Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Generieren Sie mit Amazon Personalize personalisierte und neu eingestufte Empfehlungen
Mason Cahill, Matthew Chasse und Tayo Olajide, Amazon Web Services
Übersicht
Dieses Muster zeigt Ihnen, wie Sie Amazon Personalize verwenden, um personalisierte Empfehlungen — einschließlich neu eingestufter Empfehlungen — für Ihre Benutzer zu generieren, die auf der Erfassung von Benutzerinteraktionsdaten in Echtzeit von diesen Benutzern basieren. Das in diesem Muster verwendete Beispielszenario basiert auf einer Website zur Adoption von Haustieren, die anhand ihrer Interaktionen Empfehlungen für ihre Benutzer generiert (z. B. welche Haustiere ein Benutzer besucht). Anhand des Beispielszenarios lernen Sie, Amazon Kinesis Data Streams zur Erfassung von Interaktionsdaten, AWS Lambda zur Generierung von Empfehlungen und zur Neurangierung der Empfehlungen und Amazon Data Firehose zum Speichern der Daten in einem Amazon Simple Storage Service (Amazon S3) -Bucket zu verwenden. Sie lernen auch, AWS Step Functions zu verwenden, um eine Zustandsmaschine zu erstellen, die die Lösungsversion (d. h. ein trainiertes Modell) verwaltet, die Ihre Empfehlungen generiert.
Voraussetzungen und Einschränkungen
Voraussetzungen
Ein aktives AWS-Konto
mit einem Bootstrapping des AWS Cloud Development Kit (AWS CDK) AWS-Befehlszeilenschnittstelle (AWS CLI) mit konfigurierten Anmeldeinformationen
Produktversionen
Python 3.9
AWS CDK 2.23.0 oder höher
AWS CLI 2.7.27 oder höher
Architektur
Technologie-Stack
Amazon Data Firehose
Amazon Kinesis Data Streams
Amazon Personalize
Amazon Simple Storage Service (Amazon-S3)
AWS-Cloud-Entwicklungskit (AWS CDK)
AWS-Befehlszeilenschnittstelle (AWS Command Line Interface, AWS CLI)
AWS Lambda
AWS Step Functions
Zielarchitektur
Das folgende Diagramm zeigt eine Pipeline für die Aufnahme von Echtzeitdaten in Amazon Personalize. Die Pipeline verwendet diese Daten dann, um personalisierte und neu eingestufte Empfehlungen für Benutzer zu generieren.
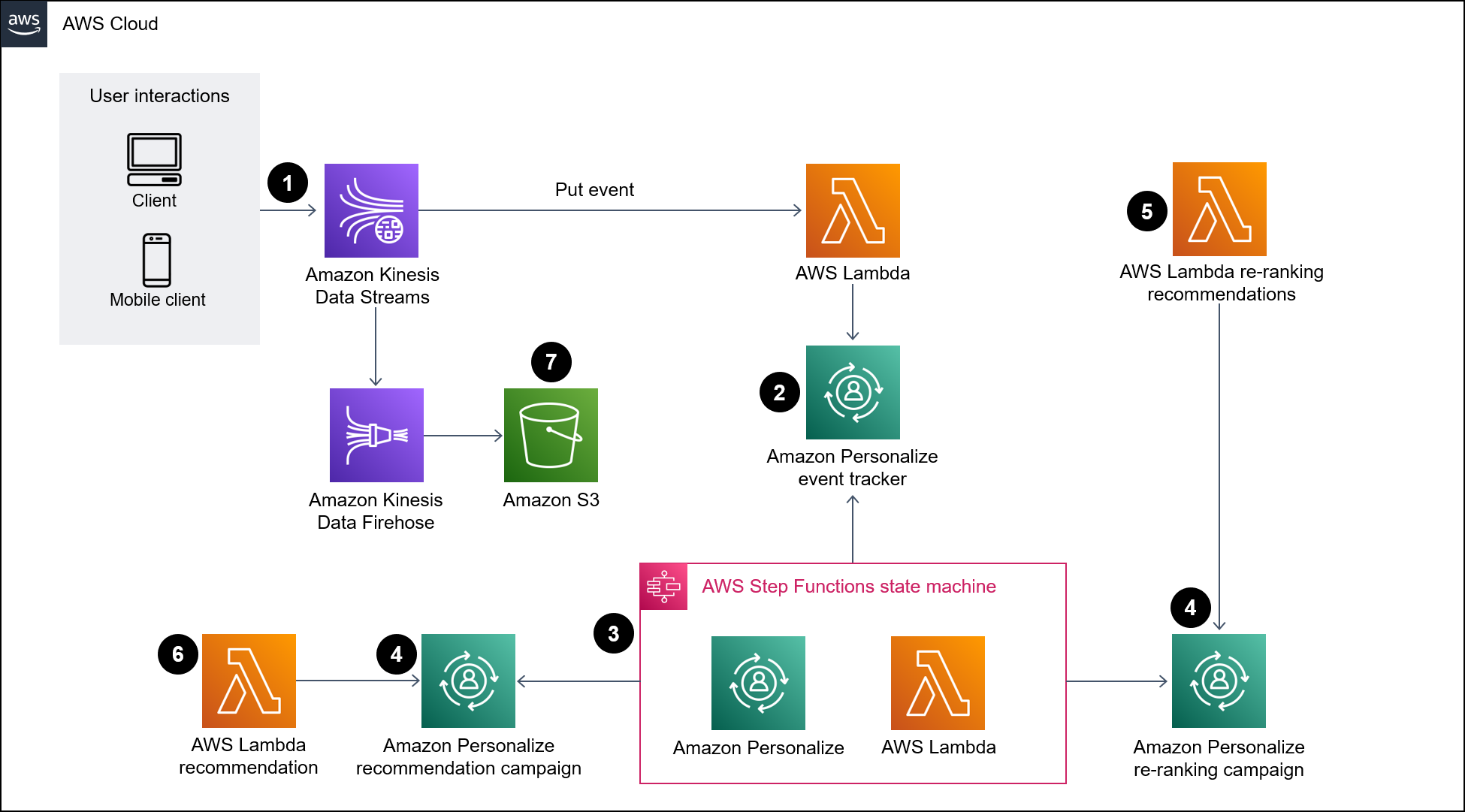
Das Diagramm zeigt den folgenden Workflow:
Kinesis Data Streams nimmt Benutzerdaten in Echtzeit auf (z. B. Ereignisse wie besuchte Haustiere) zur Verarbeitung durch Lambda und Firehose.
Eine Lambda-Funktion verarbeitet die Datensätze aus Kinesis Data Streams und führt einen API-Aufruf durch, um die Benutzerinteraktion im Datensatz einem Event-Tracker in Amazon Personalize hinzuzufügen.
Eine zeitbasierte Regel ruft eine Step Functions Functions-Zustandsmaschine auf und generiert mithilfe der Ereignisse aus dem Event-Tracker in Amazon Personalize neue Lösungsversionen für die Empfehlungs- und Re-Ranking-Modelle.
Amazon Personalize Personalize-Kampagnen werden von der State Machine aktualisiert, um die neue Lösungsversion zu verwenden.
Lambda ordnet die Liste der empfohlenen Artikel neu an, indem es die Amazon Personalize-Kampagne zur Neurangierung aufruft.
Lambda ruft die Liste der empfohlenen Artikel ab, indem es die Amazon Personalize Personalize-Empfehlungskampagne aufruft.
Firehose speichert die Ereignisse in einem S3-Bucket, wo sie als historische Daten abgerufen werden können.
Tools
AWS-Tools
Das AWS Cloud Development Kit (AWS CDK) ist ein Softwareentwicklungs-Framework, das Sie bei der Definition und Bereitstellung der AWS-Cloud-Infrastruktur im Code unterstützt.
AWS Command Line Interface (AWS CLI) ist ein Open-Source-Tool, mit dem Sie über Befehle in Ihrer Befehlszeilen-Shell mit AWS-Services interagieren können.
Amazon Data Firehose unterstützt Sie bei der Bereitstellung von Echtzeit-Streaming-Daten
an andere AWS-Services, benutzerdefinierte HTTP-Endpunkte und HTTP-Endpunkte, die von unterstützten Drittanbietern betrieben werden. Amazon Kinesis Data Streams hilft Ihnen dabei, große Datenströme in Echtzeit zu sammeln und zu verarbeiten.
AWS Lambda ist ein Rechenservice, mit dem Sie Code ausführen können, ohne Server bereitstellen oder verwalten zu müssen. Er führt Ihren Code nur bei Bedarf aus und skaliert automatisch, sodass Sie nur für die tatsächlich genutzte Rechenzeit zahlen.
Amazon Personalize ist ein vollständig verwalteter Service für maschinelles Lernen (ML), mit dem Sie auf der Grundlage Ihrer Daten Artikelempfehlungen für Ihre Benutzer generieren können.
AWS Step Functions ist ein serverloser Orchestrierungsservice, mit dem Sie Lambda-Funktionen und andere AWS-Services kombinieren können, um geschäftskritische Anwendungen zu erstellen.
Andere Tools
Code
Der Code für dieses Muster ist im GitHub Animal Recommender-Repository
Anmerkung
Die Versionen der Amazon Personalize Personalize-Lösung, der Event Tracker und die Kampagnen werden durch benutzerdefinierte Ressourcen (innerhalb der Infrastruktur) unterstützt, die die systemeigenen CloudFormation Ressourcen erweitern.
Epen
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
Erstellen Sie eine isolierte Python-Umgebung. | Mac/Linux-Setup
Windows-Setup Um manuell eine virtuelle Umgebung zu erstellen, führen Sie den | DevOps Ingenieur |
Synthetisieren Sie die CloudFormation Vorlage. |
Anmerkung
| DevOps Ingenieur |
Stellen Sie Ressourcen bereit und schaffen Sie eine Infrastruktur. | Führen Sie den Dieser Befehl installiert die erforderlichen Python-Abhängigkeiten. Ein Python-Skript erstellt einen S3-Bucket und einen AWS Key Management Service (AWS KMS) -Schlüssel und fügt dann die Startdaten für die ersten Modellerstellungen hinzu. Schließlich wird das Skript ausgeführt, AnmerkungDas anfängliche Modelltraining findet während der Stack-Erstellung statt. Es kann bis zu zwei Stunden dauern, bis der Stack fertig erstellt ist. | DevOps Ingenieur |
Zugehörige Ressourcen
Zusätzliche Informationen
Beispiele für Payloads und Antworten
Empfehlung Lambda-Funktion
Um Empfehlungen abzurufen, senden Sie eine Anfrage an die Lambda-Empfehlungsfunktion mit einer Nutzlast im folgenden Format:
{ "userId": "3578196281679609099", "limit": 6 }
Die folgende Beispielantwort enthält eine Liste von Tiergruppen:
[{"id": "1-domestic short hair-1-1"}, {"id": "1-domestic short hair-3-3"}, {"id": "1-domestic short hair-3-2"}, {"id": "1-domestic short hair-1-2"}, {"id": "1-domestic short hair-3-1"}, {"id": "2-beagle-3-3"},
Wenn Sie das userId Feld weglassen, gibt die Funktion allgemeine Empfehlungen zurück.
Lambda-Funktion neu einordnen
Um Re-Ranking zu verwenden, senden Sie eine Anfrage an die Lambda-Funktion zur Neurangierung. Die Payload enthält alle Elemente, userId die neu eingestuft werden IDs sollen, sowie deren Metadaten. In den folgenden Beispieldaten werden die Oxford Pets-Klassen für animal_species_id (1=Katze, 2=Hund) und die Ganzzahlen 1-5 für und verwendet: animal_age_id animal_size_id
{ "userId":"12345", "itemMetadataList":[ { "itemId":"1", "animalMetadata":{ "animal_species_id":"2", "animal_primary_breed_id":"Saint_Bernard", "animal_size_id":"3", "animal_age_id":"2" } }, { "itemId":"2", "animalMetadata":{ "animal_species_id":"1", "animal_primary_breed_id":"Egyptian_Mau", "animal_size_id":"1", "animal_age_id":"1" } }, { "itemId":"3", "animalMetadata":{ "animal_species_id":"2", "animal_primary_breed_id":"Saint_Bernard", "animal_size_id":"3", "animal_age_id":"2" } } ] }
Die Lambda-Funktion ordnet diese Artikel neu ein und gibt dann eine geordnete Liste zurück, die den Artikel IDs und die direkte Antwort von Amazon Personalize enthält. Dies ist eine Rangliste der Tiergruppen, zu denen die Artikel gehören, und ihrer Punktzahl. Amazon Personalize verwendet Rezepte für Benutzerpersonalisierung und personalisiertes Ranking, um für jeden Artikel in den Empfehlungen eine Punktzahl anzugeben. Diese Werte stellen die relative Sicherheit dar, die Amazon Personalize darüber hat, welchen Artikel der Benutzer als Nächstes auswählen wird. Höhere Punktzahlen bedeuten eine größere Gewissheit.
{ "ranking":[ "1", "3", "2" ], "personalizeResponse":{ "ResponseMetadata":{ "RequestId":"a2ec0417-9dcd-4986-8341-a3b3d26cd694", "HTTPStatusCode":200, "HTTPHeaders":{ "date":"Thu, 16 Jun 2022 22:23:33 GMT", "content-type":"application/json", "content-length":"243", "connection":"keep-alive", "x-amzn-requestid":"a2ec0417-9dcd-4986-8341-a3b3d26cd694" }, "RetryAttempts":0 }, "personalizedRanking":[ { "itemId":"2-Saint_Bernard-3-2", "score":0.8947961 }, { "itemId":"1-Siamese-1-1", "score":0.105204 } ], "recommendationId":"RID-d97c7a87-bd4e-47b5-a89b-ac1d19386aec" } }
Amazon Kinesis Kinesis-Nutzlast
Die an Amazon Kinesis zu sendende Nutzlast hat das folgende Format:
{ "Partitionkey": "randomstring", "Data": { "userId": "12345", "sessionId": "sessionId4545454", "eventType": "DetailView", "animalMetadata": { "animal_species_id": "1", "animal_primary_breed_id": "Russian_Blue", "animal_size_id": "1", "animal_age_id": "2" }, "animal_id": "98765" } }
Anmerkung
Das userId Feld für einen nicht authentifizierten Benutzer wurde entfernt.
