellenwerte einrichten, sodass Sie benachrichtigt werden, wenn diese erreicht werden.
Um Probleme mit der Leistung zu beheben, müssen Sie die Basisleistung des Systems kennen. Wenn Sie eine DB-Instance einrichten und mit einer typischen Workload ausführen, erfassen Sie die Durchschnitts-, Maximal- und Minimalwerte aller Leistungsmetriken. Führen Sie diesen Vorgang in verschiedenen Intervallen aus (z. B. eine Stunde, 24 Stunden, eine Woche, zwei Wochen). Auf diese Weise erhalten Sie eine Vorstellung davon, was normal ist. Dies hilft, um Vergleichswerte für Betriebsstunden während und außerhalb von Spitzenbelastungen zu erhalten. Sie können diese Informationen anschließend verwenden, um festzustellen, wann die Leistung unter Standardwerte absinkt.
Wenn Sie Multi-AZ-DB-Cluster verwenden, überwachen Sie die Zeitdifferenz zwischen der letzten Transaktion auf der Writer-DB-Instance und der zuletzt angewendeten Transaktion auf einer Reader-DB-Instance. Dieser Unterschied heißt replica lag (Replikatverzögerung). Weitere Informationen finden Sie unter Replikatverzögerung und Multi-AZ-DB-Cluster.
Sie können die kombinierten Performance Insights und CloudWatch Metriken im Performance Insights Insights-Dashboard einsehen und Ihre DB-Instance überwachen. Performance Insights muss für Ihre DB-Instance aktiviert sein, damit diese Ansicht verwendet werden kann. Weitere Informationen zu dieser Überwachungsansicht finden Sie unter Anzeigen kombinierter Metriken mit dem Performance-Insights-Dashboard.
Sie können einen Leistungsanalysebericht für einen bestimmten Zeitraum erstellen und sich die ermittelten Erkenntnisse und Empfehlungen zur Lösung der Probleme ansehen. Weitere Informationen finden Sie unter Erstellen eines Leistungsanalyseberichts in Performance Insights.
So können Sie sich die Leistungsmessungen anzeigen
Melden Sie sich bei der an AWS-Managementkonsole und öffnen Sie die Amazon RDS-Konsole unter https://console.aws.amazon.com/rds/
. Wählen Sie im Navigationsbereich die Option Databases (Datenbanken) und anschließend eine DB-Instance.
Wählen Sie Monitoring.
Das Dashboard stellt die Leistungsmetriken bereit. Standardmäßig werden die Metriken der letzten drei Stunden angezeigt.
Verwenden Sie die nummerierten Schaltflächen oben rechts, um durch die zusätzlichen Metriken zu blättern, oder passen Sie die Einstellungen an, um weitere Metriken anzuzeigen.
Wählen Sie eine Leistungsmetrik zur Anpassung des Zeitbereichs, um Daten für andere Tage als den aktuellen Tag anzuzeigen. Sie können die Werte für Statistik, Zeitraum und Intervall ändern, um die angezeigten Informationen anzupassen. Angenommen, Sie möchten beispielsweise die Spitzenwerte für eine Metrik für jeden Tag der letzten zwei Wochen anzeigen. Legen Sie in diesem Fall Statistic (Statistik) auf Maximum, Time Range (Zeitbereich) auf Last 2 Weeks (Letzte 2 Wochen) und Period (Zeitraum) auf Day (Tag) fest.
Sie können die Leistungsmetriken auch über die CLI oder API anzeigen. Weitere Informationen finden Sie unter Anzeigen von Metriken in der Amazon-RDS-Konsole.
Um einen CloudWatch Alarm einzustellen
-
Melden Sie sich bei der an AWS-Managementkonsole und öffnen Sie die Amazon RDS-Konsole unter https://console.aws.amazon.com/rds/
. -
Wählen Sie im Navigationsbereich die Option Databases (Datenbanken) und anschließend eine DB-Instance.
-
Wählen Sie Logs & Events (Protokolle und Ereignisse).
-
Wählen Sie im Bereich CloudWatch Alarme die Option Alarm erstellen aus.
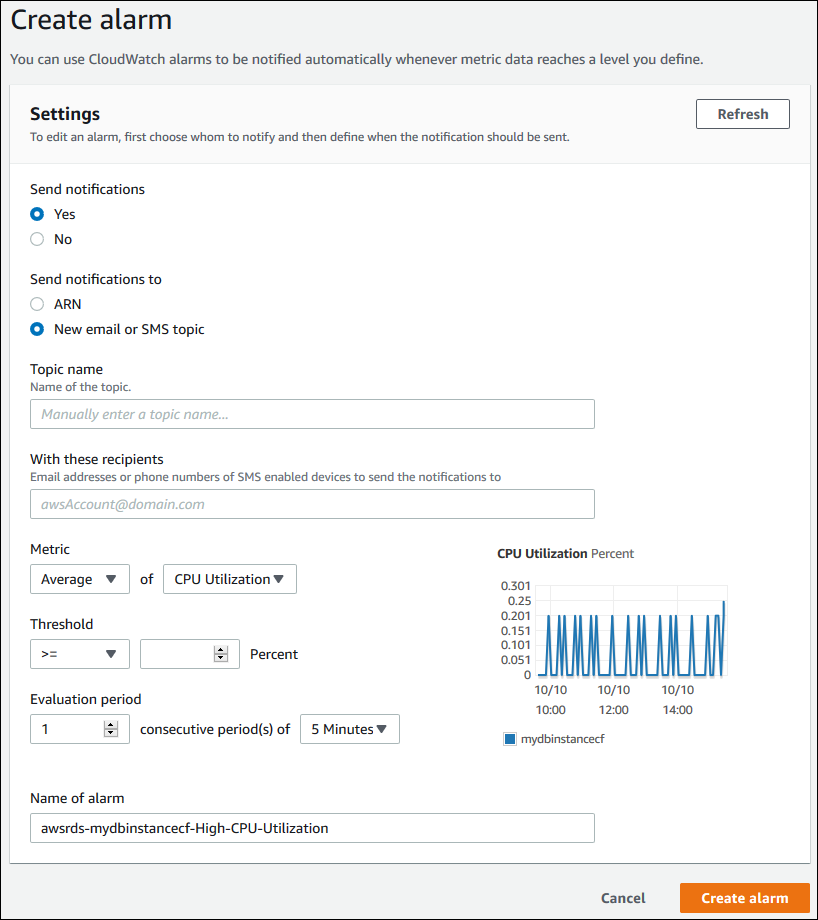
-
Wählen Sie für Send notifications (Benachrichtigungen senden) Yes (Ja) und für Send notifications to (Benachrichtigungen senden an= New email or SMS topic (Neue E-Mail oder SMS Thema).
-
Geben Sie unter Topic name (Themaname) einen Namen für die Benachrichtigung und unter With these recipients (Mit diesen Empfängern) eine kommagetrennte Liste von E-Mail-Adressen und Telefonnummern ein.
-
Wählen Sie für Metric (Metrik) die einzustellende Alarmstatistik und Metrik.
-
Geben Sie für Threshold (Schwellenwert) an, ob die Metrik größer, kleiner oder gleich dem Schwellenwert sein muss, und geben Sie den Schwellenwert an.
-
Wählen Sie unter Period (Zeitraum) den Auswertungszeitraum für den Alarm aus. Wählen Sie für consecutive period(s) of (aufeinanderfolgende Periode(n) von) den Zeitraum aus, in dem der Schwellenwert erreicht worden sein muss, um den Alarm auszulösen.
-
Geben Sie unter Alarmname einen aussagekräftigen Namen für Ihren Alarm ein.
-
Wählen Sie Create Alarm aus.
Der Alarm wird im Bereich CloudWatch Alarme angezeigt.
Auswerten von Leistungsmetriken
Eine DB-Instance besitzt eine Reihe unterschiedlicher Kategorien von Metriken. Die Entscheidung, welche Werte akzeptabel sind, ist von der Metrik abhängig.
CPU
CPU-Nutzung – Prozentsatz der verwendeten Verarbeitungskapazität des Computers.
Arbeitsspeicher
-
Freisetzbarer Arbeitsspeicher – Größe des RAM, die in der DB-Instance verfügbar ist (in Bytes). Die rote Linie in der Metrik der Registerkarte Monitoring (Überwachung) kennzeichnet 75 % für CPU-, Arbeitsspeicher- und Speichermetriken. Wenn der Speicherverbrauch der Instance diese Linie häufig überschreitet, bedeutet dies, dass Sie die Workload prüfen sollten oder die Instance aktualisieren müssen.
Swap-Nutzung – Größe des Auslagerungsbereichs, der in der DB-Instance verwendet wird (in Bytes).
Festplattenkapazität
Freier Speicherplatz – Größe des Datenträgerbereichs, der zurzeit in der DB-Instance nicht verwendet wird (in Megabytes).
Eingabe-/Ausgabe-Operationen
Lese-IOPS, Schreib-IOPS – die durchschnittliche Anzahl der Lese- oder Schreib-Datenträgeroperationen pro Sekunde.
Leselatenz, Schreiblatenz – die durchschnittliche Zeit, die eine Lese- oder Schreiboperation benötigt (in Millisekunden).
Lesedurchsatz, Schreibdurchsatz – die durchschnittliche Anzahl der Megabytes, die pro Sekunde aus dem Datenträger gelesen oder zum Datenträger geschrieben werden.
Warteschlangentiefe — Die Anzahl der I/O Operationen, die darauf warten, auf die Festplatte geschrieben oder von der Festplatte gelesen zu werden.
Netzwerkdatenverkehr
Netzwerkeingangsdurchsatz, Netzwerkübertragungsdurchsatz – die Rate des Netzwerkdatenverkehrs zur und von der DB-Instance (in Bytes pro Sekunde).
Datenbankverbindungen
Datenbankverbindungen – die Anzahl der Client-Sitzungen, die mit der DB-Instance verbunden sind.
Detailliertere einzelne Beschreibungen der verfügbaren Leistungsmetriken finden Sie unter Überwachung von Amazon RDS mit Amazon CloudWatch.
Allgemein ausgedrückt, sind die zulässigen Werte für Leistungsmetriken davon abhängig, wie die Basisleistung aussieht und welche Aufgaben von Ihrer Anwendung ausgeführt werden. Prüfen Sie, ob dauerhafte oder tendenzielle Abweichungen von Ihrer Ausgangsbasis vorliegen. Im Folgenden finden Sie ein paar Hinweise zu bestimmten Metriken:
Hohe CPU- oder RAM-Nutzung – Hohe Werte für die CPU- oder RAM-Nutzung können angemessen sein. Dies kann zum Beispiel der Fall sein, wenn sie der Zielsetzung Ihrer Anwendung entsprechen (z. B. in Bezug auf Durchsatz oder Gleichzeitigkeit) und erwartet werden.
Nutzung des Datenträgerplatzes – Überprüfen Sie die Nutzung des Datenträgerplatzes, wenn konsistent 85 Prozent oder mehr des gesamten Datenträgerplatzes belegt werden. Prüfen Sie, ob Daten in der Instance gelöscht oder auf einem anderen System archiviert werden können, um Speicherplatz freizugeben.
Netzwerkdatenverkehr – Wenden Sie sich an Ihren Systemadministrator, um zu erfahren, welcher Durchsatz für Ihr Domänennetzwerk und Ihre Internetverbindung erwartet wird. Überprüfen Sie den Netzwerkdatenverkehr, wenn der Durchsatz dauerhaft unter dem erwarteten Wert liegt.
Datenbankverbindungen – Ziehen Sie eine Einschränkung der Datenbankverbindungen in Betracht, wenn bei einer großen Anzahl von Benutzerverbindungen eine Abnahme der Instance-Leistung und der Reaktionszeit zu erkennen ist. Die optimale Anzahl der Benutzerverbindungen für Ihre DB-Instance ist von der Instance-Klasse und der Komplexität der Operationen abhängig, die ausgeführt werden. Wenn Sie die Anzahl der Datenbankverbindungen bestimmen möchten, ordnen Sie Ihre DB-Instance einer Parametergruppe zu. Legen Sie in dieser Gruppe den Parameter User Connections auf einen anderen Wert als 0 (unbegrenzt) fest. Sie können eine entweder eine vorhandene Parametergruppe verwenden oder eine neue erstellen. Weitere Informationen finden Sie unter Parametergruppen für Amazon RDS.
IOPS-Metriken – Die erwarteten Werte für IOPS-Metriken sind von der Datenträgerspezifikation und der Serverkonfiguration abhängig. Verwenden Sie die Basiswerte als typische Werte. Prüfen Sie, ob dauerhafte Abweichungen von den Werten Ihrer Ausgangsbasis vorliegen. Sie erzielen eine optimale IOPS-Leistung, wenn Sie sicherstellen, dass die typischen zu verarbeitenden Datensätze komplett in den Arbeitsspeicher geladen werden können, sodass die Lese- und Schreibvorgänge auf ein Minimum beschränkt werden.
Bei Problemen mit Leistungsmetriken sollten Sie zunächst die am häufigsten verwendeten und kostspieligsten Abfragen anpassen, um die Leistung zu verbessern. Optimieren Sie sie, um festzustellen, ob dies den Druck auf die Systemressourcen verringert. Weitere Informationen finden Sie unter Optimieren von Abfragen.
Wenn Ihre Abfragen optimiert sind und ein Problem weiterhin besteht, sollten Sie ein Upgrade Ihrer von Amazon RDS in Betracht ziehen. Sie können es auf eine Version mit mehr Ressourcen (CPU, RAM, Festplattenspeicher, Netzwerkbandbreite, I/O Kapazität) aktualisieren, die mit dem Problem zusammenhängen.
Optimieren von Abfragen
Eine der besten Möglichkeiten zur Verbesserung der Leistung von DB-Instances besteht darin, die am häufigsten verwendeten und ressourcenintensivsten Abfragen zu optimieren. Hier optimieren Sie sie, damit sie kostengünstiger ausgeführt werden können. Verwenden Sie die folgenden Ressourcen, um Informationen zur Verbesserung von Abfragen zu erhalten:
-
MySQL – Siehe SELECT-Anweisungen in der MySQL-Dokumentation optimieren
. Weitere Ressourcen zur Abfrageoptimierung finden Sie unter MySQL-Performance-Tuning- und Optimierungsressourcen . -
Oracle – Siehe Database SQL Tuning Guide
in der Oracle Datenbank-Dokumentation. -
SQL Server – Siehe Analysieren einer Abfrage
in der Microsoft-Dokumentation. Sie können auch die ausführungs-, index- und I/O-bezogenen Datenverwaltungsansichten (DMVs) verwenden, die in der Microsoft-Dokumentation unter Dynamische Systemverwaltungsansichten beschrieben sind, um Probleme mit SQL Server-Abfragen zu beheben. Ein häufiger Aspekt beim Optimieren von Abfragen stellt die Erstellung effektiver Indizes dar. Weitere Informationen zu möglichen Indexverbesserungen für Ihre DB-Instance finden Sie in der Microsoft-Dokumentation unter Database Engine Tuning Ad
Informationen zur Verwendung von Tuning Advisor für finden Sie unter . RDS für SQL Serv Analysieren Ihrer Datenbank-Workload auf einer Amazon RDS for SQL Server DB-Instance mit Database Engine Tuning Advisor. -
PostgreSQL – Siehe EXPLAIN verwenden in
der PostgreSQL-Dokumentation, um zu erfahren, wie man einen Abfrageplan analysiert. Sie können diese Informationen verwenden, um eine Abfrage oder zugrundeliegende Tabellen zu ändern, um die Abfrageleistung zu verbessern. Informationen darüber, wie Sie Joins in Ihrer Abfrage für die beste Leistung angeben, finden Sie unter Steuern des Planers mit expliziten JOIN-Klauseln
. -
MariaDB – Siehe Abfrageoptimierungen
in der MariaDB-Dokumentation.
Best Practices für die Arbeit mit MySQL
Sowohl die Tabellengröße als auch die Anzahl der Tabellen in einer MySQL-Datenbank können die Leistung beeinträchtigen.
Tabellengröße
In der Regel bestimmen Betriebssystemeinschränkungen für Dateigrößen die effektive maximale Tabellengröße für MySQL-Datenbanken. Daher werden die Grenzwerte normalerweise nicht durch interne MySQL-Einschränkungen bestimmt.
Vermeiden Sie es in MySQL-DB-Instances, dass Tabellen in Ihrer Datenbank zu groß werden. Obwohl die allgemeine Speichergrenze 64 TiB beträgt, beschränken die Begrenzungen für den bereitgestellten Speicher die maximale Größe einer MySQL-Tabellendatei auf 16 TiB. Partitionieren Sie Ihre großen Tabellen so, dass die Dateigrößen deutlich unter der 16-TiB-Grenze liegen. Dieser Ansatz kann auch Leistung und Wiederherstellungszeit verbessern. Weitere Informationen finden Sie unter MySQL-Dateigrößenlimits in Amazon RDS.
Sehr große Tabellen (mehr als 100 GB) können sich negativ auf die Leistung sowohl bei Lese- als auch bei Schreibvorgängen auswirken (einschließlich DML-Anweisungen und insbesondere DDL-Anweisungen). Indizes für große Tabellen können die Select-Performance erheblich verbessern, sie können jedoch auch die Leistung von DML-Anweisungen beeinträchtigen. DDL-Anweisungen wie ALTER TABLE können für die großen Tabellen erheblich langsamer sein, da diese Vorgänge in einigen Fällen eine Tabelle vollständig neu aufbauen können. Diese DDL-Anweisungen könnten die Tabellen für die Dauer der Operation sperren.
Die Menge an Speicher, die MySQL für Lese- und Schreibvorgänge benötigt, hängt von den Tabellen ab, die an den Vorgängen beteiligt sind. Es ist eine bewährte Methode, mindestens genug RAM zu haben, um die Indizes aktiv genutzter Tabellen zu halten. Verwenden Sie die folgende Abfrage, um die zehn größten Tabellen und Indizes in einer Datenbank zu finden:
select table_schema, TABLE_NAME, dat, idx from (SELECT table_schema, TABLE_NAME, ( data_length ) / 1024 / 1024 as dat, ( index_length ) / 1024 / 1024 as idx FROM information_schema.TABLES order by 3 desc ) a order by 3 desc limit 10;
Anzahl der Tabellen
Das zugrunde liegende Dateisystem hat möglicherweise eine Begrenzung für die Anzahl der Dateien, die Tabellen darstellen. MySQL hat jedoch keine Begrenzung für die Anzahl der Tabellen. Trotzdem kann die Gesamtzahl der Tabellen in der InnoDB-Speicher-Engine von MySQL unabhängig von der Größe dieser Tabellen zu Leistungseinbußen beitragen. Um die Auswirkungen auf das Betriebssystem zu begrenzen, können Sie die Tabellen auf mehrere Datenbanken in derselben MySQL-DB-Instance aufteilen. Dies könnte die Anzahl der Dateien in einem Verzeichnis begrenzen, löst jedoch nicht das Gesamtproblem.
Wenn es aufgrund einer großen Anzahl von Tabellen (mehr als 10 000) zu Leistungseinbußen kommt, wird dies dadurch verursacht, dass MySQL mit Speicherdateien arbeitet, sie öffnet und schließt. Um dieses Problem zu lösen, können Sie die Größe der Parameter table_open_cache und table_definition_cache erhöhen. Eine Erhöhung der Parameterwerte kann jedoch die Menge des von MySQL verwendeten Speichers erheblich erhöhen und kann sogar den gesamten verfügbaren Speicher verwenden. Weitere Informationen finden Sie unter How MySQL Opens and Closes Tables (Wie MySQL Tabellen öffnet und schließt)
Darüber hinaus können sich zu viele Tabellen erheblich auf die Startzeit von MySQL auswirken. Sowohl ein sauberes Herunterfahren als auch ein Neustart sowie eine Absturzwiederherstellung können insbesondere in Versionen vor MySQL 8.0 beeinträchtigt werden.
Wir empfehlen, insgesamt weniger als 10 000 Tabellen in allen Datenbanken einer DB-Instance zu speichern. Informationen zu einem Anwendungsfall mit einer großen Anzahl von Tabellen in einer MySQL-Datenbank finden Sie unter One Million Tables in MySQL 8.0 (1 Million Tabellen in MySQL 8.0)
Speicher-Engine
Die point-in-time Wiederherstellungs- und Snapshot-Wiederherstellungsfunktionen von Amazon RDS for MySQL erfordern eine Speicher-Engine, die nach einem Absturz wiederhergestellt werden kann. Diese Funktionen werden nur für die InnoDB-Speicher-Engine unterstützt. MySQL unterstützt zwar verschiedene Speichermodule mit unterschiedlichen Kapazitäten. Von diesen sind jedoch nicht alle für die Wiederherstellung nach einem Absturz und Datenbeständigkeit optimiert. Beispielsweise unterstützt die MyISAM-Speicher-Engine keine zuverlässige Wiederherstellung nach einem Absturz und kann verhindern, dass eine point-in-time Wiederherstellung oder Snapshot-Wiederherstellung wie beabsichtigt funktioniert. Dies kann dazu führen, dass Daten verloren gehen oder beschädigt werden, wenn MySQL nach einem Absturz erneut gestartet wird.
InnoDB ist das empfohlene und unterstützte Speichermodul für MySQL-DB-Instances in Amazon RDS. InnoDB-Instances können auch zu Aurora migriert werden, während MyISAM-Instances nicht migriert werden können. MyISAM bietet jedoch eine bessere Leistung als InnoDB, wenn Sie intensive Volltextsuchfunktionen benötigen. Wenn Sie dennoch MyISAM mit Amazon RDS verwenden möchten, kann die Befolgung der unter Automatisierte Backups mit nicht unterstützten MySQL-Speicher-Engines beschriebenen Schritte in bestimmten Szenarien helfen, eine Snapshot-Wiederherstellungsfunktion zu erhalten.
Wenn Sie vorhandene MyISAM-Tabellen in InnoDB-Tabellen konvertieren möchten, können Sie den unter Converting Tables from MyISAM to InnoDB
Darüber hinaus wird die Federated Storage Engine aktuell von Amazon RDS für MySQL nicht unterstützt.
Best Practices für die Arbeit mit MariaDB
Sowohl Tabellengrößen als auch die Anzahl der Tabellen in einer MariaDB-Datenbank können sich auf die Performance auswirken.
Tabellengröße
In der Regel bestimmen Betriebssystemeinschränkungen für Dateigrößen die effektive maximale Tabellengröße für MariaDB-Datenbanken. Daher werden die Grenzwerte normalerweise nicht durch interne MariaDB-Einschränkungen festgelegt.
Vermeiden Sie es in MariaDB-Instances, dass Tabellen in Ihrer Datenbank zu groß werden. Obwohl die allgemeine Speichergrenze 64 TiB beträgt, beschränken die Begrenzungen für den bereitgestellten Speicher die maximale Größe einer MariaDB-Tabellendatei auf 16 TiB. Partitionieren Sie Ihre großen Tabellen so, dass die Dateigrößen deutlich unter der 16-TiB-Grenze liegen. Dieser Ansatz kann auch Leistung und Wiederherstellungszeit verbessern.
Sehr große Tabellen (mehr als 100 GB) können sich negativ auf die Leistung sowohl bei Lese- als auch bei Schreibvorgängen auswirken (einschließlich DML-Anweisungen und insbesondere DDL-Anweisungen). Indizes für große Tabellen können die Select-Performance erheblich verbessern, sie können jedoch auch die Leistung von DML-Anweisungen beeinträchtigen. DDL-Anweisungen wie ALTER TABLE können für die großen Tabellen erheblich langsamer sein, da diese Vorgänge in einigen Fällen eine Tabelle vollständig neu aufbauen können. Diese DDL-Anweisungen könnten die Tabellen für die Dauer der Operation sperren.
Die Menge an Speicher, die MariaDB für Lese- und Schreibvorgänge benötigt, hängt von den an den Operationen beteiligten Tabellen ab. Es ist eine bewährte Methode, mindestens genug RAM zu haben, um die Indizes aktiv genutzter Tabellen zu halten. Verwenden Sie die folgende Abfrage, um die zehn größten Tabellen und Indizes in einer Datenbank zu finden:
select table_schema, TABLE_NAME, dat, idx from (SELECT table_schema, TABLE_NAME, ( data_length ) / 1024 / 1024 as dat, ( index_length ) / 1024 / 1024 as idx FROM information_schema.TABLES order by 3 desc ) a order by 3 desc limit 10;
Anzahl der Tabellen
Das zugrunde liegende Dateisystem hat möglicherweise eine Begrenzung für die Anzahl der Dateien, die Tabellen darstellen. MariaDB hat jedoch keine Begrenzung für die Anzahl der Tabellen. Trotzdem kann die Gesamtzahl der Tabellen in der InnoDB-Speicher-Engine von MariaDB unabhängig von der Größe dieser Tabellen zu Leistungseinbußen beitragen. Um die Auswirkungen auf das Betriebssystem zu begrenzen, können Sie die Tabellen auf mehrere Datenbanken in derselben MariaDB-Instance aufteilen. Dies könnte die Anzahl der Dateien in einem Verzeichnis begrenzen, löst jedoch nicht das Gesamtproblem.
Wenn es aufgrund einer großen Anzahl von Tabellen (mehr als 10 000) zu Leistungseinbußen kommt, wird dies dadurch verursacht, dass MariaDB mit Speicherdateien arbeitet. Diese Arbeit umfasst das Öffnen und Schließen von Speicherdateien durch MariaDB. Um dieses Problem zu lösen, können Sie die Größe der Parameter table_open_cache und table_definition_cache erhöhen. Eine Erhöhung der Werte dieser Parameter könnte jedoch die Menge des von MariaDB verwendeten Speichers erheblich erhöhen. Es könnte sogar der gesamte verfügbare Speicher belegt werden. Weitere Informationen finden Sie unter Optimizing table_open_cache (table_open_cache optimieren)
Darüber hinaus können zu viele Tabellen die Startzeit von MariaDB erheblich beeinflussen. Sowohl ein sauberes Herunterfahren und Neustart als auch eine Absturzwiederherstellung können beeinträchtigt werden. Wir empfehlen, insgesamt weniger als zehntausend Tabellen in allen Datenbanken einer DB-Instance zu haben.
Speicher-Engine
Die point-in-time Wiederherstellungs- und Snapshot-Wiederherstellungsfunktionen von Amazon RDS for MariaDB erfordern eine Speicher-Engine, die nach einem Absturz wiederhergestellt werden kann. MariaDB unterstützt zwar mehrere Speicher-Engines mit unterschiedlichen Fähigkeiten und Kapazitäten, jedoch sind nicht alle von ihnen für die Wiederherstellung nach Ausfall und für Datenbeständigkeit optimiert. Aria ist zwar ein absturzsicherer Ersatz für MyISAM, kann aber dennoch verhindern, dass eine point-in-time Wiederherstellung oder Snapshot-Wiederherstellung wie beabsichtigt funktioniert. Dies kann dazu führen, dass Daten verloren gehen oder beschädigt werden, wenn MariaDB nach einem Absturz erneut gestartet wird. InnoDB ist das empfohlene und unterstützte Speichermodul für MariaDB-DB-Instances in Amazon RDS. Wenn Sie dennoch Aria mit Amazon RDS verwenden möchten, kann die Befolgung der unter Automatisierte Backups mit nicht unterstützten MariaDB-Speicher-Engines beschriebenen Schritte in bestimmten Szenarien helfen, eine Snapshot-Wiederherstellungsfunktion zu erhalten.
Wenn Sie vorhandene MyISAM-Tabellen in InnoDB-Tabellen konvertieren möchten, können Sie den unter Converting Tables from MyISAM to InnoDB
Bewährte Methoden für die Arbeit mit Oracle
Informationen zu bewährten Methoden für die Arbeit mit Amazon RDS für Oracle finden Sie unter Bewährte Methoden für die Ausführung von Oracle-Datenbanken in Amazon Web Services.
Ein AWS virtueller Workshop im Jahr 2020 beinhaltete eine Präsentation über den Betrieb von Oracle-Produktionsdatenbanken auf Amazon RDS. Das Video der Präsentation ist hier verfügbar:
Bewährte Methoden für die Arbeit mit PostgreSQL
Es gibt zwei wichtige Bereiche, in denen Sie die Leistung von RDS für PostgreSQL verbessern können. Einer davon ist das Laden von Daten in eine DB-Instance. Der andere Bereich betrifft die Verwendung der PostgreSQL-Selbstbereinigungsfunktion. In den folgenden Abschnitten werden einige der empfohlenen Verfahren für diese Bereiche beschrieben.
Informationen darüber, wie andere häufige PostgreSQL-DBA-Aufgaben Amazon RDS implementiert werden, finden Sie unter Häufige DBA-Aufgaben für Amazon RDS für PostgreSQL.
Laden von Daten in eine PostgreSQL-DB-Instance
Beim Laden von Daten in eine DB-Instance von Amazon RDS für PostgreSQL sollten Sie Ihre DB-Instance-Einstellungen und Ihre DB-Parametergruppenwerte ändern. Legen Sie diese fest, um den effizientesten Import von Daten in Ihre DB-Instance zu ermöglichen.
Ändern Sie die Einstellungen für Ihre DB-Instance wie folgt:
-
Deaktivieren Sie die DB-Instance-Sicherungen (Sicherungsaufbewahrung auf 0 setzen).
-
Deaktivieren Sie Multi-AZ.
Modifizieren Sie die DB-Parametergruppe so, dass sie die folgenden Einstellungen enthält. Testen Sie außerdem die Parametereinstellungen, um die effizientesten Einstellungen für Ihre DB-Instance zu ermitteln.
-
Erhöhen Sie den Wert des Parameters
maintenance_work_mem. Weitere Informationen zu PostgreSQL-Ressourcennutzungsparametern finden Sie in der PostgreSQL-Dokumentation. -
Erhöhen Sie den Wert der Parameter
max_wal_sizeundcheckpoint_timeout, um die Zahl der Schreibvorgänge zum Write-Ahead (WAL)-Protokoll zu reduzieren. -
Parameter
synchronous_commitdeaktivieren. -
Deaktivieren Sie den PostgreSQL-Selbstbereinigungsparameter.
-
Stellen Sie sicher, dass sämtliche Tabellen, die Sie importieren, protokolliert sind. In nicht protokollierten Tabellen gespeicherte Daten können bei einem Failover verloren gehen. Weitere Informationen finden Sie unter CREATE TABLE UNLOGGED
.
Verwenden Sie den Befehl pg_dump -Fc (komprimiert) oder den Befehl pg_restore -j (parallel) mit diesen Einstellungen.
Nachdem der Ladevorgang abgeschlossen ist, setzen Sie Ihre DB-Instance und DB-Parameter auf ihre normalen Einstellungen zurück.
Arbeiten mit der PostgreSQL-Selbstbereinigungsfunktion
Die Selbstbereinigungsfunktion für PostgreSQL-Datenbanken ist eine Funktion, deren Verwendung nachdrücklich empfohlen wird, um die Integrität Ihrer PostgreSQL-DB-Instance zu wahren. Die Selbstbereinigung automatisiert die Ausführung der Befehle VACUUM und ANALYZE. Die Verwendung der Selbstbereinigung wird von PostgreSQL erfordert, nicht von Amazon RDS auferlegt, und ist von kritischer Bedeutung für eine gute Leistung. Die Funktion ist für alle neuen DB-Instances von Amazon RDS für PostgreSQL standardmäßig aktiviert. Die zugehörigen Konfigurationsparameter werden standardmäßig entsprechend festgelegt.
Ihr Datenbankadministrator muss diese Wartungsoperation kennen und verstehen. Die PostgreSQL-Dokumentation zu Autocauger finden Sie unter Der Autovacuum Daemon
Die Selbstbereinigung ist keine „ressourcenlose“ Operation, sondern wird im Hintergrund ausgeführt und gibt Benutzeroperationen soweit möglich Vorrang. Bei Aktivierung prüft die Selbstbereinigung auf Tabellen mit einer großen Zahl von aktualisierten oder gelöschten Tupeln. Sie schützt darüber hinaus vor dem Verlust sehr alter Daten aufgrund von Transaktions-ID-Wraparounds. Weitere Informationen finden Sie unter Verhindern von Transaktions-ID-Wraparound-Fehlern
Die Selbstbereinigung sollte nicht als Operation mit hohem Overhead betrachtet werden, die reduziert werden kann, um eine bessere Leistung zu erzielen. Im Gegenteil; die Leistung von Tabellen mit sehr häufigen Aktualisierungs- und Löschvorgängen wird mit der Zeit schnell abnehmen, wenn keine Selbstbereinigung ausgeführt wird.
Wichtig
Die fehlende Ausführung von Selbstbereinigungen kann dazu führen, dass letzten Endes eine Ausfallzeit erforderlich ist, um eine VACUUM-Operation auszuführen, die sehr viel größere Auswirkungen hat. In einigen Fällen kann eine DB-Instance von RDS für PostgreSQL aufgrund einer zu konservativen Verwendung der Selbstbereinigungsfunktion nicht mehr verfügbar sein. In diesen Fällen wird die PostgreSQL-Datenbank heruntergefahren, um sich selbst zu schützen. Zu diesem Zeitpunkt muss Amazon RDS ein single-user-mode vollständiges Vakuum direkt auf der DB-Instance durchführen. Diese vollständige Bereinigung kann zu einem Ausfall von mehreren Stunden führen. Daher wird dringend empfohlen, die standardmäßig aktivierte Selbstbereinigung nicht zu deaktivieren.
Die Selbstbereinigungsparameter legen fest, wann und wie die harte Selbstbereinigung ausgeführt wird. Die Parameterautovacuum_vacuum_threshold und autovacuum_vacuum_scale_factor legen fest, wann die Selbstbereinigung ausgeführt wird. Die Parameter autovacuum_max_workers, autovacuum_nap_time, autovacuum_cost_limit und autovacuum_cost_delay legen fest, wie die harte Selbstbereinigung ausgeführt wird. Weitere Informationen zu Autovakuum, wann es ausgeführt wird und welche Parameter erforderlich sind, finden Sie unter Routine Vacuuming
Die folgende Abfrage zeigt die Anzahl der „toten“ Tupel in einer Tabelle mit dem Namen table1:
SELECT relname, n_dead_tup, last_vacuum, last_autovacuum FROM pg_catalog.pg_stat_all_tables WHERE n_dead_tup > 0 and relname = 'table1';
Die Ergebnisse der Abfrage sehen ähnlich wie folgt aus:
relname | n_dead_tup | last_vacuum | last_autovacuum ---------+------------+-------------+----------------- tasks | 81430522 | | (1 row)
Amazon RDS für PostgreSQL Video zu bewährten Praktiken
Die AWS re:Invent-Konferenz 2020 beinhaltete eine Präsentation über neue Funktionen und bewährte Methoden für die Arbeit mit PostgreSQL auf Amazon RDS. Das Video der Präsentation ist hier verfügbar:
Bewährte Methoden für die Arbeit mit SQL Server
Zu den bewährten Methoden für eine Multi-AZ-Bereitstellung mit einer SQL Server-DB-Instance gehören:
Verwenden Sie Amazon-RDS-DB-Ereignisse, um Failover zu überwachen. Beispielsweise können Sie per Textnachricht oder E-Mail benachrichtigt werden, wenn ein Failover für eine DB-Instance ausgeführt wird. Weitere Informationen über Amazon-RDS-Ereignisse finden Sie unter Arbeiten mit Amazon-RDS-Ereignisbenachrichtigungen.
Wenn Ihre Anwendung DNS-Werte zwischenspeichert, legen Sie den Time-to-Live (TTL)-Wert auf weniger als 30 Sekunden fest. Diese TTL-Einstellung stellt eine bewährte Methode für den Fall dar, dass ein Failover auftritt. Bei einem Failover kann sich die IP-Adresse ändern und der zwischengespeicherte Wert wird möglicherweise nicht mehr verwendet.
Es wird empfohlen, die folgenden Modi nicht zu aktivieren, da sie die Transaktionsprotokollierung deaktivieren, die für Multi-AZ erforderlich ist:
-
Einfacher Wiederherstellungsmodus
-
Offlinemodus
-
Schreibgeschützter Modus
-
Führen Sie Tests durch, um zu ermitteln, wie lange Ihre DB-Instance für einen Failover-Vorgang benötigt. Die Failover-Zeit kann unterschiedlich sein, abhängig von der Datenbank, der Instance-Klasse und des Speichertyps, die oder den Sie verwenden. Sie sollten auch die Fähigkeit Ihrer Anwendung testen, bei einem Failover weiter ausgeführt zu werden.
Führen Sie die folgenden Schritte aus, um die Failover-Zeit zu verkürzen:
Stellen Sie sicher, dass Sie Ihrem Workload ausreichend bereitgestellte IOPS zugeteilt haben. Unzulänglich. I/O can lengthen failover times. Database recovery requires I/O
Verwenden Sie kleinere Transaktionen. Die Datenbankwiederherstellung ist von Transaktionen abhängig. Wenn Sie daher große Transaktionen in mehrere kleinere Transaktionen aufteilen können, sollte die Failover-Zeit verkürzt werden.
Berücksichtigen Sie, dass es während eines Failovers zu erhöhten Latenzen kommt. Als Teil des Failover-Vorgangs repliziert Amazon RDS Ihre Daten automatisch zu einer neuen Standby-Instance. Diese Replikation bedeutet, dass neue Daten an zwei verschiedene DB-Instances übergeben werden. Daher kann es eine gewisse Latenz geben, bis die Standby-DB-Instance mit der neuen primäre DB-Instance aufgeschlossen hat.
Stellen Sie Ihre Anwendungen in allen Availability Zones bereit. Wenn eine Availability Zone ausfällt, sind die Anwendungen in den anderen Availability Zones weiterhin verfügbar.
Denken Sie bei der Arbeit mit einer Multi-AZ-Bereitstellung von SQL Server daran, dass Amazon RDS Replicas für alle SQL Server-Datenbanken auf Ihrer Instance erstellt. Wenn Sie nicht möchten, dass bestimmte Datenbanken sekundäre Replicas aufweisen, richten Sie eine separate DB-Instance ein, die für diese Datenbanken keine Multi-AZ verwendet.
Video zu bewährten Methoden für Amazon RDS für SQL Server
Die AWS re:Invent-Konferenz 2019 beinhaltete eine Präsentation über neue Funktionen und bewährte Methoden für die Arbeit mit SQL Server auf Amazon RDS. Das Video der Präsentation ist hier verfügbar:
Arbeiten mit DB-Parametergruppen
Es wird empfohlen, DB-Parametergruppenänderungen stets zuerst in einer Test-DB-Instance durchzuführen, bevor Sie diese Parametergruppenänderungen auf Ihre Produktions-DB-Instances anwenden. Wenn die DB-Modulparameter in einer DB-Parametergruppe falsch festgelegt werden, kann dies unbeabsichtigte nachteilige Auswirkungen haben, einschließlich verminderter Leistung und Systeminstabilität. Gehen Sie stets vorsichtig vor, wenn Sie DB-Modulparameter ändern, und sichern Sie Ihre DB-Instance, bevor Sie eine DB-Parametergruppe ändern.
Informationen zum Sichern Ihrer DB-Instance finden Sie unter Sichern, Wiederherstellen und Exportieren von Daten.
Bewährte Methoden zur Automatisierung der DB-Instance-Erstellung
Es ist eine bewährte Methode für Amazon RDS, eine DB-Instance mit der bevorzugten Nebenversion des Datenbankmoduls zu erstellen. Sie können die AWS CLI Amazon RDS-API oder verwenden, AWS CloudFormation um die Erstellung von DB-Instances zu automatisieren. Wenn Sie diese Methoden verwenden, können Sie nur die Hauptversion angeben und Amazon RDS erstellt die Instance mit der bevorzugten Nebenversion automatisch. ..Wenn zum Beispiel PostgreSQL 12.5 die bevorzugte Nebenversion ist und Sie Version 12 mit create-db-instance angeben, wird die DB-Instance Version 12.5 sein.
Um die bevorzugte Nebenversion zu ermitteln, können Sie den Befehl describe-db-engine-versions mit der Option --default-only ausführen; siehe folgendes Beispiel.
aws rds describe-db-engine-versions --default-only --engine postgres { "DBEngineVersions": [ { "Engine": "postgres", "EngineVersion": "12.5", "DBParameterGroupFamily": "postgres12", "DBEngineDescription": "PostgreSQL", "DBEngineVersionDescription": "PostgreSQL 12.5-R1", ...some output truncated... } ] }
Informationen zum programmgesteuerten Erstellen von DB-Instances finden Sie in den folgenden Ressourcen:
Mit dem AWS CLI — create-db-instance
Verwenden der Amazon RDS-API — Erstellen DBInstance
Verwenden von AWS CloudFormation — AWS: :RDS:: DBInstance
Video zu den neuen Funktionen in Amazon RDS
Die AWS re:Invent-Konferenz 2023 beinhaltete eine Präsentation über neue Amazon RDS-Funktionen. Das Video der Präsentation ist hier verfügbar:
