Conector Apache Kafka de Amazon Athena
El conector de Amazon Athena para Apache Kafka permite que Amazon Athena ejecute consultas SQL en los temas de Apache Kafka. Use este conector para ver los temas de Apache Kafka
Este conector no utiliza Conexiones de Glue para centralizar las propiedades de configuración en Glue. La conexión se configura a través de Lambda.
Requisitos previos
Implemente el conector en su Cuenta de AWS mediante la consola de Athena o AWS Serverless Application Repository. Para obtener más información, consulte Cómo crear una conexión de origen de datos o Uso del AWS Serverless Application Repository para implementar un conector de origen de datos.
Limitaciones
-
Las operaciones de escritura de DDL no son compatibles.
-
Cualquier límite de Lambda relevante. Para obtener más información, consulte Cuotas de Lambda en la Guía para desarrolladores de AWS Lambda.
-
Los tipos de datos de marca de fecha y hora en condiciones de filtro se deben convertir a los tipos de datos adecuados.
-
Los tipos de datos de fecha y hora no son compatibles con el tipo de archivo CSV y se tratan como valores varchar.
-
No se admite la asignación a campos JSON anidados. El conector solo asigna campos de nivel superior.
-
El conector no admite tipos complejos. Los tipos complejos se interpretan como cadenas.
-
Para extraer valores JSON complejos o trabajar con ellos, use las funciones relacionadas con JSON disponibles en Athena. Para obtener más información, consulte Extracción de datos JSON de cadenas.
-
El conector no permite el acceso a metadatos de mensajes de Kafka.
Términos
-
Controlador de metadatos: un controlador de Lambda que recupera los metadatos de la instancia de base de datos.
-
Controlador de registros: un controlador de Lambda que recupera registros de datos de la instancia de base de datos.
-
Controlador compuesto: un controlador de Lambda que recupera tanto los metadatos como los registros de datos de la instancia de base de datos.
-
Punto de conexión de Kafka: una cadena de texto que establece una conexión con una instancia de Kafka.
Compatibilidad con clústeres
El conector Kafka se puede usar con los siguientes tipos de clústeres.
-
Kafka independiente: una conexión directa con Kafka (autenticada o no autenticada).
-
Confluent: una conexión directa con Confluent Kafka. Para obtener información sobre el uso de Athena con datos de Confluent Kafka, consulte “Visualize Confluent data in QuickSight using Amazon Athena”
en el blog sobre inteligencia empresarial de AWS.
Conexión a Confluent
Para la conexión a Confluent, se deben seguir los siguientes pasos:
-
Genere una clave de API desde Confluent.
-
Guarde el nombre de usuario y la contraseña de la clave de API de Confluent en AWS Secrets Manager.
-
Proporcione el nombre secreto de la variable de entorno
secrets_manager_secreten el conector Kafka. -
Siga los pasos de la sección Configuración del conector Kafka de este documento.
Métodos de autenticación compatibles
El conector admite los siguientes métodos de autenticación.
-
SASL/PLAIN
-
SASL/PLAINTEXT
-
NO_AUTH
-
Kafka autogestionado y Confluent Platform: SSL, SASL/SCRAM, SASL/PLAINTEXT, NO_AUTH.
-
Kafka autogestionado y Confluent Cloud: SASL/PLAIN.
Para obtener más información, consulte Configuración de la autenticación del conector Kafka de Athena.
Formatos compatibles de datos de entrada
El conector admite los siguientes formatos de datos de entrada.
-
JSON
-
CSV
-
AVRO
-
PROTOBUF (BÚFERES DE PROTOCOLO)
Parámetros
Utilice los parámetros de esta sección para configurar el conector Athena Kafka.
-
auth_type: especifica el tipo de autenticación del clúster. El conector admite los siguientes tipos de autenticación:
-
NO_AUTH: conexión directa a Kafka (por ejemplo, a un clúster de Kafka implementado en una instancia de EC2 que no usa autenticación).
-
SASL_SSL_PLAIN: este método usa el protocolo de seguridad
SASL_SSLy el mecanismoPLAINSASL. Para obtener más información, consulte Configuración de SASLen la documentación de Apache Kafka. -
SASL_PLAINTEXT_PLAIN: este método usa el protocolo de seguridad
SASL_PLAINTEXTy el mecanismoPLAINSASL. Para obtener más información, consulte Configuración de SASLen la documentación de Apache Kafka. -
SASL_SSL_SCRAM_SHA512: puede usar este tipo de autenticación para controlar el acceso a los clústeres de Apache Kafka. Este método almacena el nombre de usuario y la contraseña en AWS Secrets Manager. El secreto debe estar asociado al clúster de Kafka. Para obtener más información, consulte Autenticación mediante SASL/SCRAM
en la documentación de Apache Kafka. -
SASL_PLAINTEXT_SCRAM_SHA512: este método usa el protocolo de seguridad
SASL_PLAINTEXTy el mecanismoSCRAM_SHA512 SASL. Este método usa el nombre de usuario y la contraseña almacenados en AWS Secrets Manager. Para obtener más información, consulte la sección Configuración de SASLen la documentación de Apache Kafka. -
SSL: la autenticación SSL utiliza archivos del almacén de claves y el almacén de confianza para conectarse con el clúster de Apache Kafka. Debe generar los archivos del almacén de confianza y el almacén de claves, cargarlos en un bucket de Amazon S3 y proporcionar la referencia a Amazon S3 cuando implemente el conector. El almacén de claves, el almacén de confianza y la clave SSL se almacenan en el AWS Secrets Manager. El cliente debe proporcionar la clave secreta de AWS cuando se implemente el conector. Para obtener más información, consulte Cifrado y autenticación mediante SSLL
en la documentación de Apache Kafka. Para obtener más información, consulte Configuración de la autenticación del conector Kafka de Athena.
-
-
certificates_s3_reference: la ubicación de Amazon S3 que contiene los certificados (los archivos del almacén de claves y del almacén de confianza).
-
disable_spill_encryption: (opcional) cuando se establece en
True, desactiva el cifrado del vertido. El valor predeterminado esFalse, de modo que los datos que se vierten a S3 se cifran mediante AES-GCM, ya sea mediante una clave generada aleatoriamente o KMS para generar claves. La desactivación del cifrado de vertido puede mejorar el rendimiento, especialmente si su ubicación de vertido usa cifrado del servidor. -
kafka_endpoint: los detalles del punto de conexión que se van a proporcionar a Kafka.
-
schema_registry_url: la dirección URL del registro de esquemas (por ejemplo,
http://schema-registry.example.org:8081). Se aplica a los formatos de datosAVROyPROTOBUF. Athena solo admite el registro de esquemas de Confluent. -
secrets_manager_secret: el nombre del secreto de AWS en el que se guardan las credenciales.
-
Parámetros de vertido: las funciones de Lambda almacenan (“vierten”) temporalmente los datos que no caben en la memoria de Amazon S3. Todas las instancias de bases de datos a las que se accede mediante la misma función de Lambda se vierten en la misma ubicación. Use los parámetros de la siguiente tabla para especificar la ubicación de vertido.
Parámetro Descripción spill_bucketObligatorio. El nombre del bucket de Amazon S3 en el que la función de Lambda puede verter datos. spill_prefixObligatorio. El prefijo del bucket de vertido donde la función de Lambda puede verter datos. spill_put_request_headers(Opcional) Un mapa codificado en JSON de encabezados y valores de solicitudes para la solicitud putObjectde Amazon S3 que se usa para el vertido (por ejemplo,{"x-amz-server-side-encryption" : "AES256"}). Para ver otros encabezados posibles, consulte PutObject en la referencia de la API de Amazon Simple Storage Service. -
ID de subred: uno o más ID de subred correspondientes a la subred que la función de Lambda puede usar para acceder al origen de datos.
-
Clúster público de Kafka o clúster de Confluent Cloud estándar: asocie el conector a una subred privada que tenga una puerta de enlace NAT.
-
Clúster de Confluent Cloud con conectividad privada: asocie el conector a una subred privada que tenga una ruta al clúster de Confluent Cloud.
-
En el caso de AWS Transit Gateway
, las subredes deben estar en una VPC conectada a la misma puerta de enlace de tránsito que utiliza Confluent Cloud. -
Para el emparejamiento de VPC
, las subredes deben estar en una VPC que esté sincronizada con la VPC de Confluent Cloud. -
Para AWS PrivateLink
, las subredes deben estar en una VPC que tenga una ruta a los puntos de conexión de VPC que se conectan a Confluent Cloud.
-
-
nota
Si se implementa el conector en una VPC con el fin de acceder a recursos privados y también se desea conectar a un servicio de acceso público como Confluent, se debe asociar el conector a una subred privada que tenga una puerta de enlace NAT. Para obtener más información, consulte Puerta de enlace NAT en la Guía del usuario de Amazon VPC.
Compatibilidad con tipos de datos
En la siguiente tabla, se muestran los tipos de datos correspondientes compatibles con Kafka y Apache Arrow.
| Kafka | Arrow |
|---|---|
| CHAR | VARCHAR |
| VARCHAR | VARCHAR |
| TIMESTAMP | MILLISECOND |
| DATE | DAY |
| BOOLEAN | BOOL |
| SMALLINT | SMALLINT |
| INTEGER | INT |
| BIGINT | BIGINT |
| DECIMAL | FLOAT8 |
| DOBLE | FLOAT8 |
Particiones y divisiones
Los temas de Kafka se dividen en particiones. Cada partición está ordenada. Cada mensaje de una partición tiene un ID incremental denominado desplazamiento. Cada partición de Kafka se divide a su vez en múltiples divisiones para su procesamiento en paralelo. Los datos están disponibles durante el periodo de retención configurado en los clústeres de Kafka.
Prácticas recomendadas
Como práctica recomendada, use la inserción de predicados cuando realice consultas en Athena, como en los siguientes ejemplos.
SELECT * FROM "kafka_catalog_name"."glue_schema_registry_name"."glue_schema_name" WHERE integercol = 2147483647
SELECT * FROM "kafka_catalog_name"."glue_schema_registry_name"."glue_schema_name" WHERE timestampcol >= TIMESTAMP '2018-03-25 07:30:58.878'
Configuración del conector Kafka
Antes de poder usar el conector, debe configurar el clúster de Apache Kafka, usar AWS Glue Schema Registry para definir el esquema y configurar la autenticación del conector.
Cuando trabaje con AWS Glue Schema Registry, tenga en cuenta los siguientes puntos:
-
Asegúrese de que el texto del campo Description (Descripción) de AWS Glue Schema Registry incluya la cadena
{AthenaFederationKafka}. Esta cadena de marcadores es obligatoria para los registros de AWS Glue que use con el conector Kafka de Amazon Athena. -
Para obtener el mejor rendimiento, use solo minúsculas en los nombres de las bases de datos y tablas. El uso combinado de mayúsculas y minúsculas hace que el conector realice una búsqueda que no distinga mayúsculas de minúsculas, lo que requiere un mayor esfuerzo computacional.
Para configurar el entorno de Apache Kafka y AWS Glue Schema Registry
-
Configure su entorno de Apache Kafka.
-
Cargue el archivo de descripción del tema de Kafka (es decir, su esquema) en formato JSON en AWS Glue Schema Registry. Para obtener más información, consulte Integración con AWS Glue Schema Registry en la Guía para desarrolladores de AWS Glue.
-
Para utilizar el formato de datos de
AVROoPROTOBUFal definir el esquema en el registro de esquemas AWS Glue:-
Para el nombre del esquema, introduzca el nombre del tema de Kafka con las mayúsculas y minúsculas que utiliza el original.
-
Para el formato de datos, elija Apache Avro o búferes de protocolo.
Para obtener más esquemas de ejemplo, consulte la siguiente sección.
-
Use el formato de los ejemplos de esta sección cuando cargue el esquema en AWS Glue Schema Registry.
Ejemplo de esquema de tipo JSON
En el siguiente ejemplo, el esquema que se va a crear en AWS Glue Schema Registry especifica json como el valor de dataFormat y usa datatypejson para topicName.
nota
El valor de topicName debe usar la misma distinción entre mayúsculas y minúsculas que el nombre del tema en Kafka.
{ "topicName": "datatypejson", "message": { "dataFormat": "json", "fields": [ { "name": "intcol", "mapping": "intcol", "type": "INTEGER" }, { "name": "varcharcol", "mapping": "varcharcol", "type": "VARCHAR" }, { "name": "booleancol", "mapping": "booleancol", "type": "BOOLEAN" }, { "name": "bigintcol", "mapping": "bigintcol", "type": "BIGINT" }, { "name": "doublecol", "mapping": "doublecol", "type": "DOUBLE" }, { "name": "smallintcol", "mapping": "smallintcol", "type": "SMALLINT" }, { "name": "tinyintcol", "mapping": "tinyintcol", "type": "TINYINT" }, { "name": "datecol", "mapping": "datecol", "type": "DATE", "formatHint": "yyyy-MM-dd" }, { "name": "timestampcol", "mapping": "timestampcol", "type": "TIMESTAMP", "formatHint": "yyyy-MM-dd HH:mm:ss.SSS" } ] } }
Ejemplo de esquema de tipo CSV
En el siguiente ejemplo, el esquema que se va a crear en AWS Glue Schema Registry especifica csv como el valor de dataFormat y usa datatypecsvbulk para topicName. El valor de topicName debe usar la misma distinción entre mayúsculas y minúsculas que el nombre del tema en Kafka.
{ "topicName": "datatypecsvbulk", "message": { "dataFormat": "csv", "fields": [ { "name": "intcol", "type": "INTEGER", "mapping": "0" }, { "name": "varcharcol", "type": "VARCHAR", "mapping": "1" }, { "name": "booleancol", "type": "BOOLEAN", "mapping": "2" }, { "name": "bigintcol", "type": "BIGINT", "mapping": "3" }, { "name": "doublecol", "type": "DOUBLE", "mapping": "4" }, { "name": "smallintcol", "type": "SMALLINT", "mapping": "5" }, { "name": "tinyintcol", "type": "TINYINT", "mapping": "6" }, { "name": "floatcol", "type": "DOUBLE", "mapping": "7" } ] } }
Ejemplo de esquema de tipo AVRO
El siguiente ejemplo se utiliza para crear un esquema basado en AVRO en el registro de esquemas de AWS Glue. Al definir el esquema en el registro de esquemas de AWS Glue, para el nombre del esquema, se escribe el nombre del tema de Kafka con las mayúsculas y minúsculas que utiliza el original, y para el formato de datos, se elige Apache Avro. Como esta información se especifica directamente en el registro, los campos dataformat y topicName no son obligatorios.
{ "type": "record", "name": "avrotest", "namespace": "example.com", "fields": [{ "name": "id", "type": "int" }, { "name": "name", "type": "string" } ] }
Ejemplo de esquema de tipo PROTOBUF
El siguiente ejemplo se utiliza para crear un esquema basado en PROTOBUF en el registro de esquemas de AWS Glue. Al definir el esquema en el registro de esquemas de AWS Glue, para el nombre del esquema, se escribe el nombre del tema de Kafka con las mayúsculas y minúsculas que utiliza el original, y para el formato de datos, se elige búferes de protocolo. Como esta información se especifica directamente en el registro, los campos dataformat y topicName no son obligatorios. La primera línea define el esquema como PROTOBUF.
syntax = "proto3"; message protobuftest { string name = 1; int64 calories = 2; string colour = 3; }
Para obtener más información sobre cómo agregar un registro y esquemas al Registro de esquemas de AWS Glue, consulte Introducción al Registro de esquemas en la documentación de AWS Glue.
Configuración de la autenticación del conector Kafka de Athena
Puede usar diversos métodos para autenticarse en su clúster de Apache Kafka, entre los que se incluyen SSL, SASL/SCRAM, SASL/PLAIN y SASL/PLAINTEXT.
En la siguiente tabla, se muestran los tipos de autenticación del conector, el protocolo de seguridad y el mecanismo SASL de cada uno. Para obtener más información, consulte la sección Seguridad
| auth_type | security.protocol | sasl.mechanism | Compatibilidad de tipos de clúster |
|---|---|---|---|
SASL_SSL_PLAIN |
SASL_SSL |
PLAIN |
|
SASL_PLAINTEXT_PLAIN |
SASL_PLAINTEXT |
PLAIN |
|
SASL_SSL_SCRAM_SHA512 |
SASL_SSL |
SCRAM-SHA-512 |
|
SASL_PLAINTEXT_SCRAM_SHA512 |
SASL_PLAINTEXT |
SCRAM-SHA-512 |
|
SSL |
SSL |
N/A |
|
SSL
Si el clúster se ha autenticado con SSL, debe generar los archivos del almacén de confianza y del almacén de claves y cargarlos en el bucket de Amazon S3. Debe proporcionar esta referencia de Amazon S3 al implementar el conector. El almacén de claves, el almacén de confianza y la clave SSL se almacenan en el AWS Secrets Manager. Debe proporcionar la clave secreta de AWS al implementar el conector.
Para obtener información sobre cómo crear un secreto en Secrets Manager, consulte Creación de un secreto de AWS Secrets Manager.
Para usar este tipo de autenticación, establezca las variables de entorno como se muestra en la siguiente tabla.
| Parámetro | Valor |
|---|---|
auth_type |
SSL |
certificates_s3_reference |
La ubicación de Amazon S3 que contiene los certificados. |
secrets_manager_secret |
El nombre de su clave secreta de AWS. |
Después de crear un secreto en Secrets Manager, puede verlo en la consola de Secrets Manager.
Para ver el secreto en Secrets Manager
Abra la consola de Secrets Manager en https://console.aws.amazon.com/secretsmanager/
. -
En el panel de navegación, elija Secretos.
-
En la página Secretos, elija el vínculo al secreto.
-
En la página de detalles del secreto, elija Retrieve secret value (Recuperar valor del secreto).
La siguiente imagen muestra un secreto de ejemplo con tres pares de clave y valor:
keystore_password,truststore_passwordyssl_key_password.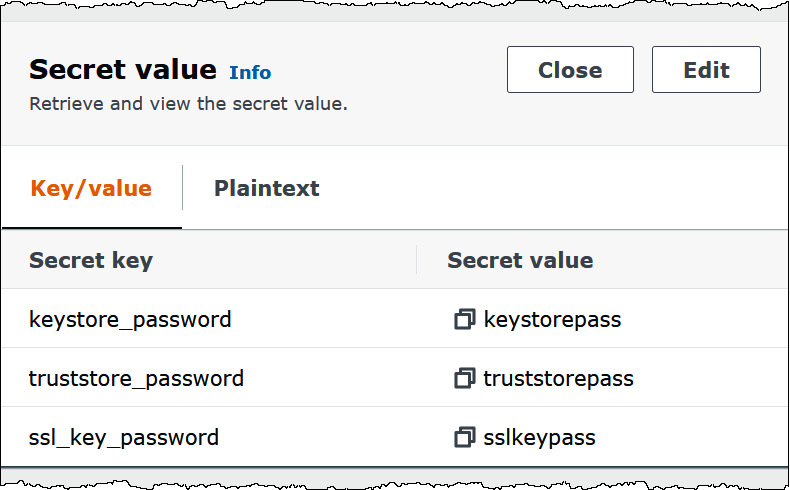
Para obtener más información sobre cómo usar SSL con Kafka, consulte Cifrado y autenticación mediante SSL
SASL/SCRAM
Si su clúster usa la autenticación con SCRAM, proporcione la clave de Secrets Manager que está asociada al clúster cuando implemente el conector. Las credenciales de AWS del usuario (clave secreta y clave de acceso) se usan para autenticarse en el clúster.
Establezca las variables de entorno como se muestra en la siguiente tabla.
| Parámetro | Valor |
|---|---|
auth_type |
SASL_SSL_SCRAM_SHA512 |
secrets_manager_secret |
El nombre de su clave secreta de AWS. |
La siguiente imagen muestra un secreto de ejemplo en la consola de Secrets Manager con dos pares de clave y valor: uno para username y otro para password.
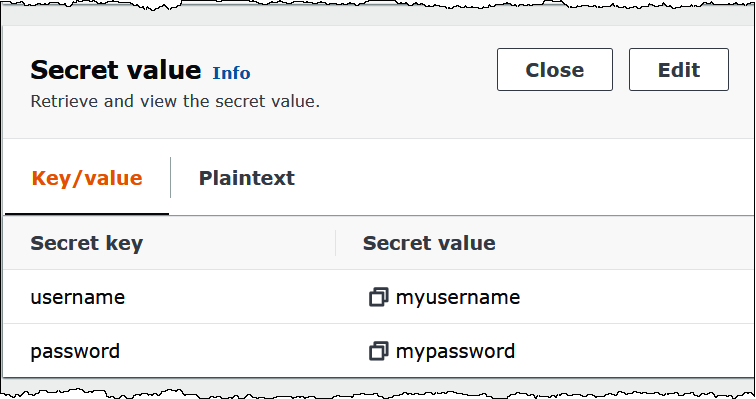
Para obtener más información sobre cómo usar SASL/SCRAM con Kafka, consulte Autenticación mediante SASL/SCRAM
Información sobre licencias
Al usar este conector, reconoce la inclusión de componentes de terceros, cuya lista se puede encontrar en el archivo pom.xml
Recursos adicionales
Para obtener más información acerca de este conector, consulte el sitio correspondiente
