Szenario 4: Erkennung von Unregelmäßigkeiten durch Gerätesensoren in Echtzeit und Benachrichtigung
Das Unternehmen ABC4Logistics transportiert leicht entzündliche Mineralölprodukte wie Benzin, Flüssigpropan (LPG) und Naphtha vom Hafen in verschiedene Städte. Es besitzt eine Flotte mit Hunderten Fahrzeugen, die mit mehreren Sensoren ausgerüstet sind, um z. B. den Standort, die Motortemperatur, die Temperatur im Inneren des Containers, die Fahrgeschwindigkeit, den Standort des Fahrzeugs, den Straßenzustand und so weiter zu überwachen. Eine der Anforderungen von ABC4Logistics besteht darin, die Temperaturen des Motors und des Containers in Echtzeit zu überwachen und den Fahrer und das Flottenüberwachungsteam im Falle einer Unregelmäßigkeit zu alarmieren. Um solche Bedingungen zu erkennen und Warnungen in Echtzeit zu generieren, implementierte ABC4Logistics die folgende Architektur in AWS.
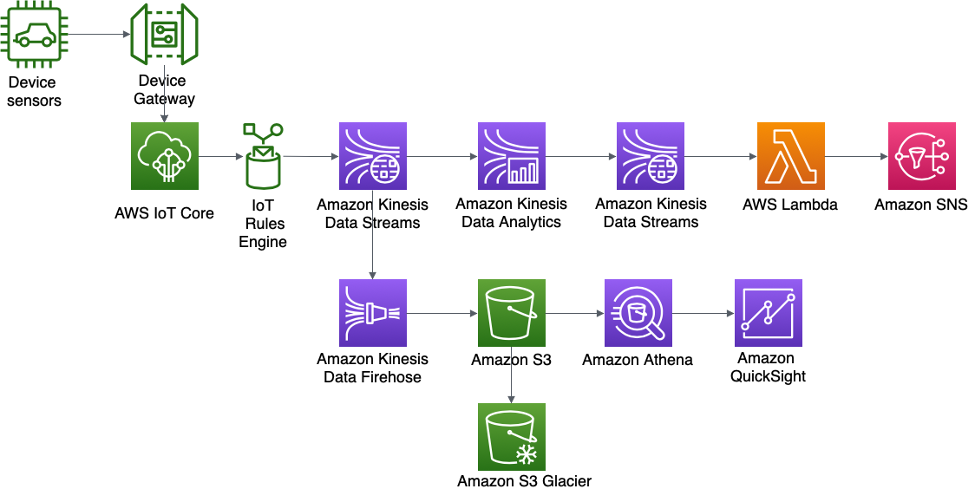
Geräte-Sensoren für die Echtzeit-Erkennung von Unregelmäßigkeiten und Benachrichtigungsarchitektur von ABC4Logistics
Die Daten von Gerätesensoren werden vom AWS IoT-Gateway aufgenommen, in dem die -RegelAWS IoT-Engine die Streaming-Daten in Amazon Kinesis Data Streams zur Verfügung stellt. Mit Kinesis Data Analytics kann ABC4Logistics die Echtzeitanalyse von Streaming-Daten in Kinesis Data Streams durchführen.
Mithilfe von Kinesis Data Analytics kann ABC4Logistics erkennen, wenn die Temperaturmesswerte der Sensoren über einen Zeitraum von zehn Sekunden von den normalen Messwerten abweichen, und den Datensatz in eine andere Kinesis-Data-Streams-Instance einlesen, um die anomalen Datensätze zu identifizieren. Amazon Kinesis Data Streams ruft dann Lambda-Funktionen auf, die die Warnungen über Amazon SNS an den Fahrer und das Flottenüberwachungsteam senden können.
Daten in Kinesis Data Streams werden auch an Amazon Kinesis Data Firehose weitergeleitet. Amazon Kinesis Data Firehose persistiert diese Daten in Amazon S3 und ermöglicht ABC4Logistics die Durchführung von Batch- oder echtzeitnahen Analysen der Sensordaten. ABC4Logistics verwendet Amazon Athena
Wichtige Komponenten dieser Architektur werden im Folgenden erläutert.
Amazon Kinesis Data Analytics
Amazon Kinesis Data Analytics
Mit Amazon Kinesis Data Analytics können Sie interaktiv Streaming-Daten mit mehreren Optionen abfragen, einschließlich Standard-SQL-, Apache-Flink-Anwendungen in Java, Python und Scala, und Apache-Beam-Anwendungen mit Java zur Analyse von Datenströmen erstellen.
Diese Optionen bieten Ihnen die Flexibilität, je nach Komplexität der Streaming-Anwendung und der Quell-/Zielunterstützung einen bestimmten Ansatz zu wählen. Im folgenden Abschnitt wird die Option Kinesis Data Analytics für Flink-Anwendungen beschrieben.
Kinesis Data Analytics für Apache-Flink-Anwendungen
Apache Flink
Mit Amazon Kinesis Data Analytics für Apache Flink können Sie Code für Streaming-Quellen erstellen und ausführen, um Zeitreihenanalysen durchzuführen, Echtzeit-Dashboards zu speisen und Echtzeit-Metriken zu erstellen, ohne die komplexe verteilte Apache-Flink-Umgebung verwalten zu müssen. Sie können die allgemeinen Funktionen der Flink-Programmierung auf die gleiche Weise nutzen, wie Sie sie nutzen, wenn Sie die Flink-Infrastruktur selbst hosten.
Mit Kinesis Data Analytics für Apache Flink können Sie Anwendungen in Java, Scala, Python oder SQL zur Verarbeitung und Analyse von Streaming-Daten erstellen. Eine typische Flink-Anwendung liest die Daten aus dem Eingabe-Stream oder dem Datenspeicherort oder der Quelle, transformiert/filtert oder verbindet die Daten mithilfe von Operatoren oder Funktionen und speichert die Daten im Ausgabe-Stream oder Datenspeicherort oder in der Senke.
Das folgende Architekturdiagramm zeigt einige der unterstützten Quellen und Senken für die Kinesis-Data-Analytics-Flink-Anwendung. Zusätzlich zu den vorgebündelten Konnektoren für Quelle/Senke können Sie auch benutzerdefinierte Konnektoren zu einer Vielzahl anderer Quellen/Senken für Flink-Anwendungen in Kinesis Data Analytics einbringen.
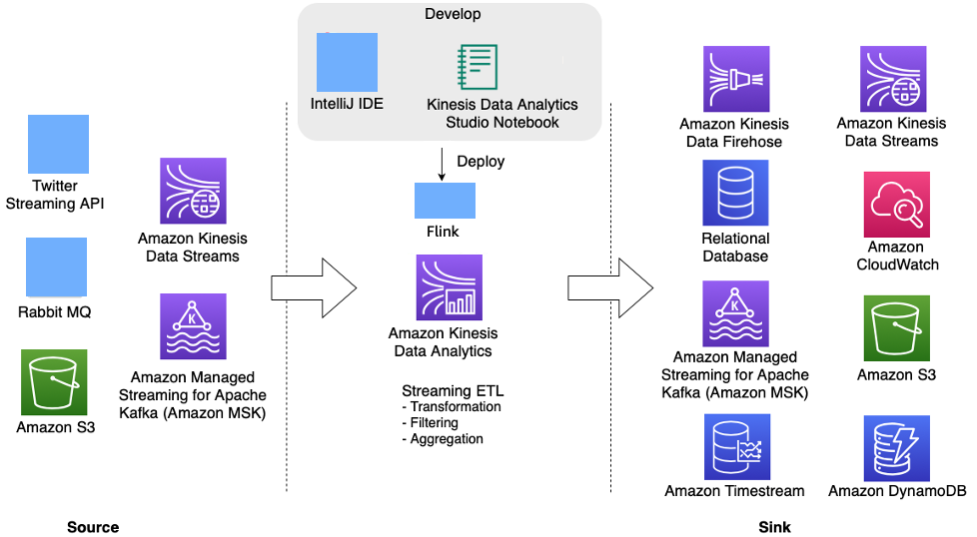
Apache-Flink-Anwendung in Kinesis Data Analytics für Datenstromverarbeitung in Echtzeit
Entwickler können ihre bevorzugte IDE verwenden, um Flink-Anwendungen zu entwickeln und sie über die AWS Management Console
Amazon Kinesis Data Analytics Studio
Als Teil des Kinesis Data Analytics Service steht Kunden Kinesis Data Analytics Studio
Mit Studio-Notebook haben Sie die Möglichkeit, Ihren Flink-Anwendungscode in einer Notebook-Umgebung zu entwickeln, sich die Ergebnisse Ihres Codes in Echtzeit anzeigen zu lassen und in Ihrem Notebook zu visualisieren. Sie können ein von Apache Zeppelin und Apache Flink unterstützes Studio-Notebook mit einem einzigen Klick von Kinesis Data Streams und der Amazon MSK-Konsole aus erstellen oder es von der Kinesis-Data-Analytics-Konsole aus starten.
Sobald Sie den Code iterativ als Teil des Kinesis Data Analytics Studio entwickelt haben, können Sie ein Notebook als Kinesis-Datenanalytik-Anwendung bereitstellen, um es kontinuierlich im Streaming-Modus auszuführen, Daten aus Ihren Quellen zu lesen, in Ihre Ziele zu schreiben, einen Anwendungsstatus langfristig beizubehalten und automatisch basierend auf dem Durchsatz Ihrer Quell-Streams zu skalieren. Bislang verwendeten Kunden für solche interaktiven Analysen von Echtzeit-Streaming-Daten in AWS Kinesis Data Analytics für SQL-Anwendungen.
Kinesis Data Analytics für SQL-Anwendungen ist zwar weiterhin verfügbar, für neue Projekte empfiehlt AWS jedoch die Verwendung des neuen Kinesis Data Analytics Studio
Um die Kinesis-Data-Analytics-Flink-Anwendung fehlertolerant zu gestalten, können Sie die Prüfpunkterstellung und Snapshots verwenden, wie im Abschnitt Implementieren der Fehlertoleranz in Kinesis Data Analytics für Apache Flink beschrieben.
Kinesis-Data-Analytics-Flink-Anwendungen sind nützlich für das Schreiben komplexer Streaming-Analytik-Anwendungen, wie z. B. Anwendungen mit „Genau Einmal“-Semantik
Nach der Verarbeitung von Streaming-Daten in der Flink-Anwendung können Sie die Daten in verschiedenen Senken oder Zielen wie Amazon Kinesis Data Streams, Amazon Kinesis Data Firehose, Amazon DynamoDB, Amazon OpenSearch Service, Amazon Timestream, Amazon S3 usw. persistieren. Die Kinesis-Data-Analytics-Flink-Anwendung bietet außerdem Leistungsgarantien in Sekundenbruchteilen.
Apache-Beam-Anwendungen für Kinesis Data Analytics
Apache Beam
Sie können das Apache-Beam-Framework mit Ihrer Kinesis-Datenanalytik-Anwendung verwenden, um Streaming-Daten zu verarbeiten. Kinesis-Datenanalytik-Anwendungen, die Apache Beam verwenden, nutzen den Apache-Flink-Runner
Übersicht
Durch die Nutzung der AWS-Streaming-Services Amazon Kinesis Data Streams, Amazon Kinesis Data Analytics und Amazon Kinesis Data Firehose
kann ABC4Logistics anomale Muster in den Temperaturmesswerten erkennen und den Fahrer und das Flottenmanagementteam in Echtzeit benachrichtigen, um schwere Unfälle wie einen kompletten Fahrzeugausfall oder einen Brand zu verhindern.
