Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
SageMaker Überblick über Pipelines
Eine Amazon SageMaker Model Building Pipelines-Pipeline besteht aus einer Reihe miteinander verbundener Schritte, die mithilfe des Pipelines
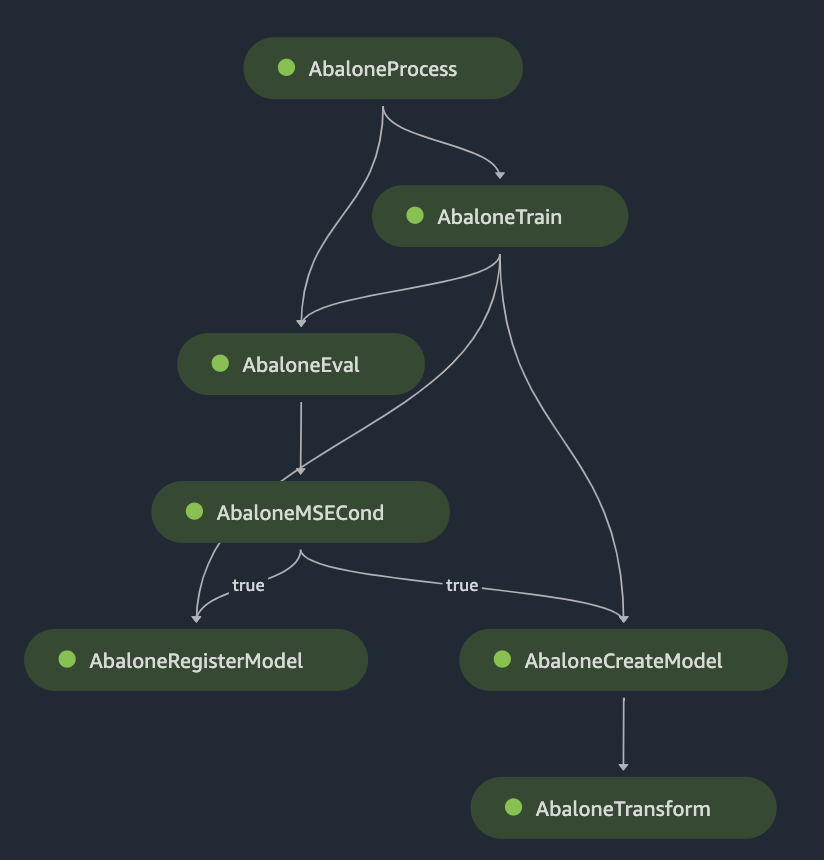
Die Beispiel-DAG umfasst die folgenden Schritte:
AbaloneProcess, eine Instanz des Verarbeitungsschritts, führt ein Vorverarbeitungsskript für die für das Training verwendeten Daten aus. Das Skript könnte beispielsweise fehlende Werte ausfüllen, numerische Daten normalisieren oder Daten in die Datensätze „Train“, „Validation“ und „Test“ aufteilen.AbaloneTrain, eine Instanz des Trainingsschritts, konfiguriert Hyperparameter und trainiert ein Modell anhand der vorverarbeiteten Eingabedaten.AbaloneEval, eine weitere Instanz des Verarbeitungsschritts, bewertet das Modell auf seine Genauigkeit. Dieser Schritt zeigt ein Beispiel für eine Datenabhängigkeit. In diesem Schritt wird die Testdatensatzausgabe von verwendet.AbaloneProcessAbaloneMSECondist eine Instanz eines Bedingungsschritts, der in diesem Beispiel überprüft, ob das mean-square-error Ergebnis der Modellauswertung unter einem bestimmten Grenzwert liegt. Wenn das Modell die Kriterien nicht erfüllt, wird der Pipelinelauf beendet.Der Pipelinelauf wird mit den folgenden Schritten fortgesetzt:
AbaloneRegisterModel, wo ein SageMaker RegisterModelSchritt zur Registrierung des Modells als versionierte Modellpaketgruppe in der SageMaker Amazon-Modellregistrierung aufgerufen wird.AbaloneCreateModel, wobei ein SageMaker CreateModelSchritt zur Erstellung des Modells zur Vorbereitung der Batch-Transformation aufgerufen wird. In SageMaker ruft einen Transform-Schritt aufAbaloneTransform, um Modellvorhersagen für einen von Ihnen angegebenen Datensatz zu generieren.
In den folgenden Themen werden grundlegende Konzepte von SageMaker Pipelines beschrieben. Ein Tutorial, das die Implementierung dieser Konzepte beschreibt, finden Sie unter SageMaker Pipelines erstellen und verwalten.
Themen
- Struktur und Ausführung der Pipeline
- IAM-Zugriffsverwaltung
- Kontenübergreifender Support für Pipelines SageMaker
- Pipeline-Parameter
- Schritte zu Amazon SageMaker Model Building Pipelines
- L ift-and-shift Python-Code mit dem @step -Dekorator
- Daten zwischen Schritten weitergeben
- Zwischenspeichern von Pipeline-Schritten
- Richtlinie für Pipeline-Schritte erneut versuchen
- Selektive Ausführung von Pipeline-Schritten
- Basisberechnung, Drifterkennung und Lebenszyklus mit ClarifyCheck und QualityCheck Schritte in Amazon SageMaker Model Building Pipelines
- Pipeline-Läufe planen
- Integration von Amazon SageMaker Experiments
- Lokaler Modus
- Fehlerbehebung bei Amazon SageMaker Model Building Pipelines
