Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Definieren Sie eine Pipeline
Um Ihre Workflows mit Amazon SageMaker Pipelines zu orchestrieren, müssen Sie einen gerichteten azyklischen Graphen (DAG) in Form einer JSON-Pipeline-Definition generieren. Die DAG spezifiziert die verschiedenen Schritte Ihres ML-Prozesses, wie Datenvorverarbeitung, Modelltraining, Modellevaluierung und Modellbereitstellung, sowie die Abhängigkeiten und den Datenfluss zwischen diesen Schritten. Das folgende Thema zeigt Ihnen, wie Sie eine Pipeline-Definition generieren.
Sie können Ihre JSON-Pipeline-Definition entweder mit dem SageMaker Python-SDK oder der visuellen drag-and-drop Pipeline Designer-Funktion in Amazon SageMaker Studio generieren. Das folgende Bild zeigt die Pipeline-DAG, die Sie in diesem Tutorial erstellen:
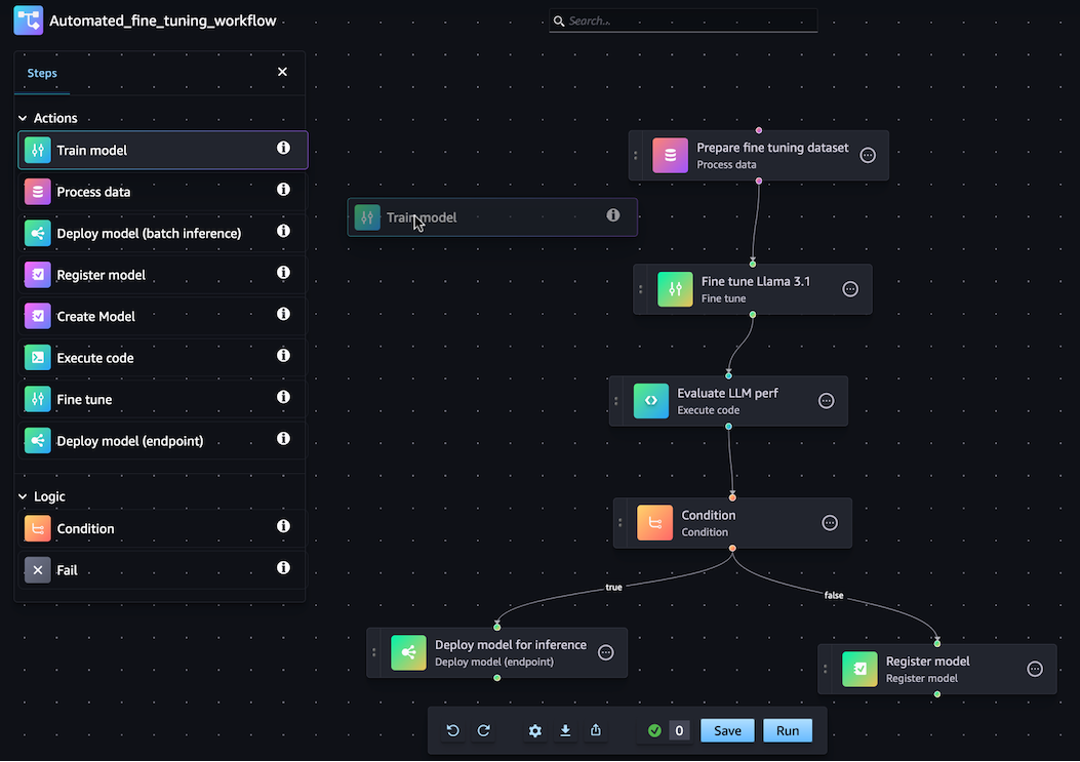
Die Pipeline, die Sie in den folgenden Abschnitten definieren, löst ein Regressionsproblem, bei dem das Alter einer Abalone anhand ihrer physikalischen Maße bestimmt wird. Ein lauffähiges Jupyter-Notizbuch, das den Inhalt dieses Tutorials enthält, finden Sie unter Orchestrating Jobs
Themen
Die folgende exemplarische Vorgehensweise führt Sie durch die Schritte zum Erstellen einer Barebones-Pipeline mit dem drag-and-drop Pipeline Designer. Wenn Sie Ihre Pipeline-Bearbeitungssitzung im Visual Designer jederzeit unterbrechen oder beenden müssen, klicken Sie auf die Option Exportieren. Auf diese Weise können Sie die aktuelle Definition Ihrer Pipeline in Ihre lokale Umgebung herunterladen. Später, wenn Sie den Pipeline-Bearbeitungsprozess fortsetzen möchten, können Sie dieselbe JSON-Definitionsdatei in den Visual Designer importieren.
Erstellen Sie einen Verarbeitungsschritt
Gehen Sie wie folgt vor, um einen Auftragsschritt zur Datenverarbeitung zu erstellen:
-
Öffnen Sie die Studio-Konsole, indem Sie den Anweisungen unter folgenStarten Sie Amazon SageMaker Studio.
-
Wählen Sie im linken Navigationsbereich Pipelines aus.
-
Wählen Sie Erstellen aus.
-
Wählen Sie Leer.
-
Wählen Sie in der linken Seitenleiste die Option Daten verarbeiten und ziehen Sie sie auf die Leinwand.
-
Wählen Sie auf der Arbeitsfläche den Schritt „Daten verarbeiten“ aus, den Sie hinzugefügt haben.
-
Um einen Eingabedatensatz hinzuzufügen, wählen Sie in der rechten Seitenleiste unter Daten (Eingabe) die Option Hinzufügen und wählen Sie einen Datensatz aus.
-
Um einen Speicherort für Ausgabe-Datasets hinzuzufügen, wählen Sie in der rechten Seitenleiste unter Daten (Ausgabe) die Option Hinzufügen und navigieren Sie zum Ziel.
-
Füllen Sie die verbleibenden Felder in der rechten Seitenleiste aus. Informationen zu den Feldern in diesen Tabs finden Sie unter sagemaker.workflow.steps. ProcessingStep
.
Erstellen Sie einen Trainingsschritt
Gehen Sie wie folgt vor, um einen Modell-Trainingsschritt einzurichten:
-
Wählen Sie in der linken Seitenleiste die Option Modell trainieren und ziehen Sie es auf die Leinwand.
-
Wählen Sie auf der Leinwand den Schritt Train Model aus, den Sie hinzugefügt haben.
-
Um einen Eingabedatensatz hinzuzufügen, wählen Sie in der rechten Seitenleiste unter Daten (Eingabe) die Option Hinzufügen und wählen Sie einen Datensatz aus.
-
Um einen Speicherort für Ihre Modellartefakte auszuwählen, geben Sie eine Amazon S3 S3-URI in das Feld Standort (S3-URI) ein oder wählen Sie S3 durchsuchen, um zum Zielort zu navigieren.
-
Füllen Sie die verbleibenden Felder in der rechten Seitenleiste aus. Informationen zu den Feldern in diesen Tabs finden Sie unter sagemaker.workflow.steps. TrainingStep
. -
Klicken und ziehen Sie den Cursor aus dem Schritt Prozessdaten, den Sie im vorherigen Abschnitt hinzugefügt haben, in den Schritt Modell trainieren, um eine Kante zu erzeugen, die die beiden Schritte verbindet.
Erstellen Sie ein Modellpaket mit dem Schritt Modell registrieren
Gehen Sie wie folgt vor, um ein Modellpaket mit einem Schritt zur Modellregistrierung zu erstellen:
-
Wählen Sie in der linken Seitenleiste Modell registrieren und ziehen Sie es auf die Arbeitsfläche.
-
Wählen Sie auf der Arbeitsfläche den Schritt Modell registrieren aus, den Sie hinzugefügt haben.
-
Um ein Modell für die Registrierung auszuwählen, wählen Sie unter Modell (Eingabe) die Option Hinzufügen aus.
-
Wählen Sie Modellgruppe erstellen, um Ihr Modell zu einer neuen Modellgruppe hinzuzufügen.
-
Füllen Sie die verbleibenden Felder in der rechten Seitenleiste aus. Informationen zu den Feldern in diesen Tabs finden Sie unter sagemaker.workflow.step_collections. RegisterModel
. -
Klicken und ziehen Sie den Cursor aus dem Schritt Modell trainieren, den Sie im vorherigen Abschnitt hinzugefügt haben, in den Schritt Modell registrieren, um eine Kante zu erzeugen, die die beiden Schritte verbindet.
Stellen Sie das Modell mit dem Schritt Modell bereitstellen (Endpunkt) auf einem Endpunkt bereit
Gehen Sie wie folgt vor, um Ihr Modell mithilfe eines Schritts zur Modellbereitstellung bereitzustellen:
-
Wählen Sie in der linken Seitenleiste Modell bereitstellen (Endpunkt) aus und ziehen Sie es auf die Arbeitsfläche.
-
Wählen Sie auf der Arbeitsfläche den Schritt Modell bereitstellen (Endpunkt) aus, den Sie hinzugefügt haben.
-
Um ein Modell für die Bereitstellung auszuwählen, wählen Sie unter Modell (Eingabe) die Option Hinzufügen aus.
-
Wählen Sie das Optionsfeld Endpunkt erstellen, um einen neuen Endpunkt zu erstellen.
-
Geben Sie einen Namen und eine Beschreibung für Ihren Endpunkt ein.
-
Klicken und ziehen Sie den Cursor vom Schritt Modell registrieren, den Sie im vorherigen Abschnitt hinzugefügt haben, zum Schritt Modell bereitstellen (Endpunkt), um eine Kante zu erstellen, die die beiden Schritte verbindet.
-
Füllen Sie die verbleibenden Felder in der rechten Seitenleiste aus.
Definieren Sie die Pipeline-Parameter
Sie können eine Reihe von Pipeline-Parametern konfigurieren, deren Werte für jede Ausführung aktualisiert werden können. Um die Pipeline-Parameter zu definieren und die Standardwerte festzulegen, klicken Sie auf das Zahnradsymbol unten im Visual Designer.
Pipeline speichern
Nachdem Sie alle erforderlichen Informationen eingegeben haben, um Ihre Pipeline zu erstellen, klicken Sie unten im visuellen Designer auf Speichern. Dadurch wird Ihre Pipeline zur Laufzeit auf mögliche Fehler überprüft und Sie werden benachrichtigt. Der Speichervorgang ist erst erfolgreich, wenn Sie alle Fehler behoben haben, die durch die automatischen Validierungsprüfungen gekennzeichnet wurden. Wenn Sie die Bearbeitung zu einem späteren Zeitpunkt fortsetzen möchten, können Sie Ihre Pipeline in Bearbeitung als JSON-Definition in Ihrer lokalen Umgebung speichern. Sie können Ihre Pipeline als JSON-Definitionsdatei exportieren, indem Sie unten im Visual Designer auf die Schaltfläche Exportieren klicken. Um später mit der Aktualisierung Ihrer Pipeline fortzufahren, laden Sie diese JSON-Definitionsdatei hoch, indem Sie auf die Schaltfläche Importieren klicken.
Voraussetzungen
Gehen Sie wie folgt vor, um das folgende Tutorial auszuführen:
-
Richten Sie Ihre Notebook-Instance wie unter Notebook-Instance erstellen beschrieben ein. Dadurch erhält Ihre Rolle Lese- und Schreibberechtigungen für Amazon S3 sowie zum Erstellen von Schulungs-, Batch-Transform- und Verarbeitungsaufträgen in SageMaker KI.
-
Erteilen Sie Ihrem Notebook Berechtigungen zum Abrufen und Weitergeben seiner eigenen Rolle, wie unter Richtlinie zu Rollenberechtigungen ändern beschrieben. Fügen Sie den folgenden JSON-Snippet hinzu, um diese Richtlinie an Ihre Rolle anzuhängen. Ersetzen Sie
<your-role-arn>durch den ARN, der zum Erstellen Ihrer Notebook-Instance verwendet wurde. -
Vertrauen Sie dem SageMaker AI-Serviceprinzipal, indem Sie die Schritte unter Ändern einer Rollenvertrauensrichtlinie befolgen. Fügen Sie das folgende Anweisungsfragment zur Vertrauensstellung Ihrer Rolle hinzu:
{ "Sid": "", "Effect": "Allow", "Principal": { "Service": "sagemaker.amazonaws.com" }, "Action": "sts:AssumeRole" }
So richten Sie Ihre Umgebung ein
Erstellen Sie eine neue SageMaker AI-Sitzung mit dem folgenden Codeblock. Dadurch wird der Rollen-ARN für die Sitzung zurückgegeben. Bei diesem Rollen-ARN sollte es sich um den ARN für die Ausführungsrolle handeln, den Sie als Voraussetzung eingerichtet haben.
import boto3 import sagemaker import sagemaker.session from sagemaker.workflow.pipeline_context import PipelineSession region = boto3.Session().region_name sagemaker_session = sagemaker.session.Session() role = sagemaker.get_execution_role() default_bucket = sagemaker_session.default_bucket() pipeline_session = PipelineSession() model_package_group_name = f"AbaloneModelPackageGroupName"
Erstellen Sie eine Pipeline
Wichtig
Benutzerdefinierte IAM-Richtlinien, die es Amazon SageMaker Studio oder Amazon SageMaker Studio Classic ermöglichen, SageMaker Amazon-Ressourcen zu erstellen, müssen auch Berechtigungen zum Hinzufügen von Tags zu diesen Ressourcen gewähren. Die Berechtigung zum Hinzufügen von Tags zu Ressourcen ist erforderlich, da Studio und Studio Classic automatisch alle von ihnen erstellten Ressourcen taggen. Wenn eine IAM-Richtlinie Studio und Studio Classic das Erstellen von Ressourcen, aber kein Tagging erlaubt, können "AccessDenied" Fehler auftreten, wenn versucht wird, Ressourcen zu erstellen. Weitere Informationen finden Sie unter Stellen Sie Berechtigungen für das Taggen von KI-Ressourcen SageMaker bereit.
AWS verwaltete Richtlinien für Amazon SageMaker AIdie Berechtigungen zum Erstellen von SageMaker Ressourcen gewähren, beinhalten bereits Berechtigungen zum Hinzufügen von Tags beim Erstellen dieser Ressourcen.
Führen Sie die folgenden Schritte von Ihrer SageMaker KI-Notebook-Instanz aus, um eine Pipeline zu erstellen, die Schritte umfasst für:
-
Vorverarbeitung
-
Training
-
Auswertung
-
bedingte Bewertung
-
Modellregistrierung
Anmerkung
Sie können die Join-FunktionExecutionVariableswird zur Laufzeit aufgelöst. ExecutionVariables.PIPELINE_EXECUTION_ID wird beispielsweise in die ID der aktuellen Ausführung aufgelöst, die als eindeutige Kennung für verschiedene Läufe verwendet werden kann.
Schritt 1: Laden Sie den Datensatz herunter
Dieses Notebook verwendet den UCI Machine Learning Abalone Datensatz. Der Datensatz enthält folgende Merkmale:
-
length– Die längste Schalenmessung der Abalone. -
diameter– Der Durchmesser der Abalone senkrecht zu ihrer Länge. -
height– Die Höhe der Abalone mit Fleisch in der Schale. -
whole_weight– Das Gewicht der ganzen Abalone. -
shucked_weight– Das Gewicht des aus der Abalone entnommenen Fleisches. -
viscera_weight– Das Gewicht der Eingeweide der Abalone nach der Blutung. -
shell_weight– Das Gewicht der Abalone-Schale nach dem Entnehmen und Trocknen des Fleisches. -
sex– Das Geschlecht der Abalone. Eines von „M“, „F“ oder „I“, wobei „I“ für eine Säuglingsabalone steht. -
rings– Die Anzahl der Ringe in der Abalone-Schale.
Die Anzahl der Ringe in der Abalone-Schale ist anhand der Formel age=rings + 1.5 eine gute Näherung für ihr Alter. Das Ermitteln dieser Nummer ist jedoch eine zeitaufwändige Aufgabe. Sie müssen die Schale durch den Kegel schneiden, den Abschnitt färben und die Anzahl der Ringe durch ein Mikroskop zählen. Die anderen physikalischen Messungen sind jedoch einfacher zu ermitteln. Dieses Notebook verwendet den Datensatz, um anhand der anderen physikalischen Messungen ein Vorhersagemodell der variablen Ringe zu erstellen.
Zum Herunterladen des Datensatzes
-
Laden Sie den Datensatz in den standardmäßigen Amazon-S3-Bucket Ihres Kontos herunter.
!mkdir -p data local_path = "data/abalone-dataset.csv" s3 = boto3.resource("s3") s3.Bucket(f"sagemaker-servicecatalog-seedcode-{region}").download_file( "dataset/abalone-dataset.csv", local_path ) base_uri = f"s3://{default_bucket}/abalone" input_data_uri = sagemaker.s3.S3Uploader.upload( local_path=local_path, desired_s3_uri=base_uri, ) print(input_data_uri) -
Laden Sie nach der Erstellung Ihres Modells einen zweiten Datensatz für die Batch-Transformation herunter.
local_path = "data/abalone-dataset-batch.csv" s3 = boto3.resource("s3") s3.Bucket(f"sagemaker-servicecatalog-seedcode-{region}").download_file( "dataset/abalone-dataset-batch", local_path ) base_uri = f"s3://{default_bucket}/abalone" batch_data_uri = sagemaker.s3.S3Uploader.upload( local_path=local_path, desired_s3_uri=base_uri, ) print(batch_data_uri)
Schritt 2: Definieren Sie die Pipeline-Parameter
Dieser Codeblock definiert die folgenden Parameter für Ihre Pipeline:
-
processing_instance_count– Die Anzahl der Instances des Verarbeitungsjobs. -
input_data– Der Amazon S3-Speicherort der Eingabedaten.. -
batch_data– Der Amazon-S3-Speicherort der Eingabedaten für die Batch-Transformation. -
model_approval_status– Der Genehmigungsstatus, mit dem das trainierte Modell für CI/CD registriert werden soll. Weitere Informationen finden Sie unter MLOps Automatisierung mit SageMaker Projekten.
from sagemaker.workflow.parameters import ( ParameterInteger, ParameterString, ) processing_instance_count = ParameterInteger( name="ProcessingInstanceCount", default_value=1 ) model_approval_status = ParameterString( name="ModelApprovalStatus", default_value="PendingManualApproval" ) input_data = ParameterString( name="InputData", default_value=input_data_uri, ) batch_data = ParameterString( name="BatchData", default_value=batch_data_uri, )
Schritt 3: Definieren Sie einen Verarbeitungsschritt für das Feature-Engineering
In diesem Abschnitt wird erläutert, wie Sie einen Verarbeitungsschritt erstellen, um die Daten aus dem Datensatz für das Training vorzubereiten.
Um einen Verarbeitungsschritt zu erstellen
-
Erstellen Sie ein Verzeichnis für das Verarbeitungsskript.
!mkdir -p abalone -
Erstellen Sie im Verzeichnis
/abaloneeine Datei namenspreprocessing.pymit folgendem Inhalt. Dieses Vorverarbeitungsskript wird an den Verarbeitungsschritt zur Ausführung der Eingabedaten übergeben. Der Trainingsschritt verwendet dann die vorverarbeiteten Trainingsfunktionen und Labels, um ein Modell zu trainieren. Im Bewertungsschritt werden das trainierte Modell und die vorverarbeiteten Testmerkmale und Bezeichnungen verwendet, um das Modell zu evaluieren. Das Skript verwendetscikit-learnfür die folgenden Aufgaben:-
Füllen Sie fehlende
sexkategoriale Daten aus und codieren Sie sie so, dass sie für das Training geeignet sind. -
Skalieren und normalisieren Sie alle numerischen Felder außer
ringsundsex. -
Teilen Sie die Daten in Trainings-, Test- und Validierungsdatensätze auf.
%%writefile abalone/preprocessing.py import argparse import os import requests import tempfile import numpy as np import pandas as pd from sklearn.compose import ColumnTransformer from sklearn.impute import SimpleImputer from sklearn.pipeline import Pipeline from sklearn.preprocessing import StandardScaler, OneHotEncoder # Because this is a headerless CSV file, specify the column names here. feature_columns_names = [ "sex", "length", "diameter", "height", "whole_weight", "shucked_weight", "viscera_weight", "shell_weight", ] label_column = "rings" feature_columns_dtype = { "sex": str, "length": np.float64, "diameter": np.float64, "height": np.float64, "whole_weight": np.float64, "shucked_weight": np.float64, "viscera_weight": np.float64, "shell_weight": np.float64 } label_column_dtype = {"rings": np.float64} def merge_two_dicts(x, y): z = x.copy() z.update(y) return z if __name__ == "__main__": base_dir = "/opt/ml/processing" df = pd.read_csv( f"{base_dir}/input/abalone-dataset.csv", header=None, names=feature_columns_names + [label_column], dtype=merge_two_dicts(feature_columns_dtype, label_column_dtype) ) numeric_features = list(feature_columns_names) numeric_features.remove("sex") numeric_transformer = Pipeline( steps=[ ("imputer", SimpleImputer(strategy="median")), ("scaler", StandardScaler()) ] ) categorical_features = ["sex"] categorical_transformer = Pipeline( steps=[ ("imputer", SimpleImputer(strategy="constant", fill_value="missing")), ("onehot", OneHotEncoder(handle_unknown="ignore")) ] ) preprocess = ColumnTransformer( transformers=[ ("num", numeric_transformer, numeric_features), ("cat", categorical_transformer, categorical_features) ] ) y = df.pop("rings") X_pre = preprocess.fit_transform(df) y_pre = y.to_numpy().reshape(len(y), 1) X = np.concatenate((y_pre, X_pre), axis=1) np.random.shuffle(X) train, validation, test = np.split(X, [int(.7*len(X)), int(.85*len(X))]) pd.DataFrame(train).to_csv(f"{base_dir}/train/train.csv", header=False, index=False) pd.DataFrame(validation).to_csv(f"{base_dir}/validation/validation.csv", header=False, index=False) pd.DataFrame(test).to_csv(f"{base_dir}/test/test.csv", header=False, index=False) -
-
Erstellen Sie eine Instance von
SKLearnProcessor, die an den Verarbeitungsschritt übergeben werden soll.from sagemaker.sklearn.processing import SKLearnProcessor framework_version = "0.23-1" sklearn_processor = SKLearnProcessor( framework_version=framework_version, instance_type="ml.m5.xlarge", instance_count=processing_instance_count, base_job_name="sklearn-abalone-process", sagemaker_session=pipeline_session, role=role, ) -
Erstellen Sie einen Verarbeitungsschritt. In diesem Schritt werden die
SKLearnProcessorEingabe- und Ausgabekanäle sowie das von Ihnen erstelltepreprocessing.pySkript berücksichtigt. Dies ist derrunMethode einer Prozessorinstanz im SageMaker AI Python SDK sehr ähnlich. Der Parameterinput_data, der anProcessingStepübergeben wird, sind die Eingabedaten des Schrittes selbst. Diese Eingabedaten werden von der Prozessor-Instance verwendet, wenn sie ausgeführt wird.Beachten Sie die in der Ausgabekonfiguration für den Verarbeitungsauftrag angegebenen
"train,"validation, und"test"benannten Kanäle. SchrittePropertieswie diese können in nachfolgenden Schritten verwendet werden und zur Laufzeit in ihre Laufzeitwerte aufgelöst werden.from sagemaker.processing import ProcessingInput, ProcessingOutput from sagemaker.workflow.steps import ProcessingStep processor_args = sklearn_processor.run( inputs=[ ProcessingInput(source=input_data, destination="/opt/ml/processing/input"), ], outputs=[ ProcessingOutput(output_name="train", source="/opt/ml/processing/train"), ProcessingOutput(output_name="validation", source="/opt/ml/processing/validation"), ProcessingOutput(output_name="test", source="/opt/ml/processing/test") ], code="abalone/preprocessing.py", ) step_process = ProcessingStep( name="AbaloneProcess", step_args=processor_args )
Schritt 4: Definieren Sie einen Trainingsschritt
In diesem Abschnitt wird gezeigt, wie der SageMaker XGBoostKI-Algorithmus verwendet wird, um ein Modell anhand der Trainingsdaten zu trainieren, die aus den Verarbeitungsschritten ausgegeben werden.
Um einen Trainingsschritt zu definieren
-
Geben Sie den Modellpfad an, in dem Sie die Modelle aus dem Training speichern möchten.
model_path = f"s3://{default_bucket}/AbaloneTrain" -
Konfigurieren Sie einen Schätzer für den XGBoost Algorithmus und den Eingabedatensatz. Der Typ der Trainings-Instance wird an den Schätzer übergeben. Ein typisches Trainingsskript:
-
lädt Daten aus den Eingangskanälen
-
konfiguriert das Training mit Hyperparametern
-
trainiert ein Modell
-
speichert ein Modell unter,
model_dirdamit es später gehostet werden kann
SageMaker Die KI lädt das Modell in Form eines Jobs
model.tar.gzam Ende der Schulung auf Amazon S3 hoch.from sagemaker.estimator import Estimator image_uri = sagemaker.image_uris.retrieve( framework="xgboost", region=region, version="1.0-1", py_version="py3", instance_type="ml.m5.xlarge" ) xgb_train = Estimator( image_uri=image_uri, instance_type="ml.m5.xlarge", instance_count=1, output_path=model_path, sagemaker_session=pipeline_session, role=role, ) xgb_train.set_hyperparameters( objective="reg:linear", num_round=50, max_depth=5, eta=0.2, gamma=4, min_child_weight=6, subsample=0.7, silent=0 ) -
-
Erstellen Sie
TrainingStepmithilfe des Estimators eine Instanz und die Eigenschaften von.ProcessingStepÜbergeben Sie denS3Urivon"train"und den"validation"Ausgangskanal an denTrainingStep.from sagemaker.inputs import TrainingInput from sagemaker.workflow.steps import TrainingStep train_args = xgb_train.fit( inputs={ "train": TrainingInput( s3_data=step_process.properties.ProcessingOutputConfig.Outputs[ "train" ].S3Output.S3Uri, content_type="text/csv" ), "validation": TrainingInput( s3_data=step_process.properties.ProcessingOutputConfig.Outputs[ "validation" ].S3Output.S3Uri, content_type="text/csv" ) }, ) step_train = TrainingStep( name="AbaloneTrain", step_args = train_args )
Schritt 5: Definieren Sie einen Verarbeitungsschritt für die Modellbewertung
In diesem Abschnitt wird erläutert, wie Sie einen Verarbeitungsschritt erstellen, um die Genauigkeit des Modells zu bewerten. Das Ergebnis dieser Modellevaluierung wird im Bedingungsschritt verwendet, um zu bestimmen, welcher Laufpfad eingeschlagen werden soll.
Um einen Verarbeitungsschritt für die Modellevaluierung zu definieren
-
Erstellen Sie im Verzeichnis
/abaloneeine Datei mit dem Namenevaluation.py. Dieses Skript wird in einem Verarbeitungsschritt zur Durchführung der Modellevaluierung verwendet. Es verwendet ein trainiertes Modell und den Testdatensatz als Eingabe und erstellt dann eine JSON-Datei mit Bewertungsmetriken für die Klassifizierung.%%writefile abalone/evaluation.py import json import pathlib import pickle import tarfile import joblib import numpy as np import pandas as pd import xgboost from sklearn.metrics import mean_squared_error if __name__ == "__main__": model_path = f"/opt/ml/processing/model/model.tar.gz" with tarfile.open(model_path) as tar: tar.extractall(path=".") model = pickle.load(open("xgboost-model", "rb")) test_path = "/opt/ml/processing/test/test.csv" df = pd.read_csv(test_path, header=None) y_test = df.iloc[:, 0].to_numpy() df.drop(df.columns[0], axis=1, inplace=True) X_test = xgboost.DMatrix(df.values) predictions = model.predict(X_test) mse = mean_squared_error(y_test, predictions) std = np.std(y_test - predictions) report_dict = { "regression_metrics": { "mse": { "value": mse, "standard_deviation": std }, }, } output_dir = "/opt/ml/processing/evaluation" pathlib.Path(output_dir).mkdir(parents=True, exist_ok=True) evaluation_path = f"{output_dir}/evaluation.json" with open(evaluation_path, "w") as f: f.write(json.dumps(report_dict)) -
Erstellen Sie eine Instance von
ScriptProcessor, die verwendet wird, um eineProcessingStepzu erstellen.from sagemaker.processing import ScriptProcessor script_eval = ScriptProcessor( image_uri=image_uri, command=["python3"], instance_type="ml.m5.xlarge", instance_count=1, base_job_name="script-abalone-eval", sagemaker_session=pipeline_session, role=role, ) -
Erstellen Sie
ProcessingStepmithilfe der Prozessorinstanz, der Eingabe- und Ausgangskanäle und desevaluation.pySkripts eine. Weitergeben:-
die
S3ModelArtifactsImmobilie aus demstep_trainTrainingsschritt -
die
S3Urides"test"Ausgangskanals desstep_processVerarbeitungsschritts
Dies ist der
runMethode einer Prozessorinstanz im SageMaker AI Python SDK sehr ähnlich.from sagemaker.workflow.properties import PropertyFile evaluation_report = PropertyFile( name="EvaluationReport", output_name="evaluation", path="evaluation.json" ) eval_args = script_eval.run( inputs=[ ProcessingInput( source=step_train.properties.ModelArtifacts.S3ModelArtifacts, destination="/opt/ml/processing/model" ), ProcessingInput( source=step_process.properties.ProcessingOutputConfig.Outputs[ "test" ].S3Output.S3Uri, destination="/opt/ml/processing/test" ) ], outputs=[ ProcessingOutput(output_name="evaluation", source="/opt/ml/processing/evaluation"), ], code="abalone/evaluation.py", ) step_eval = ProcessingStep( name="AbaloneEval", step_args=eval_args, property_files=[evaluation_report], ) -
Schritt 6: Definieren Sie eine CreateModelStep für die Batch-Transformation
Wichtig
Wir empfehlen Schritt „Modell“ die Verwendung zum Erstellen von Modellen ab Version 2.90.0 des SageMaker Python SDK. CreateModelStepfunktioniert weiterhin in früheren Versionen des SageMaker Python-SDK, wird aber nicht mehr aktiv unterstützt.
In diesem Abschnitt wird gezeigt, wie aus der Ausgabe des Trainingsschritts ein SageMaker KI-Modell erstellt wird. Dieses Modell wird für die Batch-Transformation eines neuen Datensatzes verwendet. Dieser Schritt wird an den Bedingungsschritt übergeben und wird nur ausgeführt, wenn der Bedingungsschritt als 0 bewertet wird. true
Um eine CreateModelStep Batch-Transformation zu definieren
-
Erstellen Sie ein SageMaker KI-Modell. Übergeben Sie die
S3ModelArtifactsEigenschaft aus demstep_trainTrainingsschritt.from sagemaker.model import Model model = Model( image_uri=image_uri, model_data=step_train.properties.ModelArtifacts.S3ModelArtifacts, sagemaker_session=pipeline_session, role=role, ) -
Definieren Sie die Modelleingabe für Ihr SageMaker KI-Modell.
from sagemaker.inputs import CreateModelInput inputs = CreateModelInput( instance_type="ml.m5.large", accelerator_type="ml.eia1.medium", ) -
Erstellen Sie Ihre
CreateModelStepunter Verwendung derCreateModelInputvon Ihnen definierten SageMaker AI-Modellinstanz.from sagemaker.workflow.steps import CreateModelStep step_create_model = CreateModelStep( name="AbaloneCreateModel", model=model, inputs=inputs, )
Schritt 7: Definieren Sie eine TransformStep , um eine Batch-Transformation durchzuführen
In diesem Abschnitt wird gezeigt, wie ein TransformStep erstellt wird, um eine Batch-Transformation an einem Datensatz durchzuführen, nachdem das Modell trainiert wurde. Dieser Schritt wird an den Bedingungsschritt übergeben und wird nur ausgeführt, wenn der Bedingungsschritt den Wert 1 ergibt. true
Um eine TransformStep Batch-Transformation zu definieren
-
Erstellen Sie eine Transformer-Instance mit dem entsprechenden Compute-Instance-Typ, der Instance-Anzahl und der gewünschten Amazon S3-Output-Bucket-URI. Übergeben Sie die
ModelNameEigenschaft aus demstep_create_modelCreateModelSchritt.from sagemaker.transformer import Transformer transformer = Transformer( model_name=step_create_model.properties.ModelName, instance_type="ml.m5.xlarge", instance_count=1, output_path=f"s3://{default_bucket}/AbaloneTransform" ) -
Erstellen Sie eine
TransformStepmit der Transformer-Instance, die Sie definiert haben, und dembatch_dataPipeline-Parameter.from sagemaker.inputs import TransformInput from sagemaker.workflow.steps import TransformStep step_transform = TransformStep( name="AbaloneTransform", transformer=transformer, inputs=TransformInput(data=batch_data) )
Schritt 8: Definieren Sie einen RegisterModel Schritt zum Erstellen eines Modellpakets
Wichtig
Wir empfehlen Schritt „Modell“ die Verwendung zur Registrierung von Modellen ab Version 2.90.0 des SageMaker Python SDK. RegisterModelfunktioniert weiterhin in früheren Versionen des SageMaker Python-SDK, wird aber nicht mehr aktiv unterstützt.
In diesem Abschnitt wird gezeigt, wie Sie eine Instanz von erstellenRegisterModel. Das Ergebnis der Ausführung RegisterModel in einer Pipeline ist ein Modellpaket. Ein Modellpaket ist eine wiederverwendbare Abstraktion von Modellartefakten, die alle für die Inferenz erforderlichen Bestandteile verpackt. Es besteht aus einer Inferenzspezifikation, die das zu verwendende Inferenz-Image zusammen mit einer optionalen Position der Modellgewichte definiert. Eine Modellpaketgruppe ist eine Sammlung von Modellpaketen. Sie können ModelPackageGroup für Pipelines verwenden, um der Gruppe für jeden Pipeline-Lauf eine neue Version und ein neues Modellpaket hinzuzufügen. Weitere Informationen zur Modellregistrierung finden Sie unter Modellregistrierung und Bereitstellung mit Model Registry.
Dieser Schritt wird an den Bedingungsschritt übergeben und wird nur ausgeführt, wenn der Bedingungsschritt den Wert 1 ergibt. true
Um einen RegisterModel Schritt zur Erstellung eines Modellpakets zu definieren
-
Konstruieren Sie einen
RegisterModelSchritt mit der Estimator-Instance, die Sie für den Trainingsschritt verwendet haben. Übergeben Sie dieS3ModelArtifactsEigenschaft aus demstep_trainTrainingsschritt und geben SieModelPackageGroupan. Pipelines erstellt dasModelPackageGroupfür Sie.from sagemaker.model_metrics import MetricsSource, ModelMetrics from sagemaker.workflow.step_collections import RegisterModel model_metrics = ModelMetrics( model_statistics=MetricsSource( s3_uri="{}/evaluation.json".format( step_eval.arguments["ProcessingOutputConfig"]["Outputs"][0]["S3Output"]["S3Uri"] ), content_type="application/json" ) ) step_register = RegisterModel( name="AbaloneRegisterModel", estimator=xgb_train, model_data=step_train.properties.ModelArtifacts.S3ModelArtifacts, content_types=["text/csv"], response_types=["text/csv"], inference_instances=["ml.t2.medium", "ml.m5.xlarge"], transform_instances=["ml.m5.xlarge"], model_package_group_name=model_package_group_name, approval_status=model_approval_status, model_metrics=model_metrics )
Schritt 9: Definieren Sie einen Bedingungsschritt zur Überprüfung der Modellgenauigkeit
A ConditionStep ermöglicht Pipelines, die bedingte Ausführung in Ihrer Pipeline-DAG auf der Grundlage des Zustands der Schritteigenschaften zu unterstützen. In diesem Fall möchten Sie ein Modellpaket nur registrieren, wenn die Genauigkeit dieses Modells den erforderlichen Wert überschreitet. Die Genauigkeit des Modells wird durch den Schritt der Modellbewertung bestimmt. Wenn die Genauigkeit den erforderlichen Wert überschreitet, erstellt die Pipeline auch ein SageMaker KI-Modell und führt eine Batch-Transformation für einen Datensatz durch. In diesem Abschnitt wird erläutert, wie der Schritt Bedingung definiert wird.
Um einen Bedingungsschritt zur Überprüfung der Modellgenauigkeit zu definieren
-
Definieren Sie eine
ConditionLessThanOrEqualToBedingung anhand des Genauigkeitswerts, der in der Ausgabe des Verarbeitungsschritts der Modellbewertung ermittelt wurde,step_eval. Verwenden Sie für diese Ausgabe die Eigenschaftendatei, die Sie im Verarbeitungsschritt indexiert haben, und den entsprechenden JSONPath quadratischen Fehlerwert."mse"from sagemaker.workflow.conditions import ConditionLessThanOrEqualTo from sagemaker.workflow.condition_step import ConditionStep from sagemaker.workflow.functions import JsonGet cond_lte = ConditionLessThanOrEqualTo( left=JsonGet( step_name=step_eval.name, property_file=evaluation_report, json_path="regression_metrics.mse.value" ), right=6.0 ) -
Konstruieren Sie ein
ConditionStep. Übergeben Sie dieConditionEqualsBedingung und legen Sie dann die Schritte zur Registrierung des Modellpakets und zur Batch-Transformation als nächste Schritte fest, wenn die Bedingung erfüllt ist.step_cond = ConditionStep( name="AbaloneMSECond", conditions=[cond_lte], if_steps=[step_register, step_create_model, step_transform], else_steps=[], )
Schritt 10: Erstellen einer Pipeline
Nachdem Sie nun alle Schritte erstellt haben, können Sie sie zu einer Pipeline zusammenfassen.
So erstellen Sie eine Pipeline
-
Definieren Sie Folgendes für Ihre Pipeline:
name,parameters, undsteps. Die Namen müssen innerhalb eines(account, region)-Paares eindeutig sein.Anmerkung
Ein Schritt kann entweder in der Schrittliste der Pipeline oder in den if/else-Schrittlisten des Bedingungsschritts nur einmal vorkommen. Er kann nicht in beiden vorkommen.
from sagemaker.workflow.pipeline import Pipeline pipeline_name = f"AbalonePipeline" pipeline = Pipeline( name=pipeline_name, parameters=[ processing_instance_count, model_approval_status, input_data, batch_data, ], steps=[step_process, step_train, step_eval, step_cond], ) -
(Optional) Untersuchen Sie die JSON-Pipeline-Definition, um sicherzustellen, dass sie korrekt formatiert ist.
import json json.loads(pipeline.definition())
Diese Pipeline-Definition ist bereit, an KI übermittelt zu werden SageMaker . Im nächsten Tutorial reichen Sie diese Pipeline an SageMaker AI ein und starten einen Lauf.
Sie können auch boto3
{'Version': '2020-12-01', 'Metadata': {}, 'Parameters': [{'Name': 'ProcessingInstanceType', 'Type': 'String', 'DefaultValue': 'ml.m5.xlarge'}, {'Name': 'ProcessingInstanceCount', 'Type': 'Integer', 'DefaultValue': 1}, {'Name': 'TrainingInstanceType', 'Type': 'String', 'DefaultValue': 'ml.m5.xlarge'}, {'Name': 'ModelApprovalStatus', 'Type': 'String', 'DefaultValue': 'PendingManualApproval'}, {'Name': 'ProcessedData', 'Type': 'String', 'DefaultValue': 'S3_URL', {'Name': 'InputDataUrl', 'Type': 'String', 'DefaultValue': 'S3_URL', 'PipelineExperimentConfig': {'ExperimentName': {'Get': 'Execution.PipelineName'}, 'TrialName': {'Get': 'Execution.PipelineExecutionId'}}, 'Steps': [{'Name': 'ReadTrainDataFromFS', 'Type': 'Processing', 'Arguments': {'ProcessingResources': {'ClusterConfig': {'InstanceType': 'ml.m5.4xlarge', 'InstanceCount': 2, 'VolumeSizeInGB': 30}}, 'AppSpecification': {'ImageUri': 'IMAGE_URI', 'ContainerArguments': [....]}, 'RoleArn': 'ROLE', 'ProcessingInputs': [...], 'ProcessingOutputConfig': {'Outputs': [.....]}, 'StoppingCondition': {'MaxRuntimeInSeconds': 86400}}, 'CacheConfig': {'Enabled': True, 'ExpireAfter': '30d'}}, ... ... ... }
Nächster Schritt: Ausführen Sie eine Pipeline
