Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
IAM-Zugriffsverwaltung
In den folgenden Abschnitten werden die AWS Identity and Access Management (IAM-) Anforderungen für Amazon SageMaker Pipelines beschrieben. Ein Beispiel dafür, wie Sie diese Berechtigungen implementieren können, finden Sie unter Voraussetzungen.
Themen
Berechtigungen für Pipeline-Rollen
Ihre Pipeline erfordert eine IAM-Pipeline-Ausführungsrolle, die an Pipelines übergeben wird, wenn Sie eine Pipeline erstellen. Die Rolle für die SageMaker AI-Instanz, die die Pipeline erstellt, muss über die iam:PassRole Berechtigung für die Pipeline-Ausführungsrolle verfügen, um sie übergeben zu können. Weitere Informationen zu IAM-Rollen finden Sie unter IAM-Rollen.
Für Ihre Pipeline-Ausführungsrolle sind die folgenden Berechtigungen erforderlich:
-
Um eine Rolle an einen SageMaker KI-Job innerhalb einer Pipeline zu übergeben, ist dies die
iam:PassRoleBerechtigung für die Rolle, die übergeben wird. -
CreateundDescribeBerechtigungen für jeden Jobtyp in der Pipeline. -
Amazon-S3-Berechtigungen zur Verwendung der
JsonGetFunktion. Sie können den Zugriff auf Ressourcen mit einer identitätsbasierten oder ressourcenbasierten Richtlinie steuern. Eine ressourcenbasierte Richtlinie wird auf Ihren Amazon S3 S3-Bucket angewendet und gewährt Pipelines Zugriff auf den Bucket. Eine identitätsbasierte Richtlinie gibt Ihrer Pipeline die Möglichkeit, Amazon-S3-Anrufe von Ihrem Konto aus zu tätigen. Weitere Informationen zu ressourcenbasierten Richtlinien finden Sie unter Identitätsbasierte und ressourcenbasierte Richtlinien.{ "Action": [ "s3:GetObject" ], "Resource": "arn:aws:s3:::<your-bucket-name>/*", "Effect": "Allow" }
Berechtigungen für Pipeline-Schritte
Pipelines beinhalten Schritte, die KI-Jobs ausführen. SageMaker Damit die Pipeline-Schritte diese Jobs ausführen können, benötigen sie eine IAM-Rolle in Ihrem Konto, die Zugriff auf die benötigte Ressource bietet. Diese Rolle wird von Ihrer Pipeline an den SageMaker AI-Dienstprinzipal übergeben. Weitere Informationen zu Rollen finden Sie unter IAM-Rollen.
Standardmäßig übernimmt jeder Schritt die Rolle der Pipeline-Ausführung. Sie können optional jedem der Schritte in Ihrer Pipeline eine andere Rolle zuweisen. Dadurch wird sichergestellt, dass sich der Code in den einzelnen Schritten nicht auf Ressourcen auswirken kann, die in anderen Schritten verwendet werden, es sei denn, es besteht eine direkte Beziehung zwischen den beiden in der Pipeline-Definition angegebenen Schritten. Sie übergeben diese Rollen, wenn Sie den Prozessor oder den Schätzer für Ihren Schritt definieren. Beispiele dafür, wie diese Rollen in diese Definitionen aufgenommen werden können, finden Sie in der SageMaker AI Python SDK-Dokumentation
CORS-Konfiguration mit Amazon S3 S3-Buckets
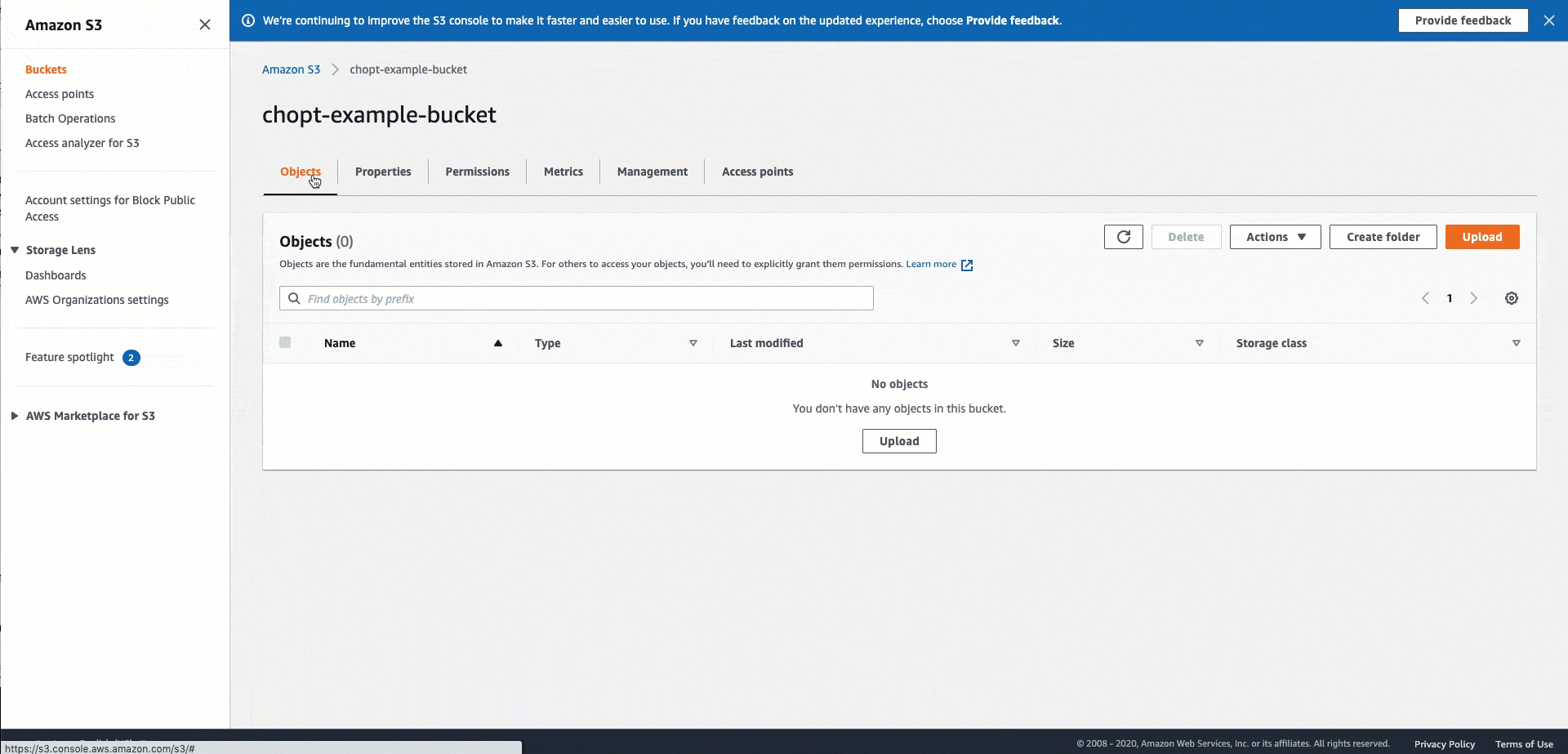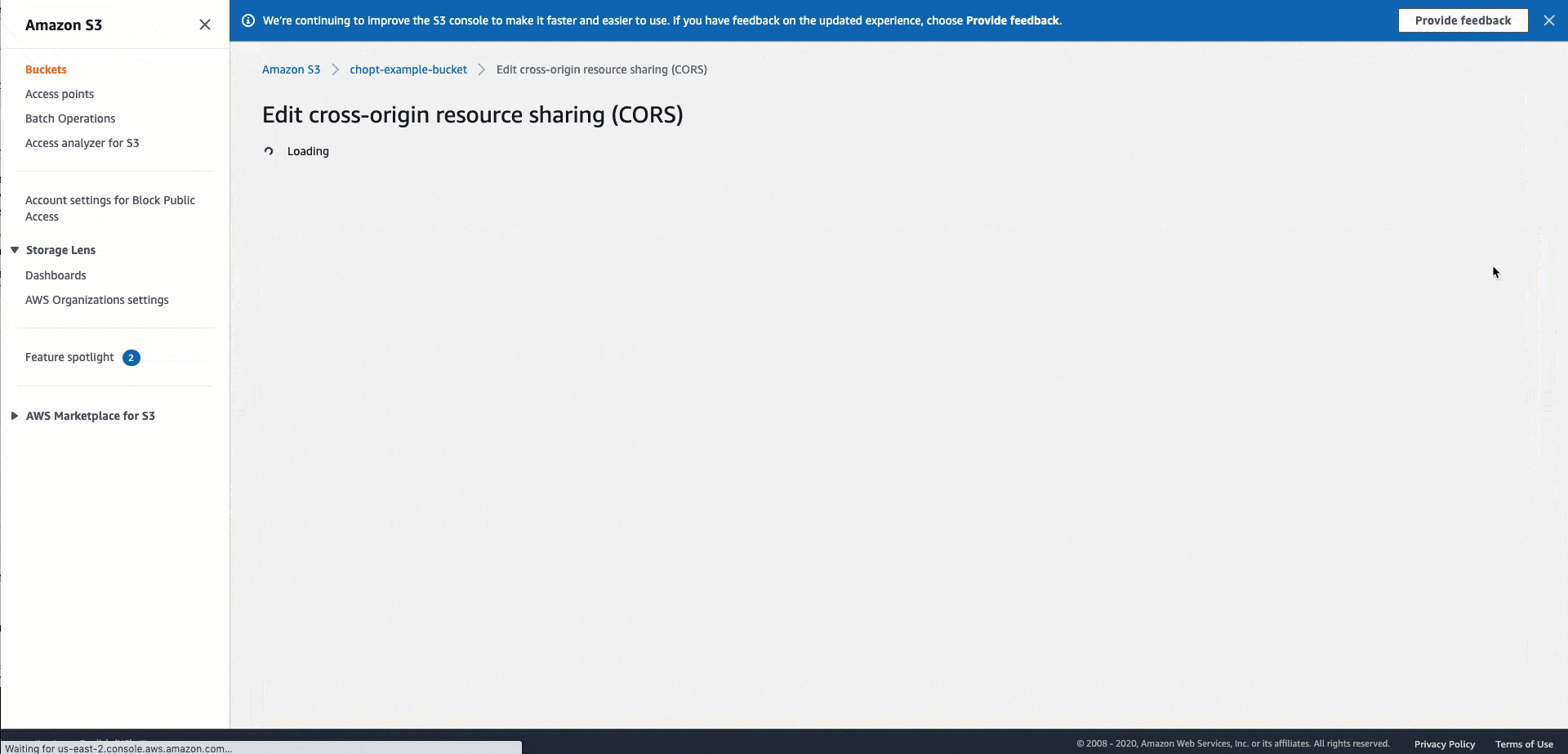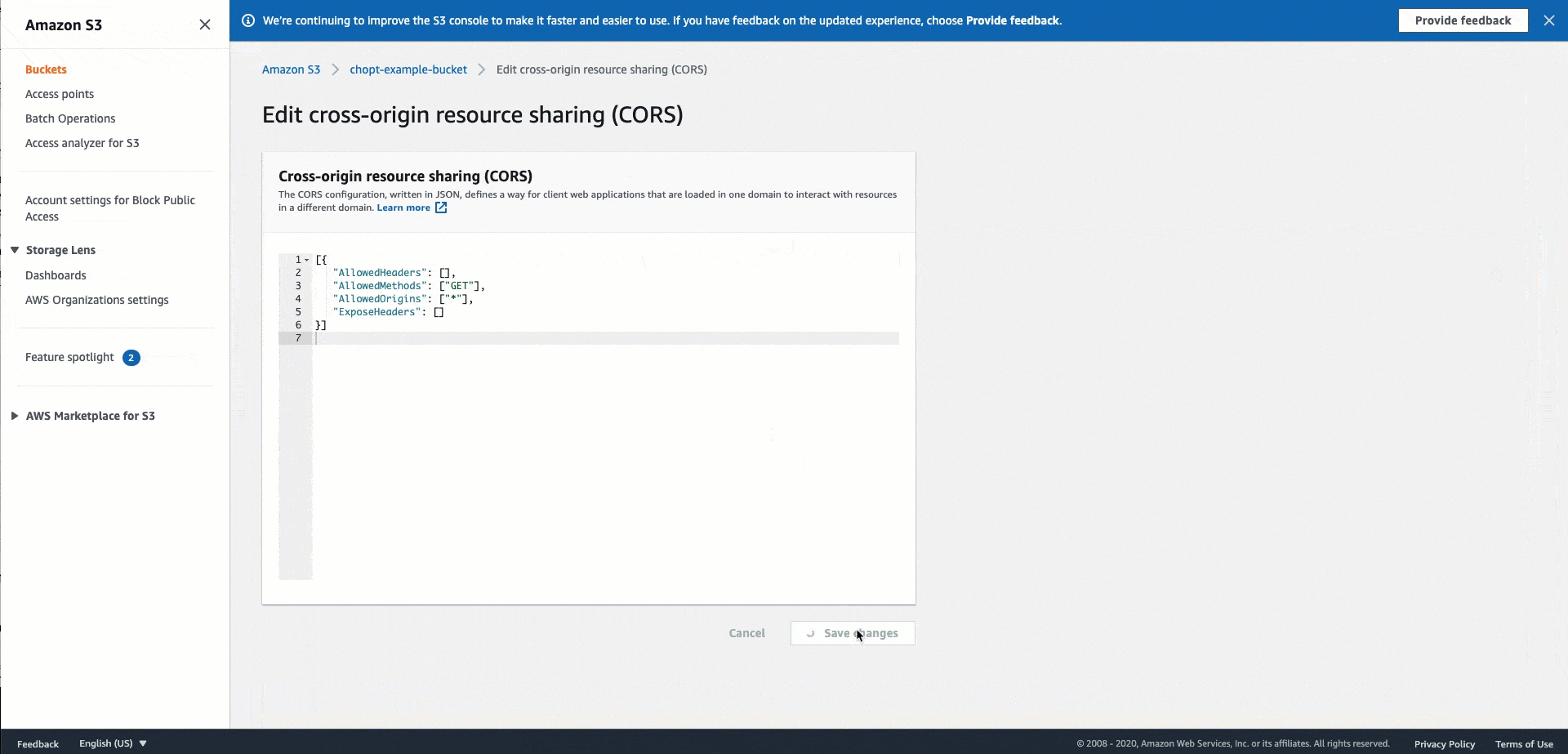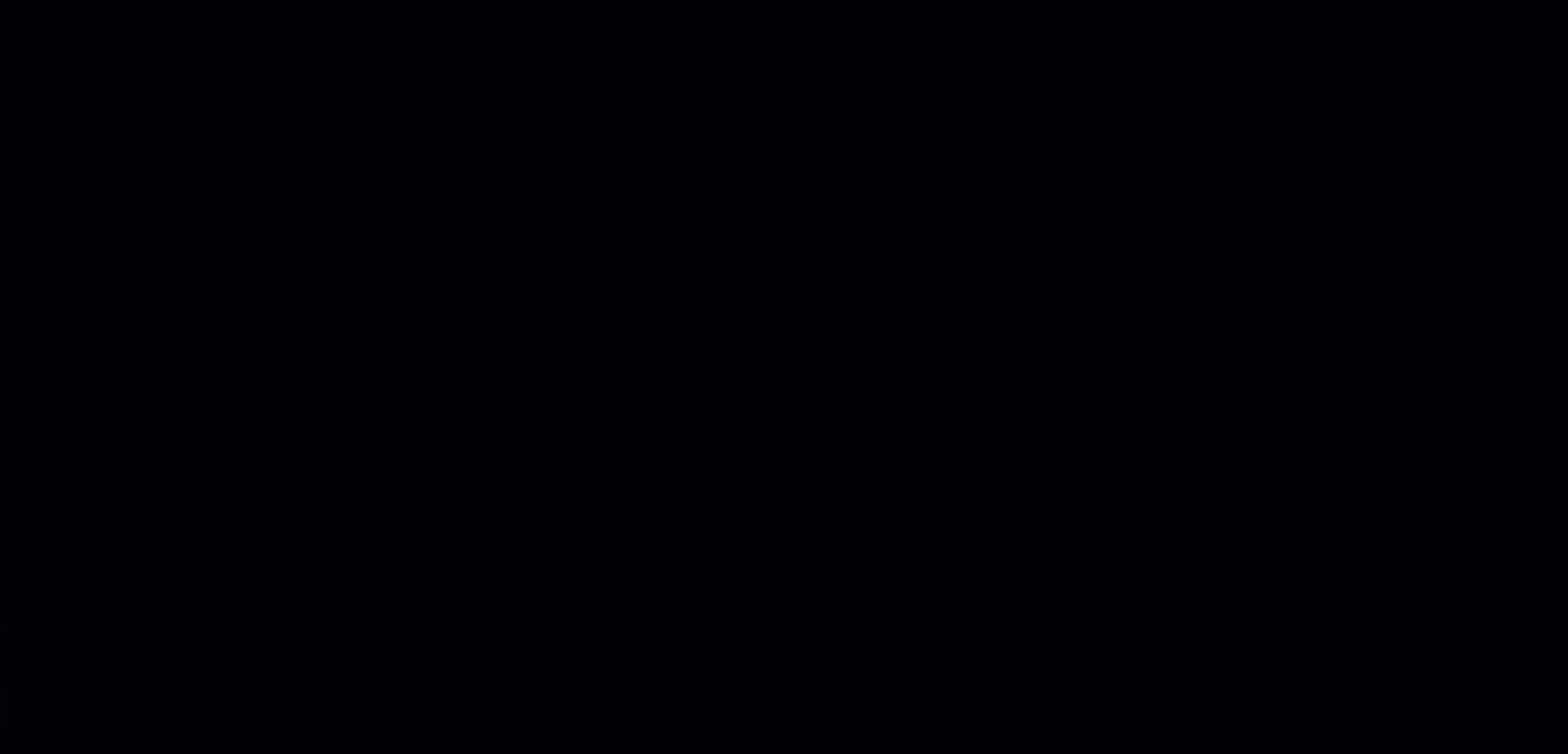
Um sicherzustellen, dass Ihre Bilder auf vorhersehbare Weise aus einem Amazon S3 S3-Bucket in Ihre Pipelines importiert werden, muss den Amazon S3 S3-Buckets, aus denen Bilder importiert werden, eine CORS-Konfiguration hinzugefügt werden. Dieser Abschnitt enthält Anweisungen zum Einstellen der erforderlichen CORS-Konfiguration für Ihren Amazon S3 S3-Bucket. Das für Pipelines CORSConfiguration erforderliche XML unterscheidet sich von dem in. CORS-Anforderung für Eingabebilddaten Andernfalls können Sie die dortigen Informationen verwenden, um mehr über die CORS-Anforderung mit Amazon S3 S3-Buckets zu erfahren.
Verwenden Sie den folgenden CORS-Konfigurationscode für die Amazon S3 S3-Buckets, die Ihre Bilder hosten. Anweisungen zur Konfiguration von CORS finden Sie unter Configuring Cross-Origin Resource Sharing (CORS) im Amazon Simple Storage Service-Benutzerhandbuch. Wenn Sie die Amazon S3-Konsole verwenden, um die Richtlinie zu Ihrem Bucket hinzuzufügen, müssen Sie das JSON-Format verwenden.
JSON
[ { "AllowedHeaders": [ "*" ], "AllowedMethods": [ "PUT" ], "AllowedOrigins": [ "*" ], "ExposeHeaders": [ "Access-Control-Allow-Origin" ] } ]
XML
<CORSConfiguration> <CORSRule> <AllowedHeader>*</AllowedHeader> <AllowedOrigin>*</AllowedOrigin> <AllowedMethod>PUT</AllowedMethod> <ExposeHeader>Access-Control-Allow-Origin</ExposeHeader> </CORSRule> </CORSConfiguration>
Das folgende GIF zeigt die Anweisungen in der Amazon S3-Dokumentation zum Hinzufügen einer CORS-Header-Richtlinie mithilfe der Amazon S3-Konsole.
Passen Sie die Zugriffsverwaltung für Pipelines-Jobs an
Sie können Ihre IAM-Richtlinien weiter anpassen, sodass ausgewählte Mitglieder in Ihrer Organisation einzelne oder alle Pipeline-Schritte ausführen können. Sie können beispielsweise bestimmten Benutzern die Berechtigung zum Erstellen von Trainingsaufträgen und einer anderen Benutzergruppe die Berechtigung zum Erstellen von Verarbeitungsaufträgen und all Ihren Benutzern die Erlaubnis erteilen, die verbleibenden Schritte auszuführen. Um diese Funktion zu verwenden, wählen Sie eine benutzerdefinierte Zeichenfolge aus, die Ihrem Jobnamen vorangestellt wird. Ihr Administrator stellt dem Präfix „ ARNs Erlaubt“ das Präfix voran, während Ihr Data Scientist dieses Präfix in Pipeline-Instanziierungen einbezieht. Da die IAM-Richtlinie für zugelassene Benutzer einen Job-ARN mit dem angegebenen Präfix enthält, verfügen nachfolgende Jobs Ihres Pipeline-Schritts über die erforderlichen Berechtigungen, um fortzufahren. Das Job-Präfix ist standardmäßig deaktiviert. Sie müssen diese Option in Ihrer Pipeline Klasse aktivieren, um sie verwenden zu können.
Bei Jobs mit deaktiviertem Präfix wird der Jobname wie abgebildet formatiert und ist eine Verkettung von Feldern, die in der folgenden Tabelle beschrieben werden:
pipelines-<executionId>-<stepNamePrefix>-<entityToken>-<failureCount>
| Feld | Definition |
|---|---|
|
Pipelines |
Eine statische Zeichenfolge wird immer vorangestellt. Diese Zeichenfolge identifiziert den Pipeline-Orchestrierungsdienst als Quelle des Jobs. |
|
executionId |
Ein zufälliger Puffer für die laufende Instance der Pipeline. |
|
stepNamePrefix |
Der vom Benutzer angegebene Schrittname (im |
|
entityToken |
Ein zufälliges Token, um die Idempotenz der Schrittentität sicherzustellen. |
|
failureCount |
Die aktuelle Anzahl der Versuche, den Job abzuschließen. |
In diesem Fall wird dem Jobnamen kein benutzerdefiniertes Präfix vorangestellt, und die entsprechende IAM-Richtlinie muss mit dieser Zeichenfolge übereinstimmen.
Für Benutzer, die das Job-Präfix aktivieren, hat der zugrunde liegende Jobname die folgende Form, wobei das benutzerdefinierte Präfix wie folgt angegeben ist: MyBaseJobName
<MyBaseJobName>-<executionId>-<entityToken>-<failureCount>
Das benutzerdefinierte Präfix ersetzt die statische pipelines Zeichenfolge, sodass Sie die Auswahl der Benutzer einschränken können, die den SageMaker KI-Job als Teil einer Pipeline ausführen können.
Längenbeschränkungen für das Präfix
Die Auftragsnamen haben interne Längenbeschränkungen, die für einzelne Pipeline-Schritte spezifisch sind. Diese Einschränkung begrenzt auch die Länge des zulässigen Präfixes. Die Anforderungen an die Präfixlänge lauten wie folgt:
| Pipeline-Schritt | Länge des Präfixes |
|---|---|
|
|
38 |
|
6 |
Wenden Sie Job-Präfixe auf eine IAM-Richtlinie an
Ihr Administrator erstellt IAM-Richtlinien, die es Benutzern mit bestimmten Präfixen ermöglichen, Jobs zu erstellen. Die folgende Beispielrichtlinie ermöglicht es Datenwissenschaftlern, Trainingsjobs zu erstellen, wenn sie das MyBaseJobName Präfix verwenden.
{ "Action": "sagemaker:CreateTrainingJob", "Effect": "Allow", "Resource": [ "arn:aws:sagemaker:region:account-id:*/MyBaseJobName-*" ] }
Wenden Sie Job-Präfixe auf Pipeline-Instanziierungen an
Sie geben Ihr Präfix mit dem *base_job_name Argument der Job-Instance-Klasse an.
Anmerkung
Sie übergeben Ihr Job-Präfix mit dem *base_job_name Argument an die Job-Instance, bevor Sie einen Pipeline-Schritt erstellen. Diese Auftrags-Instance enthält die erforderlichen Informationen, damit der Job als Schritt in einer Pipeline ausgeführt werden kann. Dieses Argument hängt von der verwendeten Auftrags-Instance ab. Die folgende Liste zeigt, welches Argument für jeden Pipeline-Schritttyp verwendet werden sollte:
-
base_job_namefür die KlassenEstimator(TrainingStep),Processor(ProcessingStep) undAutoML(AutoMLStep) -
tuning_base_job_namefür dieTunerKlasse (TuningStep) -
transform_base_job_namefür dieTransformerKlasse (TransformStep) -
base_job_namevonCheckJobConfigfür die KlassenQualityCheckStep(Qualitätsprüfung) undClarifyCheckstep(Klärungsprüfung) -
Für die
ModelKlasse hängt das verwendete Argument davon ab, ob Sie das Modell ausführencreateoder ob esregistersich um Ihr Modell handelt, bevor das Ergebnis an übergeben wirdModelStep-
Wenn Sie
createaufrufen, stammt das benutzerdefinierte Präfix aus demnameArgument, das Sie bei der Konstruktion Ihres Modells angegeben haben (d. h.,Model(name=)) -
Wenn Sie
registeraufrufen, stammt das benutzerdefinierte Präfix aus demmodel_package_nameArgument Ihres Aufrufs vonregister(d. h.,my_model.register(model_package_name=)
-
Im folgenden Beispiel wird gezeigt, wie Sie ein Präfix für eine neue Trainingsauftrags-Instance angeben:
# Create a job instance xgb_train = Estimator( image_uri=image_uri, instance_type="ml.m5.xlarge", instance_count=1, output_path=model_path, role=role, subnets=["subnet-0ab12c34567de89f0"], base_job_name="MyBaseJobName" security_group_ids=["sg-1a2bbcc3bd4444e55"], tags = [ ... ] encrypt_inter_container_traffic=True, ) # Attach your job instance to a pipeline step step_train = TrainingStep( name="TestTrainingJob", estimator=xgb_train, inputs={ "train": TrainingInput(...), "validation": TrainingInput(...) } )
Das Auftrag-Präfix ist standardmäßig deaktiviert. Um sich für diese Funktion zu entscheiden, verwenden Sie die use_custom_job_prefix Option von PipelineDefinitionConfig, wie im folgenden Codeausschnitt gezeigt:
from sagemaker.workflow.pipeline_definition_config import PipelineDefinitionConfig # Create a definition configuration and toggle on custom prefixing definition_config = PipelineDefinitionConfig(use_custom_job_prefix=True); # Create a pipeline with a custom prefix pipeline = Pipeline( name="MyJobPrefixedPipeline", parameters=[...] steps=[...] pipeline_definition_config=definition_config )
Erstellen Sie Ihre Pipeline und führen Sie sie aus. Im folgenden Beispiel wird eine Pipeline erstellt und ausgeführt. Außerdem wird veranschaulicht, wie Sie das Auftrag-Präfix deaktivieren und Ihre Pipeline erneut ausführen können.
pipeline.create(role_arn=sagemaker.get_execution_role()) # Optionally, call definition() to confirm your prefixed job names are in the built JSON pipeline.definition() pipeline.start() # To run a pipeline without custom-prefixes, toggle off use_custom_job_prefix, update the pipeline # via upsert() or update(), and start a new run definition_config = PipelineDefinitionConfig(use_custom_job_prefix=False) pipeline.pipeline_definition_config = definition_config pipeline.update() execution = pipeline.start()
In ähnlicher Weise können Sie die Funktion für bestehende Pipelines aktivieren und eine neue Ausführung starten, die Auftragspräfixe verwendet.
definition_config = PipelineDefinitionConfig(use_custom_job_prefix=True) pipeline.pipeline_definition_config = definition_config pipeline.update() execution = pipeline.start()
Schließlich können Sie Ihren Auftrag mit einem benutzerdefinierten Präfix anzeigen, indem Sie die Pipeline-Ausführung aufrufenlist_steps.
steps = execution.list_steps() prefixed_training_job_name = steps['PipelineExecutionSteps'][0]['Metadata']['TrainingJob']['Arn']
Passen Sie den Zugriff auf Pipeline-Versionen an
Mithilfe des sagemaker:PipelineVersionId Bedingungsschlüssels können Sie benutzerdefinierten Zugriff auf bestimmte Versionen von Amazon SageMaker Pipelines gewähren. Die folgende Richtlinie gewährt beispielsweise Zugriff auf das Starten von Ausführungen oder das Aktualisieren der Pipeline-Version nur für Version 6 und höher.
{ "Version": "2012-10-17", "Statement": [ { "Sid": "AllowStartPipelineExecution", "Effect": "Allow", "Action": [ "sagemaker:StartPipelineExecution", "sagemaker:UpdatePipelineVersion" ], "Resource": "*", "Condition": { "NumericGreaterThanEquals": { "sagemaker:PipelineVersionId": 6 } } } }
Weitere Informationen zu unterstützten Bedingungsschlüsseln finden Sie unter Bedingungsschlüssel für Amazon SageMaker AI.
Service-Kontrollrichtlinien mit Pipelines
Richtlinien zur Dienstkontrolle (SCPs) sind eine Art von Organisationsrichtlinie, mit der Sie Berechtigungen in Ihrer Organisation verwalten können. SCPs bieten eine zentrale Kontrolle über die maximal verfügbaren Berechtigungen für alle Konten in Ihrer Organisation. Durch die Verwendung von Pipelines innerhalb Ihrer Organisation können Sie sicherstellen, dass Datenwissenschaftler Ihre Pipeline-Ausführungen verwalten, ohne mit der AWS Konsole interagieren zu müssen.
Wenn Sie eine VPC mit Ihrem SCP verwenden, die den Zugriff auf Amazon S3 einschränkt, müssen Sie Maßnahmen ergreifen, damit Ihre Pipeline auf andere Amazon S3-Ressourcen zugreifen kann.
Um Pipelines den Zugriff auf Amazon S3 außerhalb Ihrer VPC mit dieser JsonGet Funktion zu ermöglichen, aktualisieren Sie den SCP Ihrer Organisation, um sicherzustellen, dass die Rolle, die Pipelines verwendet, auf Amazon S3 zugreifen kann. Erstellen Sie dazu mithilfe eines Prinzipal-Tags und eines Bedingungsschlüssels eine Ausnahme für Rollen, die vom Pipeline-Executor über die Pipeline-Ausführungsrolle verwendet werden.
Um Pipelines den Zugriff auf Amazon S3 außerhalb Ihrer VPC zu ermöglichen
-
Erstellen Sie ein eindeutiges Tag für Ihre Pipeline-Ausführungsrolle, indem Sie die Schritte unter Taggen von IAM-Benutzern und -Rollen befolgen.
-
Gewähren Sie in Ihrem SCP mithilfe des
Aws:PrincipalTag IAMBedingungsschlüssels für das von Ihnen erstellte Tag eine Ausnahme. Weitere Informationen finden Sie unter Erstellen, Aktualisieren und Löschen von Service-Kontrollrichtlinien.
