Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
AWS Glue Komponenten
AWS Glue bietet eine Konsole und API-Operationen zum Einrichten und Verwalten Ihres ETL-Workloads (Extrahieren, Transformieren und Laden). Sie können API-Operationen über mehrere sprachspezifische Funktionen SDKs und die AWS Command Line Interface ()AWS CLI verwenden. Informationen zur Verwendung von finden Sie unter AWS CLI Befehlsreferenz. AWS CLI
AWS Glue verwendet die AWS Glue Data Catalog , um Metadaten zu Datenquellen, Transformationen und Zielen zu speichern. Der Data Catalog ist ein Drop-In-Ersatz für den Apache-Hive-Metastore. Das AWS Glue Jobs system bietet eine verwaltete Infrastruktur für die Definition, Planung und Ausführung von ETL-Vorgängen für Ihre Daten. Weitere Informationen zur AWS Glue API finden Sie unterAWS Glue API.
AWS Glue Konsole
Sie verwenden die AWS Glue Konsole, um Ihren ETL-Workflow zu definieren und zu orchestrieren. Die Konsole ruft mehrere API-Operationen im AWS Glue Data Catalog und AWS Glue Jobs system auf, um die folgenden Aufgaben auszuführen:
-
Definieren Sie AWS Glue Objekte wie Jobs, Tabellen, Crawler und Verbindungen.
-
Planen, wann Crawler ausgeführt werden.
-
Definieren von Ereignissen oder Zeitplänen für Auftragsauslöser.
-
Suchen und filtern Sie AWS Glue Objektlisten.
-
Bearbeiten von Transformationskripts.
AWS Glue Data Catalog
Das AWS Glue Data Catalog ist Ihr persistenter Speicher für technische Metadaten in der AWS Cloud.
Jedes AWS Konto hat eines AWS Glue Data Catalog pro AWS Region. Jeder Datenkatalog ist eine hoch skalierbare Sammlung von Tabellen, die in Datenbanken organisiert sind. Eine Tabelle ist eine Metadatendarstellung einer Sammlung strukturierter oder halbstrukturierter Daten, die in Quellen wie Amazon RDS, Apache Hadoop Distributed File System, Amazon OpenSearch Service und anderen gespeichert sind. Sie AWS Glue Data Catalog bietet ein einheitliches Repository, in dem unterschiedliche Systeme Metadaten speichern und finden können, um den Überblick über Daten in Datensilos zu behalten. Sie können die Metadaten dann verwenden, um diese Daten in einer Vielzahl von Anwendungen konsistent abzufragen und zu transformieren.
Sie verwenden den Datenkatalog zusammen mit AWS Identity and Access Management Richtlinien und Lake Formation, um den Zugriff auf die Tabellen und Datenbanken zu kontrollieren. Auf diese Weise können Sie verschiedenen Gruppen in Ihrem Unternehmen erlauben, Daten sicher für die gesamte Organisation zu veröffentlichen, während vertrauliche Informationen auf sehr granulare Weise geschützt werden.
Der Datenkatalog bietet Ihnen zusammen mit CloudTrail Lake Formation auch umfassende Audit- und Governance-Funktionen mit Nachverfolgung von Schemaänderungen und Datenzugriffskontrollen. Auf diese Weise stellen Sie sicher, dass Daten nicht unangemessen geändert oder versehentlich freigegeben werden.
Informationen zum Sichern und Prüfen finden Sie unter AWS Glue Data Catalog:
-
AWS Lake Formation – Weitere Informationen finden Sie unter Was ist AWS Lake Formation? im AWS Lake Formation -Entwicklerhandbuch.
-
CloudTrail— Weitere Informationen finden Sie unter Was ist CloudTrail? im AWS CloudTrail Benutzerhandbuch.
Im Folgenden finden Sie weitere AWS Dienste und Open-Source-Projekte, die Folgendes verwenden: AWS Glue Data Catalog
-
Amazon Athena – Weitere Informationen finden Sie unter Grundlegendes zu Tabellen, Datenbanken und zum Data Catalog im Amazon-Athena-Benutzerhandbuch.
-
Amazon Redshift Spectrum – Weitere Informationen finden Sie unter Verwenden von Amazon Redshift Spectrum zum Abfragen externer Daten im Datenbank-Entwicklerhandbuch für Amazon Redshift.
-
Amazon EMR – Weitere Informationen finden Sie unter Verwenden von ressourcenbasierten Richtlinien für Amazon-EMR-Zugriff auf AWS Glue Data Catalog im Amazon-EMR-Managementhandbuch.
-
AWS Glue Data Catalog Client für Apache Hive Metastore — Weitere Informationen zu diesem GitHub Projekt finden Sie unter AWS Glue Data Catalog Client für Apache
Hive Metastore.
AWS Glue Crawler und Klassifikatoren
AWS Glue ermöglicht es Ihnen auch, Crawler einzurichten, die Daten in allen Arten von Repositorys scannen, klassifizieren, Schemainformationen daraus extrahieren und die Metadaten automatisch in der speichern können. AWS Glue Data Catalog AWS Glue Data Catalog Sie können dann zur Steuerung von ETL-Vorgängen verwendet werden.
Informationen dazu, wie Crawler und Classifier eingerichtet werden, finden Sie unter Verwenden von Crawlern zum Auffüllen des Datenkatalogs . Informationen zur Programmierung von Crawlern und Classifiern mithilfe der AWS Glue API finden Sie unter. Crawler- und Classifier-API
AWS Glue ETL-Operationen
Mithilfe der Metadaten im Datenkatalog AWS Glue können automatisch Scala- oder PySpark (die Python-API für Apache Spark) -Skripts mit AWS Glue Erweiterungen generiert werden, die Sie verwenden und ändern können, um verschiedene ETL-Operationen auszuführen. Sie können beispielsweise Rohdaten extrahieren, bereinigen und umwandeln und das Ergebnis anschließend in einem anderen Repository speichern, wo es abgefragt und analysiert werden kann. Ein solches Skript könnte eine CSV-Datei in ein relationales Format konvertieren und in Amazon Redshift speichern.
Weitere Informationen zur Verwendung von AWS Glue ETL-Funktionen finden Sie unterProgrammieren von Spark-Skripte.
ETL einstreamen AWS Glue
AWS Glue ermöglicht es Ihnen, ETL-Operationen mit Streaming-Daten mithilfe kontinuierlich ausgeführter Jobs durchzuführen. AWS Glue Streaming-ETL basiert auf der Apache Spark Structured Streaming Engine und kann Streams von Amazon Kinesis Data Streams, Apache Kafka und Amazon Managed Streaming for Apache Kafka (Amazon MSK) aufnehmen. Streaming-ETL kann Streaming-Daten bereinigen und transformieren und in Amazon-S3- oder JDBC-Datastores laden. Verwenden Sie Streaming ETL in AWS Glue , um Ereignisdaten wie IoT-Streams, Clickstreams und Netzwerkprotokolle zu verarbeiten.
Wenn Sie das Schema der Streaming-Datenquelle kennen, können Sie es in einer Data-Catalog-Tabelle angeben. Andernfalls können Sie die Schemaerkennung im Streaming-ETL-Auftrag aktivieren. Der Auftrag bestimmt dann automatisch das Schema aus den eingehenden Daten.
Der Streaming-ETL-Job kann sowohl AWS Glue integrierte Transformationen als auch Transformationen verwenden, die systemeigenen Transformationen von Apache Spark Structured Streaming sind. Weitere Informationen finden Sie unter Operations on streaming DataFrames /Datasets auf der Apache
Weitere Informationen finden Sie unter Streaming-ETL-Aufträge in AWS Glue.
Das Jobsystem AWS Glue
Das AWS Glue Jobs system bietet eine verwaltete Infrastruktur zur Orchestrierung Ihres ETL-Workflows. Sie können Jobs erstellen AWS Glue , die die Skripts automatisieren, die Sie zum Extrahieren, Transformieren und Übertragen von Daten an verschiedene Speicherorte verwenden. Aufträge können zeitlich geplant und verkettet werden. Oder sie können von Ereignissen wie etwa dem Eintreffen neuer Daten ausgelöst werden.
Weitere Informationen zur Verwendung von finden Sie unterÜberwachung AWS Glue. AWS Glue Jobs system Informationen zum Programmieren mithilfe der AWS Glue Jobs system -API finden Sie unter Auftrags-API.
Visuelle ETL-Komponenten
AWS Mit Glue können Sie ETL-Jobs über eine visuelle Leinwand erstellen, die Sie bearbeiten können.
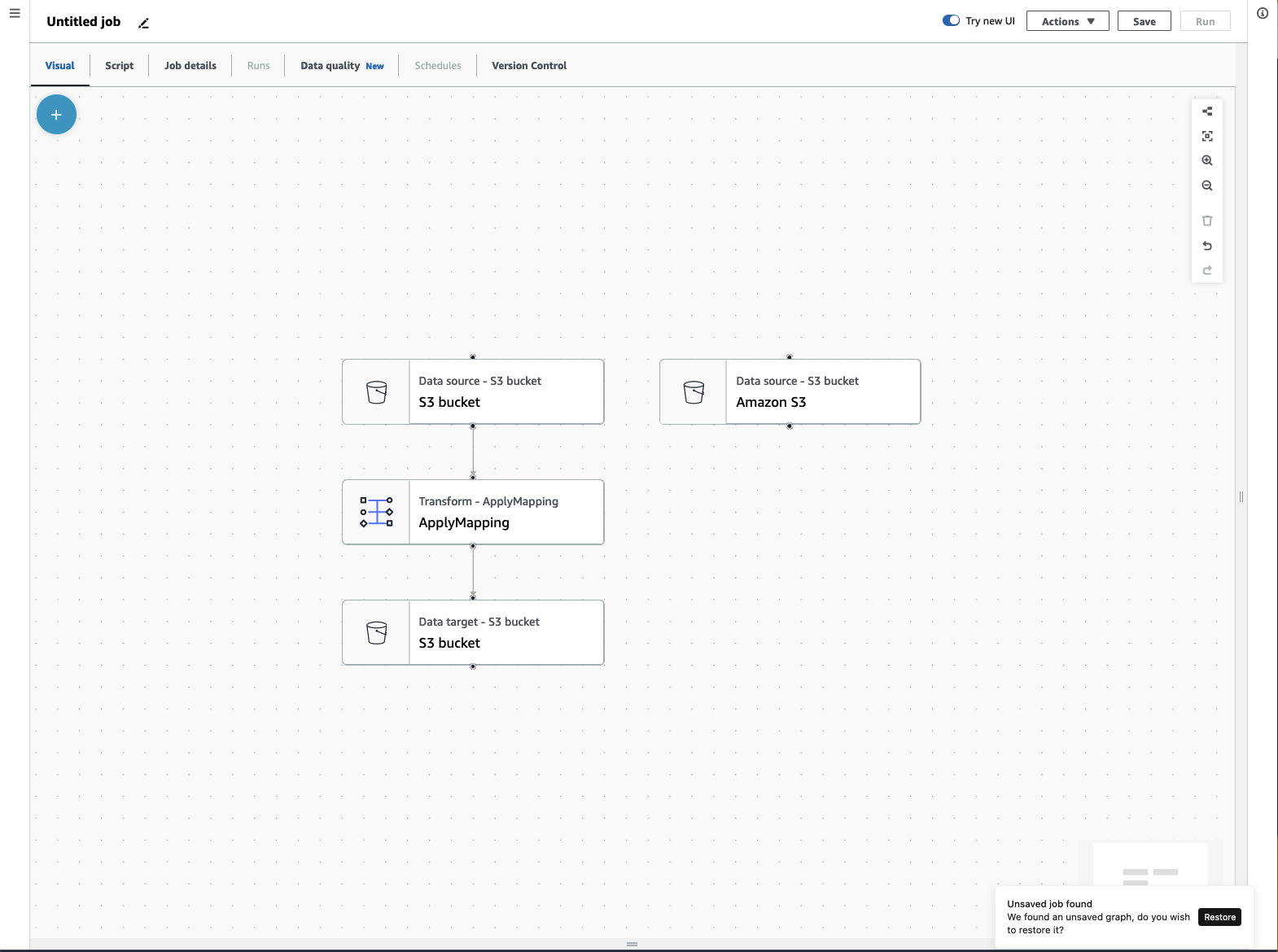
Menü ETL-Auftrag
Über die Menüoptionen oben im Zeichenbereich können Sie auf die verschiedenen Ansichten und Konfigurationsdetails zu Ihrem Auftrag zugreifen.
-
Visuell – Der Zeichenbereich des visuellen Auftrags-Editors. Hier können Sie Knoten hinzufügen, um einen Auftrag zu erstellen.
-
Script — Die Skriptdarstellung Ihres ETL-Jobs. AWS Glue generiert das Skript auf der Grundlage der visuellen Darstellung Ihres Jobs. Sie können Ihr Skript auch bearbeiten oder es herunterladen.
Anmerkung
Bei Auswahl der Skriptbearbeitung wird die Auftragserstellung dauerhaft in einen reinen Skriptmodus umgewandelt. Danach können Sie den visuellen Editor nicht mehr für die Bearbeitung des Auftrags verwenden. Bevor Sie das Skript auswählen, sollten Sie alle Auftragsquellen, Transformationen und Ziele hinzufügen und alle gewünschten Änderungen mit dem visuellen Editor vornehmen.
-
Auftragsdetails – Auf der Registerkarte Auftragsdetails können Sie Ihren Auftrag konfigurieren, indem Sie die Auftragseigenschaften festlegen. Es gibt grundlegende Eigenschaften wie Name und Beschreibung Ihres Jobs, IAM-Rolle, Jobtyp, AWS Glue-Version, Sprache, Workertyp, Anzahl der Worker, Job-Lesezeichen, Flex-Ausführung, Anzahl der Pensionierungen und Job-Timeout, und es gibt erweiterte Eigenschaften wie Verbindungen, Bibliotheken, Jobparameter und Tags.
-
Ausführungen – Nachdem Ihr Auftrag ausgeführt wurde, können Sie auf diese Registerkarte zugreifen, um Ihre vergangenen Auftragsausführungen anzuzeigen.
-
Datenqualität – Die Datenqualität bewertet und überwacht die Qualität Ihrer Datenbestände. Auf dieser Registerkarte erfahren Sie mehr darüber, wie Sie die Datenqualität verwenden und eine Datenqualitätstransformation zu Ihrem Auftrag hinzufügen können.
-
Zeitpläne – Von Ihnen geplante Aufträge werden auf dieser Registerkarte angezeigt. Wenn diesem Auftrag keine Zeitpläne angefügt sind, dann ist diese Registerkarte nicht zugänglich.
-
Versionskontrolle – Sie können Git mit Ihrem Auftrag verwenden, indem Sie Ihren Auftrag für ein Git-Repository konfigurieren.
Visuelle ETL-Bedienfelder
Wenn Sie im Zeichenbereich arbeiten, stehen Ihnen mehrere Bedienfelder zur Verfügung, die Sie bei der Konfiguration Ihrer Knoten unterstützen oder Ihnen dabei helfen, eine Vorschau Ihrer Daten anzuzeigen und das Ausgabeschema anzuzeigen.
-
Eigenschaften – Das Bedienfeld Eigenschaften wird angezeigt, wenn Sie einen Knoten in Ihrem Zeichenbereich auswählen.
-
Datenvorschau – Das Bedienfeld Datenvorschau bietet eine Vorschau der Datenausgabe, so dass Sie Entscheidungen treffen können, bevor Sie Ihren Auftrag ausführen und Ihre Ausgabe prüfen.
-
Ausgabeschema – Auf der Registerkarte Ausgabeschema können Sie das Schema Ihrer Transformationsknoten anzeigen und bearbeiten.
Größe der Bedienfelder ändern
Sie können die Größe des Eigenschaftenbereichs auf der rechten Seite des Bildschirms und des unteren Bereichs, der die Registerkarten Datenvorschau und Ausgabeschema enthält, ändern, indem Sie auf den Edge des Bereichs klicken und ihn nach links und rechts oder nach oben und unten ziehen.
-
Eigenschaftenfenster – Ändern Sie die Größe des Eigenschaftenfensters, indem Sie auf den Edge des Zeichenbereichs auf der rechten Seite des Bildschirms klicken und ihn ziehen. Ziehen Sie ihn dann nach links, um seine Breite zu vergrößern. Standardmäßig ist das Bedienfeld reduziert und wenn ein Knoten ausgewählt wird, wird das Eigenschaftenfeld in seiner Standardgröße geöffnet.
-
Datenvorschau und Bedienfeld Ausgabeschema – Ändern Sie die Größe des unteren Bedienfelds, indem Sie auf den unteren Edge des Zeichenbereichs am unteren Bildschirmrand klicken und ihn nach oben ziehen, um seine Höhe zu vergrößern. Standardmäßig ist das Bedienfeld reduziert und wenn ein Knoten ausgewählt wird, wird das untere Bedienfeld in seiner Standardgröße geöffnet.
Zeichenbereich für Aufträge
Sie können move/reorder Knoten direkt auf der Visual ETL-Arbeitsfläche hinzufügen, entfernen und entfernen. Betrachten Sie es als Ihren Workspace zur Erstellung eines voll funktionsfähigen ETL-Auftrags, der mit einer Datenquelle beginnt und mit einem Datenziel enden kann.
Wenn Sie mit Knoten auf dem Zeichenbereich arbeiten, steht Ihnen eine Symbolleiste zur Verfügung, mit der Sie hinein- und herauszoomen, Knoten entfernen, Verbindungen zwischen Knoten herstellen oder bearbeiten, die Auftragsflussausrichtung ändern und eine Aktion rückgängig machen oder wiederholen können.

Die schwebende Symbolleiste ist in der oberen rechten Ecke des Zeichenbereichs verankert und enthält mehrere Images, die Aktionen ausführen:
-
Layout-Symbol – Das erste Symbol in der Symbolleiste ist das Layout-Symbol. In der Standardeinstellung ist die Richtung der visuellen Aufträge von oben nach unten gerichtet. Es ändert die Richtung Ihres visuellen Auftrags, indem es die Knoten horizontal von links nach rechts anordnet. Durch erneutes Klicken auf das Layout-Symbol ändert sich die Richtung wieder von oben nach unten.
-
Symbol „Neu zentrieren“ – Das Symbol „Neu zentrieren“ ändert die Zeichenbereichsansicht, indem es sie zentriert. Sie können dies bei großen Aufträgen verwenden, um wieder in die Mittelstellung zu gelangen.
-
Symbol „Vergrößern“ – Das Symbol „Vergrößern“ vergrößert die Größe der Knoten im Zeichenbereich.
-
Symbol „Verkleinern“ – Das Symbol „Verkleinern“ verringert die Größe der Knoten im Zeichenbereich.
-
Papierkorbsymbol – Mit dem Papierkorbsymbol entfernen Sie einen Knoten aus dem visuellen Auftrag. Sie müssen zuerst einen Knoten auswählen.
-
Symbol „Rückgängig“ – Das Rückgängig-Symbol macht die letzte am visuellen Auftrag ausgeführte Aktion rückgängig.
-
Symbol „Wiederherstellen“ – Das Wiederherstellen-Symbol wiederholt die letzte Aktion, die für den visuellen Auftrag ausgeführt wurde.
Verwendung der Minikarte

Bedienfeld Ressourcen
Der Ressourcenbereich enthält alle für Sie verfügbaren Datenquellen, Transformationsaktionen und Verbindungen. Öffnen Sie den Ressourcenbereich im Zeichenbereich, indem Sie auf das „+“-Symbol klicken. Dadurch wird der Ressourcenbereich geöffnet.
Klicken Sie zum Schließen den Ressourcenbereich auf das X in der oberen rechten Ecke des Ressourcenbereichs. Dadurch wird das Bedienfeld ausgeblendet, bis Sie es erneut öffnen können.
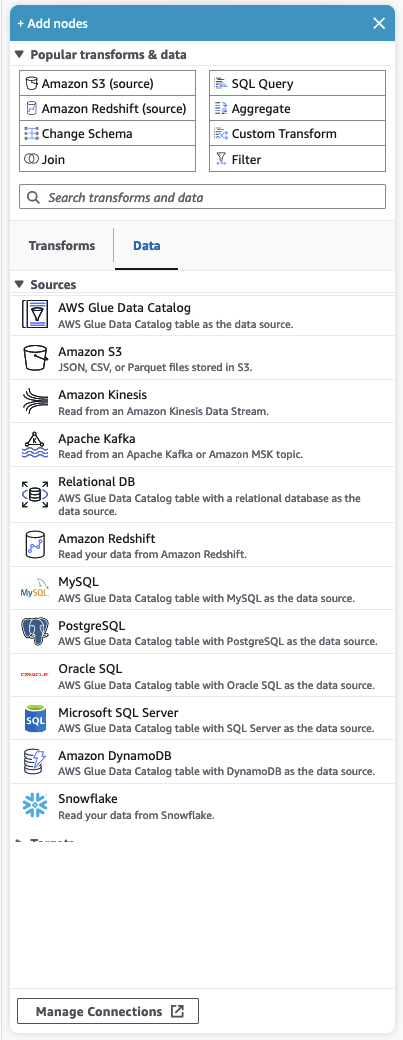
Beliebte Transformationen und Daten
Im oberen Bereich des Bedienfelds befindet sich eine Sammlung beliebter Transformationen und Daten. Diese Knoten werden häufig in AWS Glue verwendet. Wählen Sie eines aus, um es dem Zeichenbereich hinzuzufügen. Sie können die beliebten Transformationen und Daten auch ausblenden, indem Sie auf das Dreieck neben der Überschrift Beliebte Transformationen und Daten klicken.
Unter dem Abschnitt Beliebte Transformationen und Daten können Sie nach Transformationen und Datenquellenknoten suchen. Die Ergebnisse werden während der Eingabe angezeigt. Je mehr Buchstaben Sie zu Ihrer Suchanfrage hinzufügen, desto kleiner wird die Ergebnisliste. Die Suchergebnisse werden aus der and/or Beschreibung des Knotennamens übernommen. Wählen Sie den Knoten aus, um ihn Ihrem Zeichenbereich hinzuzufügen.
Transformationen und Daten
Es gibt zwei Registerkarten, auf denen die Knoten in Transformationen und Daten unterteilt sind.
Transformationen – Wenn Sie die Registerkarte Transformationen auswählen, können alle verfügbaren Transformationen ausgewählt werden. Wählen Sie eine Transformation aus, um sie dem Zeichenbereich hinzuzufügen. Sie können auch die Option Transformation hinzufügen unten in der Liste Transformationen auswählen, um eine neue Seite mit der Dokumentation zum Erstellen benutzerdefinierter visueller Transformationen zu öffnen. Wenn Sie die Schritte befolgen, können Sie eigene Transformationen erstellen. Ihre Transformationen werden dann in der Liste der verfügbaren Transformationen angezeigt.
Daten – Die Registerkarte Daten enthält alle Knoten für Quellen und Ziele. Sie können die Quellen und Ziele ausblenden, indem Sie auf das Dreieck neben der Überschrift Quellen oder Ziele klicken. Sie können die Quellen und Ziele wieder einblenden, indem Sie erneut auf das Dreieck klicken. Wählen Sie einen Quell- oder Zielknoten aus, um ihn dem Zeichenbereich hinzuzufügen. Sie können auch Verbindungen verwalten auswählen, um eine neue Verbindung hinzuzufügen. Dadurch wird die Seite Konnektoren in der Konsole geöffnet.
