Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
SageMaker JumpStart vortrainierte Modelle
Amazon SageMaker JumpStart bietet vortrainierte Open-Source-Modelle für eine Vielzahl von Problemtypen, um Ihnen den Einstieg in maschinelles Lernen zu erleichtern. Sie können diese Modelle vor der Bereitstellung schrittweise trainieren und optimieren. JumpStart bietet außerdem Lösungsvorlagen, mit denen die Infrastruktur für allgemeine Anwendungsfälle eingerichtet wird, sowie ausführbare Beispiel-Notebooks für maschinelles Lernen mit SageMaker KI.
Sie können vortrainierte Modelle aus beliebten Model-Hubs über die JumpStart Landingpage in der aktualisierten Studio-Oberfläche bereitstellen, optimieren und auswerten.
Sie können auch über die JumpStart Landingpage in Amazon SageMaker Studio Classic auf vortrainierte Modelle, Lösungsvorlagen und Beispiele zugreifen.
Die folgenden Schritte zeigen, wie Sie mit Amazon SageMaker Studio und Amazon SageMaker Studio Classic auf JumpStart Modelle zugreifen.
Sie können auch mit dem SageMaker Python-SDK auf JumpStart Modelle zugreifen. Informationen zur programmgesteuerten Verwendung von JumpStart Modellen finden Sie unter Verwenden von SageMaker JumpStart Algorithmen mit vortrainierten
In Studio öffnen und verwenden JumpStart
Die folgenden Abschnitte enthalten Informationen zum Öffnen, Verwenden und Verwalten JumpStart von der Studio-Benutzeroberfläche aus.
Wichtig
Seit dem 30. November 2023 heißt das vorherige Amazon SageMaker Studio-Erlebnis jetzt Amazon SageMaker Studio Classic. Der folgende Abschnitt bezieht sich speziell auf die Nutzung des aktualisierten Studio-Erlebnisses. Informationen zur Verwendung der Studio Classic-Anwendung finden Sie unterAmazon SageMaker Studio Klassisch.
JumpStart In Studio öffnen
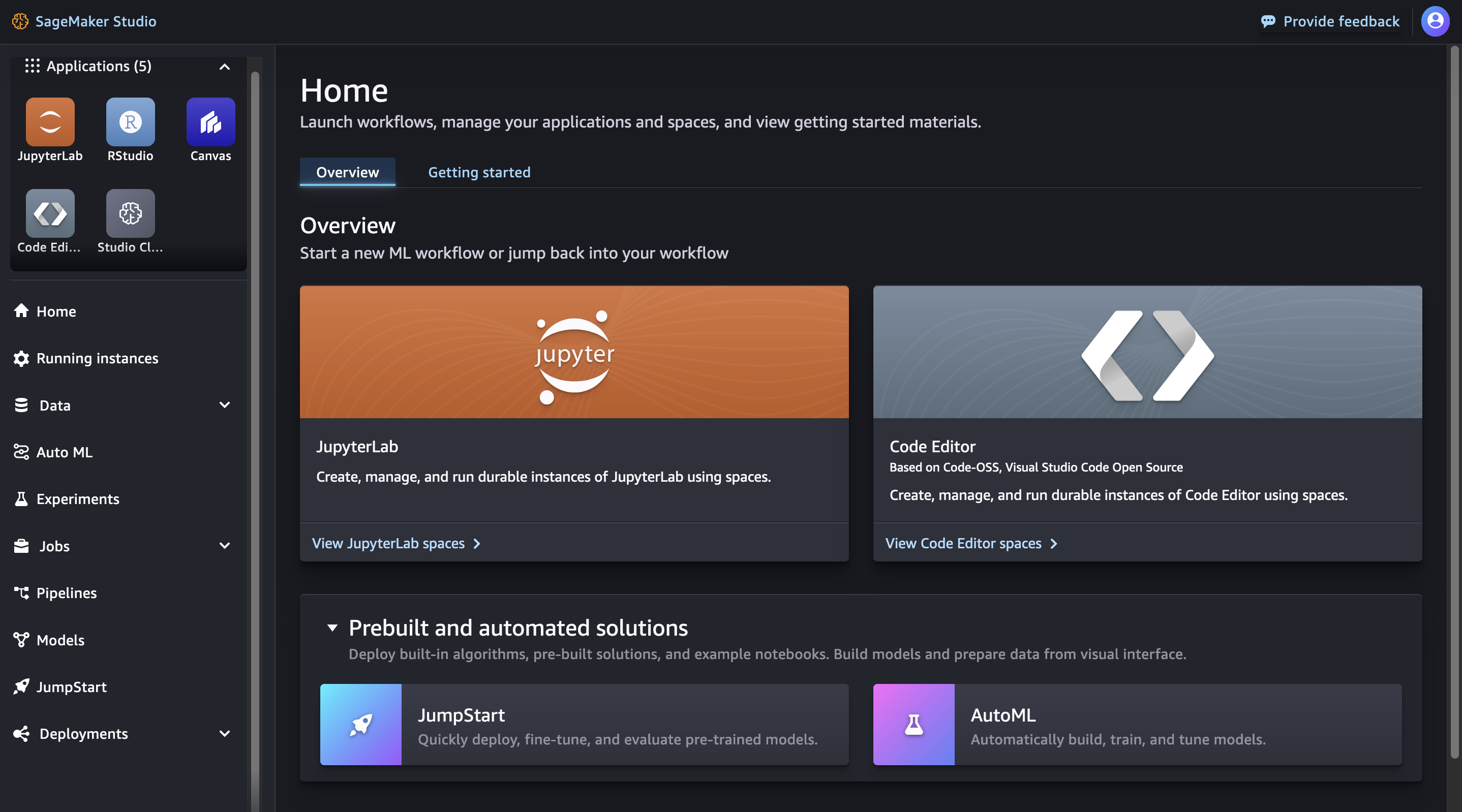
Öffnen Sie in Amazon SageMaker Studio die JumpStart Landing Page entweder über die Startseite oder das Home-Menü auf der linken Seite. Dadurch wird die SageMaker JumpStartLandingpage geöffnet, auf der Sie Model-Hubs erkunden und nach Modellen suchen können.
-
Wählen Sie auf der Startseite JumpStartim Bereich Vorgefertigte und automatisierte Lösungen aus.
-
Navigieren Sie über das Home-Menü im linken Bereich zum SageMaker JumpStartKnoten.
Weitere Informationen zu den ersten Schritten mit Amazon SageMaker Studio finden Sie unterAmazon SageMaker Studio.
Wichtig
Vor dem Herunterladen oder Verwenden von Inhalten Dritter: Sie sind dafür verantwortlich, alle geltenden Lizenzbedingungen zu überprüfen und einzuhalten sowie sicherzustellen, dass sie für Ihren Anwendungsfall akzeptabel sind.
JumpStart In Studio verwenden
Auf der SageMaker JumpStartLandingpage in Studio können Sie Model Hubs von Anbietern sowohl proprietärer als auch öffentlich verfügbarer Modelle erkunden.
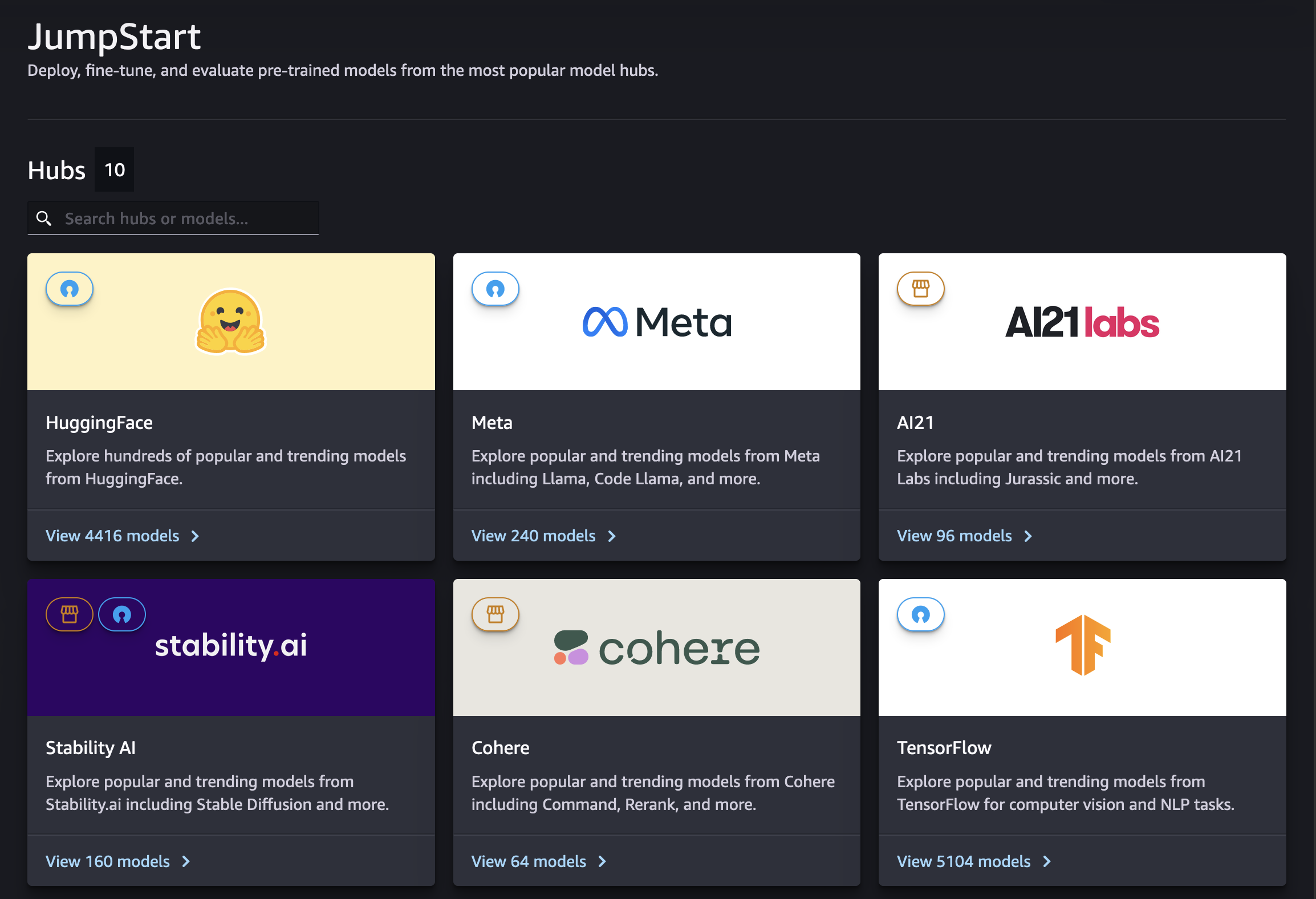
Über die Suchleiste können Sie nach bestimmten Hubs oder Modellen suchen. In jedem Model-Hub können Sie direkt nach Modellen suchen, nach bereitgestellten Attributen sortieren oder anhand einer Liste bereitgestellter Modellaufgaben filtern.
JumpStart In Studio verwalten
Wählen Sie ein Modell aus, um die zugehörige Modelldetailkarte zu sehen. Wählen Sie in der oberen rechten Ecke der Modelldetailkarte Feinabstimmung, Bereitstellung oder Evaluieren aus, um mit der Bearbeitung der jeweiligen Feinabstimmungs-, Bereitstellungs- oder Evaluierungsworkflows zu beginnen. Beachten Sie, dass nicht alle Modelle für die Feinabstimmung oder Evaluierung verfügbar sind. Weitere Informationen zu den einzelnen Optionen finden Sie unterVerwenden Sie Foundation-Modelle in Studio.
JumpStart In Studio Classic öffnen und verwenden
Die folgenden Abschnitte enthalten Informationen zum Öffnen, Verwenden und Verwalten über die JumpStart Amazon SageMaker Studio Classic-Benutzeroberfläche.
Wichtig
Seit dem 30. November 2023 heißt das vorherige Amazon SageMaker Studio-Erlebnis jetzt Amazon SageMaker Studio Classic. Der folgende Abschnitt bezieht sich speziell auf die Verwendung der Studio Classic-Anwendung. Informationen zur Verwendung der aktualisierten Studio-Oberfläche finden Sie unterAmazon SageMaker Studio.
JumpStart In Studio Classic öffnen
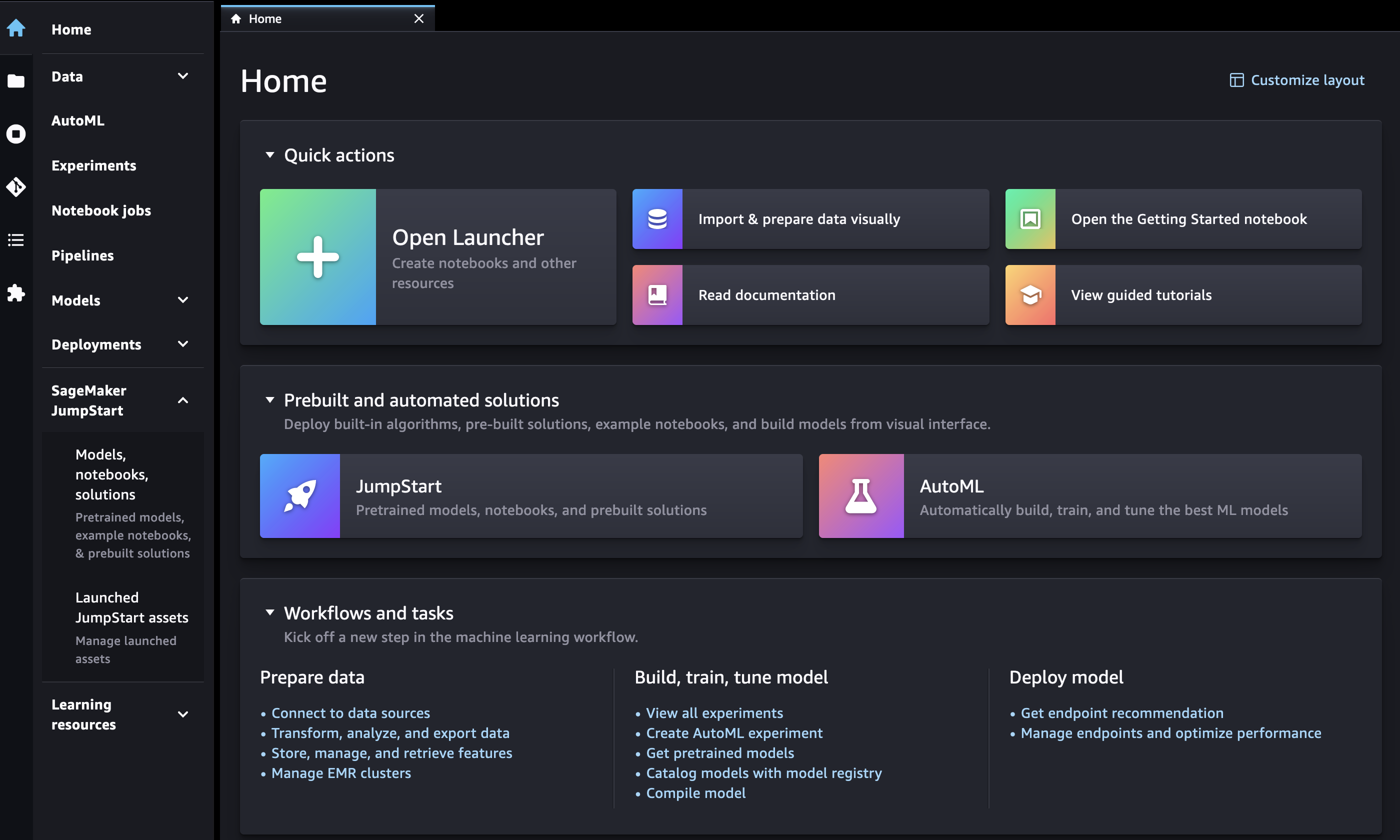
Öffnen Sie in Amazon SageMaker Studio Classic die JumpStart Landing Page entweder über die Startseite oder das Home-Menü auf der linken Seite.
-
Auf der Startseite haben Sie folgende Möglichkeiten:
-
Wählen Sie JumpStartim Bereich Vorgefertigte und automatisierte Lösungen aus. Dadurch wird die SageMaker JumpStartLandingpage geöffnet.
-
Wählen Sie direkt auf der SageMaker JumpStartLandingpage ein Modell aus, oder wählen Sie die Option Alle erkunden, um verfügbare Lösungen oder Modelle eines bestimmten Typs zu sehen.
-
-
Im Menü Home im linken Bereich haben Sie folgende Möglichkeiten:
-
Navigieren Sie zum SageMaker JumpStartKnoten und wählen Sie dann Modelle, Notizbücher, Lösungen aus. Dadurch wird die SageMaker JumpStartLandingpage geöffnet.
-
Navigieren Sie zum JumpStartKnoten und wählen Sie dann Launched JumpStart Assets aus.
Auf der Seite JumpStart Launched Assets werden Ihre aktuell eingeführten Lösungen, bereitgestellten Modellendpunkte und Trainingsjobs, die mit JumpStart erstellt wurden, aufgeführt. Sie können von dieser Registerkarte aus auf die JumpStart Landingpage zugreifen, indem Sie oben rechts auf der Registerkarte auf die JumpStart Schaltfläche Durchsuchen klicken.
-
Auf der JumpStart Landingpage werden verfügbare Lösungen für end-to-end maschinelles Lernen, vortrainierte Modelle und Beispiel-Notizbücher aufgeführt. Auf jeder einzelnen Lösungs- oder Modellseite können Sie oben rechts auf der Registerkarte auf die JumpStart Schaltfläche „Durchsuchen“ (
 ) klicken, um zur SageMaker JumpStartSeite zurückzukehren.
) klicken, um zur SageMaker JumpStartSeite zurückzukehren.
Wichtig
Vor dem Herunterladen oder Verwenden von Inhalten Dritter: Sie sind dafür verantwortlich, alle geltenden Lizenzbedingungen zu überprüfen und einzuhalten sowie sicherzustellen, dass sie für Ihren Anwendungsfall akzeptabel sind.
JumpStart In Studio Classic verwenden
Auf der SageMaker JumpStartLandingpage können Sie nach Lösungen, Modellen, Notizbüchern und anderen Ressourcen suchen.
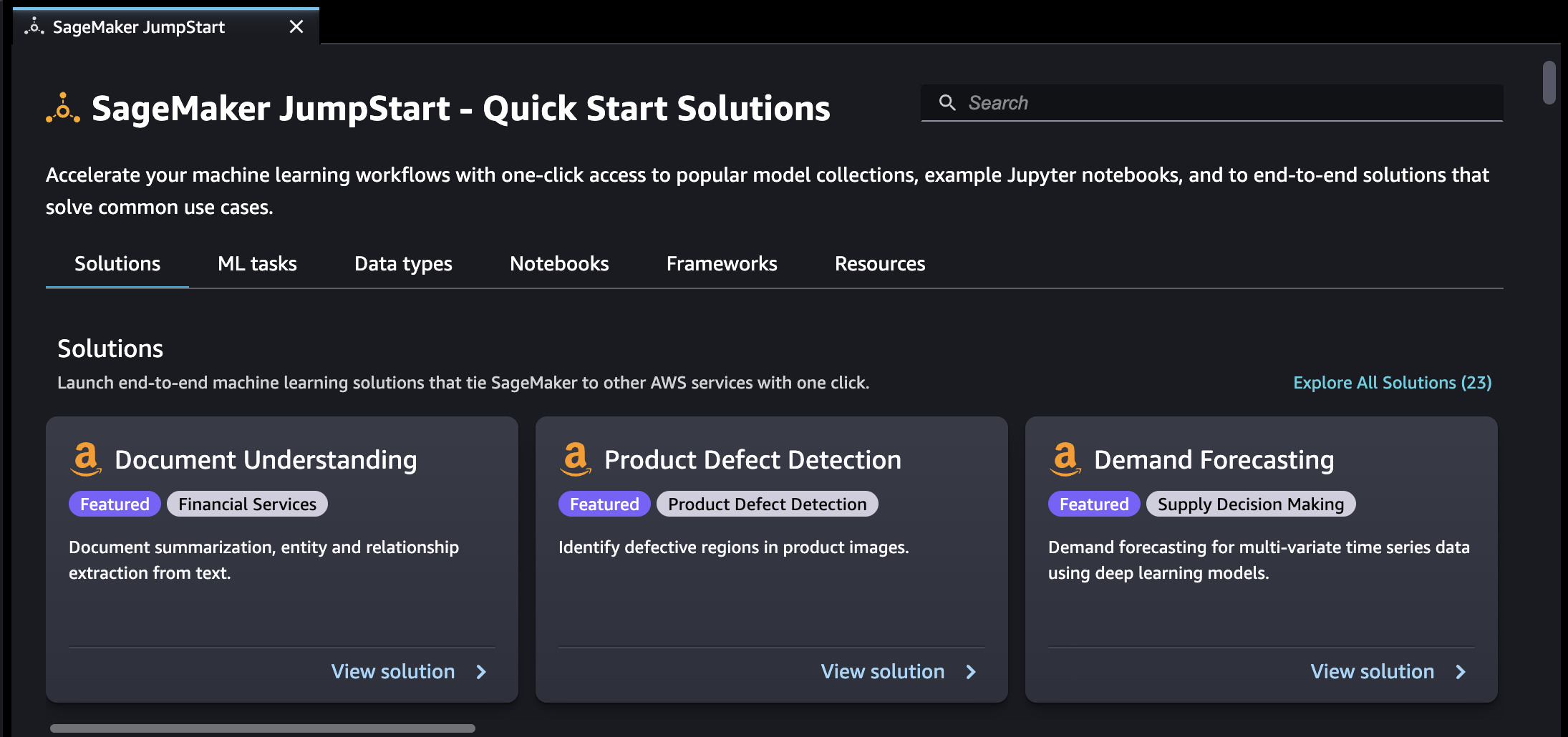
Sie können JumpStart Ressourcen mithilfe der Suchleiste finden oder indem Sie die einzelnen Kategorien durchsuchen. Über die Tabs können Sie die verfügbaren Lösungen nach Kategorien filtern:
-
Lösungen — Führen Sie in einem Schritt umfassende Lösungen für maschinelles Lernen ein, die SageMaker KI mit anderen verbinden AWS-Services. Wählen Sie Alle Lösungen untersuchen, um alle verfügbaren Lösungen anzuzeigen.
-
Ressourcen – Verwenden Sie Beispiel-Notebooks, Blogs und Videotutorials, um sich mit Ihren Problemtypen vertraut zu machen und sich einen Vorsprung zu verschaffen.
-
Blogs – Lesen Sie Details und Lösungen von Experten für Machine Learning.
-
Video-Tutorials — Sehen Sie sich Video-Tutorials zu SageMaker KI-Funktionen und Anwendungsfällen für maschinelles Lernen von Experten für maschinelles Lernen an.
-
Beispiel-Notebooks — Führen Sie Beispiel-Notebooks aus, die SageMaker KI-Funktionen wie Spot-Instance-Schulungen und Experimente für eine Vielzahl von Modelltypen und Anwendungsfällen verwenden.
-
-
Datentypen – Suchen Sie nach einem Modell nach Datentyp (z. B. Vision, Text, Tabellarisch, Audio, Textgenerierung). Wählen Sie Alle Modelle untersuchen, um alle verfügbaren Modelle anzuzeigen.
-
ML-Aufgaben – Suchen Sie nach einem Modell nach Problemtyp (z. B. Bildklassifizierung, Bildeinbettung, Objekterkennung, Textgenerierung). Wählen Sie Alle Modelle untersuchen, um alle verfügbaren Modelle anzuzeigen.
-
Notizbücher — Finden Sie Beispiel-Notebooks, die SageMaker KI-Funktionen für verschiedene Modelltypen und Anwendungsfälle verwenden. Wählen Sie Alle Notebooks untersuchen, um alle verfügbaren Beispiel-Notebooks anzuzeigen.
-
Frameworks — Finden Sie ein Modell nach Framework (z. B.,, PyTorch TensorFlow, Hugging Face).
JumpStart In Studio Classic verwalten
Navigieren Sie im Hauptmenü im linken Bereich zu Launched Assets und wählen Sie dann Launched JumpStart Assets aus SageMaker JumpStart, um Ihre aktuell eingeführten Lösungen, bereitgestellten Modellendpunkte und Trainingsjobs, die mit JumpStart erstellt wurden, aufzulisten.
Themen
