Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Referenzarchitektur
Das folgende Diagramm zeigt den Arbeitsablauf, nachdem Sie die automatisierte Lösung dieses Handbuchs auf einen täglichen Betriebsbericht angewendet haben. Wenn neue Dateien in Amazon Simple Storage Service (Amazon S3) aufgenommen werden, können sie sofort nach der Verarbeitung in einem QuickSight Dashboard visualisiert werden.
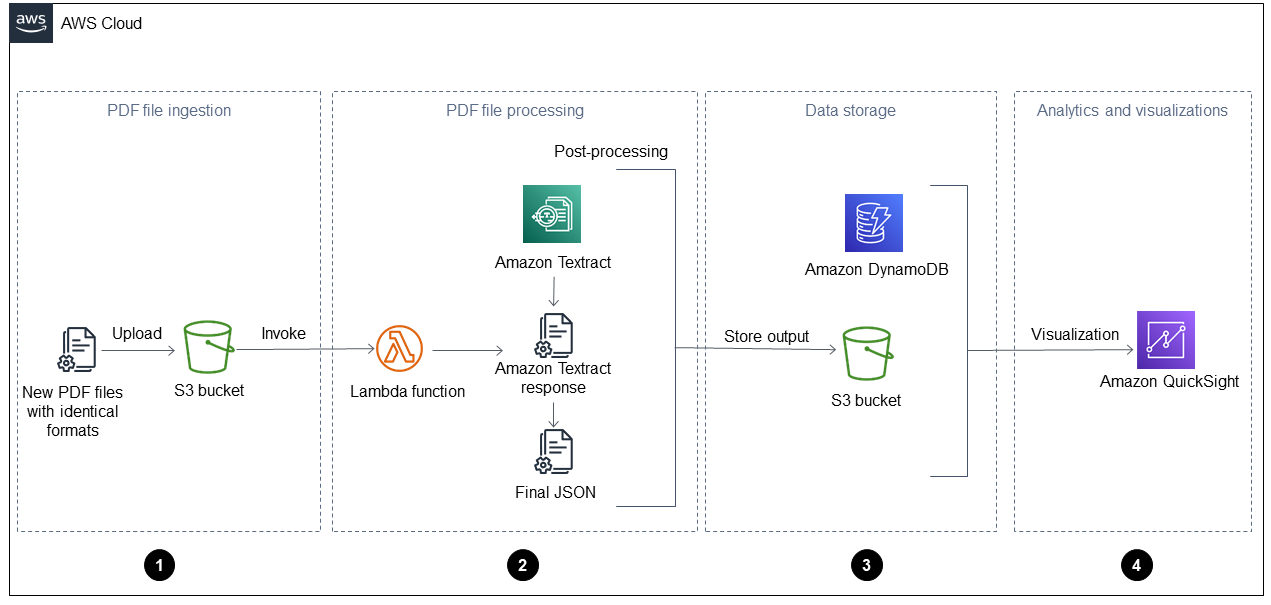
Das Diagramm zeigt die folgenden vier Phasen:
-
Aufnahme von PDF-Dateien — Ihre Anwendung nimmt automatisch neue PDF-Dateien mit einem identischen Format (z. B. einen täglichen Betriebsbericht) in einen Amazon Simple Storage Service (Amazon S3) -Bucket auf. Amazon S3 initiiert ein
ObjectCreatedEreignis, wenn dem Bucket neue PDF-Dateien hinzugefügt werden, und dadurch wird eine AWS Lambda Funktion aufgerufen. Weitere Informationen dazu finden Sie unter Verwenden eines Amazon S3 S3-Triggers zum Aufrufen einer Lambda-Funktion in der Amazon S3 S3-Dokumentation. -
Verarbeitung von PDF-Dateien — Die Lambda-Funktion sendet eine PDF-Datei an Amazon Textract, das den Inhalt extrahiert. Ein Nachbearbeitungsskript führt die Amazon Textract Textract-Antwort aus und analysiert sie und verwendet eine vordefinierte Vorlage für diese Art von PDF-Datei. Diese Vorlage enthält die richtigen Attribute und hilft dabei, alle Schlüssel-Wert-Paare, Tabellen und anderen Rohtext korrekt zu extrahieren. Weitere Informationen dazu finden Sie unter dem Muster Automatisches Extrahieren von Inhalten aus PDF-Dateien mithilfe von Amazon Textract auf der AWS Prescriptive Guidance-Website.
-
Datenspeicherung — Die extrahierten und korrigierten Daten werden in einer Amazon DynamoDB-Tabelle gespeichert, zusätzlich zu einer JSON-Datei für jede PDF-Datei. Die JSON-Dateien werden in einem S3-Bucket gespeichert, der von nachgelagerten Verarbeitungs- und Analysediensten wie Amazon Athena oder Amazon SageMaker AI verwendet werden kann. QuickSight
-
Analysen und Visualisierungen — QuickSight analysiert die Daten und erstellt Visualisierungen, mit deren Hilfe Erkenntnisse für alle verarbeiteten PDF-Dateien gewonnen werden können. Nachdem die Dashboards erstellt wurden QuickSight, können Sie sie mit Ihren Endbenutzern und Geschäftsteams teilen.
Überlegungen
Die Lösung dieses Handbuchs eignet sich für die Verarbeitung von PDF-Dateien mit identischem Format und einheitlichem Layout von Formularen und Tabellen. Sie müssen jedoch eine Vorlage definieren und diese im Voraus bearbeiten, um den Prozess vollständig zu automatisieren und die extrahierten Daten für die Analyse verfügbar zu machen. Diese Vorlage wird dann bei der Verarbeitung mit der Lambda-Funktion verwendet.
Diese Lösung kann zwar gleichzeitig auf verschiedene PDF-Dateitypen angewendet werden, Sie müssen jedoch separate Vorlagen für jeden PDF-Dateityp erstellen und definieren und diese an einem zugänglichen Ort speichern (z. B. Amazon S3). Wir empfehlen, dass Sie für jeden PDF-Dateityp eine eindeutige Kennung verwenden, z. B. einen PDF-Dateinamen oder verschiedene Ordner in Ihrem S3-Bucket. Die Lambda-Funktion kann dann bei der Verarbeitung des PDF-Dateityps die entsprechende Vorlage aufrufen.
