Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Skalierungsrichtlinie basierend auf Amazon SQS
Wichtig
Die folgenden Informationen und Schritte zeigen Ihnen, wie Sie den Amazon SQS-Warteschlangen-Backlog pro Instance anhand des ApproximateNumberOfMessages Queue-Attributs berechnen, bevor Sie ihn als benutzerdefinierte Metrik für veröffentlichen. CloudWatch Sie können jetzt jedoch die Kosten und den Aufwand für die Veröffentlichung Ihrer eigenen Metrik sparen, indem Sie metrische Berechnungen verwenden. Weitere Informationen finden Sie unter Erstellen Sie mithilfe metrischer Mathematik eine Skalierungsrichtlinie für die Zielverfolgung.
Sie können Ihre Auto Scaling Scaling-Gruppe als Reaktion auf Änderungen der Systemlast in einer Amazon Simple Queue Service (Amazon SQS) -Warteschlange skalieren. Weitere Informationen zur Verwendung von Amazon SQS finden Sie im Amazon Simple Queue Service-Entwicklerhandbuch.
Es gibt einige Szenarien, in denen Sie als Reaktion auf Aktivitäten in einer Amazon SQS-Warteschlange eine Skalierung erwägen könnten. Angenommen, Sie haben eine Webanwendung, mit der Benutzer Bilder hochladen und online verwenden können. In diesem Szenario erfordert jedes Image eine Größenanpassung und Codierung, bevor es veröffentlicht werden kann. Die App läuft auf EC2 Instances in einer Auto Scaling Scaling-Gruppe und ist so konfiguriert, dass sie Ihre typischen Upload-Raten verarbeitet. Fehlerhafte Instances werden beendet und ersetzt, um stets dieselbe Anzahl an Instances zu nutzen. Die App platziert die Raw-Bitmap-Daten der Bilder in eine SQS-Warteschlange für die Verarbeitung. Sie verarbeitet die Bilder und veröffentlicht die verarbeiteten Bilder, wo sie von Benutzern angezeigt werden können. Die Architektur für dieses Szenario funktioniert gut, wenn die Anzahl der Image-Uploads nicht im Laufe der Zeit variiert. Wenn sich die Anzahl der Uploads jedoch mit der Zeit ändert, könnten Sie eine dynamische Skalierung in Betracht ziehen, um die Kapazität Ihrer Auto-Scaling-Gruppe zu skalieren.
Inhalt
Zielverfolgung mit der richtigen Metrik verwenden
Wenn Sie eine Skalierungsrichtlinie für die Ziel-Nachverfolgung verwenden, die auf einer benutzerdefinierten Amazon SQS-Warteschlangenmetrik basiert, kann die dynamische Skalierung eine effektivere Anpassung an die Bedarfskurve Ihrer Anwendung vornehmen. Weitere Informationen zum Auswählen von Metriken für die Zielverfolgung finden Sie unter Auswahl von Metriken.
Das Problem bei der Verwendung einer CloudWatch Amazon SQS-Metrik wie ApproximateNumberOfMessagesVisible für die Zielverfolgung besteht darin, dass sich die Anzahl der Nachrichten in der Warteschlange möglicherweise nicht proportional zur Größe der Auto Scaling Scaling-Gruppe ändert, die Nachrichten aus der Warteschlange verarbeitet. Das liegt daran, dass die Anzahl der Nachrichten in der SQS-Warteschlange nicht alleine die Anzahl der erforderlichen Instances definiert. Tatsächlich kann die Anzahl der Instances in Ihrer Auto-Scaling-Gruppe von mehreren Faktoren abhängen, einschließlich der für die Verarbeitung einer Nachricht benötigten Zeit und der akzeptablen zeitlichen Latenz (Warteschlangenverzögerung).
Die Lösung besteht darin, eine Rückstand pro Instance-Metrik zu verwenden, deren Zielwert der zulässige Rückstand pro Instance ist, der aufrechterhalten werden soll. Sie können diese Zahlen wie folgt berechnen:
-
Rückstand pro Instance: Um den Rückstand pro Instance zu berechnen, verwenden Sie zunächst das Warteschlangenattribut
ApproximateNumberOfMessages, um die Länge der SQS-Warteschlange (Anzahl der Nachrichten, die zum Abrufen aus der Warteschlange verfügbar sind) zu bestimmen. Dividieren Sie diese Zahl durch die laufende Kapazität der Flotte, welche bei einer Auto-Scaling-Gruppe die Anzahl der Instances mit dem StatusInServiceist, um so den Rückstand pro Instance zu erhalten. -
Zulässiger Rückstand pro Instance: Um Ihren Zielwert zu berechnen, bestimmen Sie zunächst, welche zeitliche Latenz Ihre Anwendung akzeptieren kann. Nehmen Sie dann den akzeptablen Latenzwert und dividieren Sie ihn durch die durchschnittliche Zeit, die eine EC2 Instance für die Verarbeitung einer Nachricht benötigt.
Ein Beispiel: Angenommen, Sie verfügen über eine Auto-Scaling-Gruppe mit 10 Instances und die Anzahl sichtbarer Nachrichten in der Warteschlange (ApproximateNumberOfMessages) ist 1 500. Wenn die durchschnittliche Verarbeitungszeit pro Nachricht 0,1 Sekunden beträgt und die längste akzeptable Latenz 10 Sekunden ist, dann ist der zulässige Rückstand pro Instance 10/0,1, was 100 Nachrichten entspricht. Dies bedeutet, dass 100 der Zielwert für Ihre Ziel-Nachverfolgungsrichtlinie ist. Wenn der Rückstand pro Instance den Zielwert erreicht, wird ein Aufskalierungsereignis ausgelöst. Da der Rückstand pro Instance bereits bei 150 Nachrichten liegt (1 500 Nachrichten / 10 Instances), wird Ihre Gruppe um fünf Instances aufskaliert, um die Proportion zum Zielwert beizubehalten.
Die folgenden Verfahren veranschaulichen, wie Sie die benutzerdefinierte Metrik veröffentlichen und die Skalierungsrichtlinie für die Ziel-Nachverfolgung erstellen, die Ihre Auto-Scaling-Gruppe zum Skalieren basierend auf diesen Berechnungen konfiguriert.
Wichtig
Denken Sie daran, zur Kostensenkung stattdessen metrische Berechnungen zu verwenden. Weitere Informationen finden Sie unter Erstellen Sie mithilfe metrischer Mathematik eine Skalierungsrichtlinie für die Zielverfolgung.
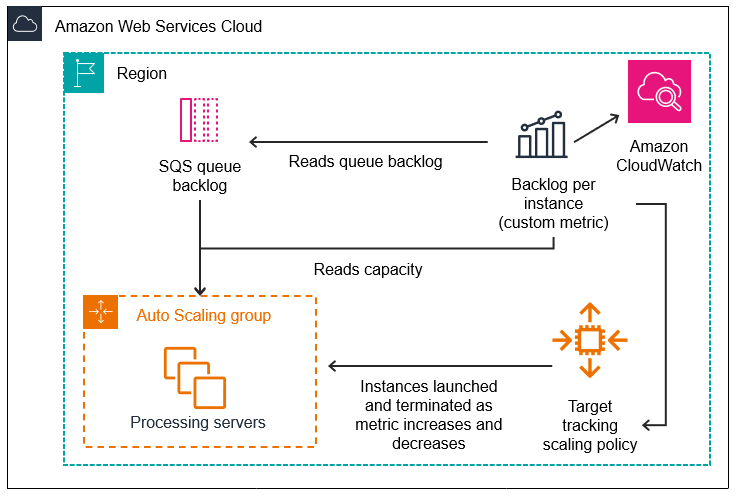
Es gibt drei Hauptkomponenten dieser Konfiguration:
-
Eine Auto Scaling Scaling-Gruppe zur Verwaltung von EC2 Instances für die Verarbeitung von Nachrichten aus einer SQS-Warteschlange.
-
Eine benutzerdefinierte Metrik, die an Amazon CloudWatch gesendet wird und die Anzahl der Nachrichten in der Warteschlange pro EC2 Instance in der Auto Scaling Scaling-Gruppe misst.
-
Eine Zielverfolgungsrichtlinie, die Ihre Auto Scaling Scaling-Gruppe so konfiguriert, dass sie auf der Grundlage der benutzerdefinierten Metrik und eines festgelegten Zielwerts skaliert. CloudWatch Alarme rufen die Skalierungsrichtlinie auf.
Das folgende Diagramm illustriert die Architektur dieser Konfiguration.
Einschränkungen
Sie müssen das AWS CLI oder ein SDK verwenden, um Ihre benutzerdefinierte Metrik zu CloudWatch veröffentlichen. Anschließend können Sie Ihre Metrik mit dem überwachen AWS Management Console.
In den folgenden Abschnitten verwenden Sie die AWS CLI für die Aufgaben, die Sie ausführen müssen. Um beispielsweise Metrikdaten abzurufen, die die aktuelle Nutzung der Warteschlange widerspiegeln, verwenden Sie den get-queue-attributes
Amazon SQS und Instance-Skaliterungsschutz
Sofern beim Beenden einer Instance noch nicht verarbeitete Nachrichten vorhanden sind, werden diese an die SQS-Warteschlange zurückgegeben und können von einer anderen ausgeführten Instance verarbeitet werden. Für Anwendungen, in denen Aufgaben mit langer Ausführung ausgeführt werden, können Sie optional den Instance-Scale-in-Schutz verwenden, um die Kontrolle darüber zu haben, welche Warteschlangen-Worker beendet werden, wenn Ihre Auto-Scaling-Gruppe skaliert wird.
Der folgende Pseudocode zeigt eine Möglichkeit zum Schutz langjähriger, warteschlangengesteuerter Worker-Prozesse vor Scale-In-Beendigung.
while (true) { SetInstanceProtection(False); Work = GetNextWorkUnit(); SetInstanceProtection(True); ProcessWorkUnit(Work); SetInstanceProtection(False); }
Weitere Informationen finden Sie unter Gestalten Sie Ihre Anwendungen so, dass sie die Instance-Kündigung ordnungsgemäß handhaben.
