Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Migración a Amazon DocumentDB
Amazon DocumentDB (con compatibilidad con MongoDB) es un servicio de base de datos totalmente administrado compatible con la API de MongoDB. Puede migrar sus datos a Amazon DocumentDB desde bases de datos de MongoDB que se ejecuten en las instalaciones o en Amazon Elastic Compute Cloud (Amazon EC2) utilizando el proceso que se detalla en esta sección.
Temas
- Actualización del clúster de Amazon DocumentDB mediante AWS Database Migration Service
- Herramientas de migración
- Discovery
- Planificación: requisitos de clúster de Amazon DocumentDB
- Enfoques de migración
- Orígenes de migración
- Conectividad de la migración
- Pruebas
- Pruebas de rendimiento
- Prueba de conmutación por error
- Recursos adicionales
- Guía de migración: MongoDB a Amazon DocumentDB
Herramientas de migración
Para migrar a Amazon DocumentDB, las dos herramientas principales que la mayoría de los clientes utilizan son AWS Database Migration Service (AWS DMS)mongodump y mongorestore. Como práctica recomendada, y para cualquiera de estas opciones, recomendamos que primero cree índices en Amazon DocumentDB antes de comenzar la migración ya que puede reducir el tiempo general y aumentar la velocidad de la migración. Para hacer esto, puede usar la Herramienta de índice de Amazon DocumentDB
AWS Database Migration Service
AWS Database Migration Service (AWS DMS) es un servicio en la nube que facilita la migración de bases de datos relacionales y no relacionales a Amazon DocumentDB. Puede utilizarlos AWS DMS para migrar sus datos a Amazon DocumentDB desde bases de datos alojadas en las instalaciones o en EC2. Con AWS DMSél, puede realizar migraciones únicas o replicar los cambios en curso para mantener sincronizados los orígenes y los destinos.
Para obtener más información sobre cómo AWS DMS migrar a Amazon DocumentDB, consulte:
Utilidades de la línea de comandos
Las utilidades comunes para migrar datos desde y hacia Amazon DocumentDB incluyen mongodump, mongorestore, mongoexport, y mongoimport. Normalmente, mongodump y mongorestore son las utilidades más eficientes ya que vuelcan y restauran datos de las bases de datos en un formato binario. Esta es generalmente la opción de mayor rendimiento y produce un tamaño de datos más pequeño en comparación con las exportaciones lógicas. mongoexport y mongoimport son útiles si desea exportar e importar datos en un formato lógico como JSON o CSV ya que los datos son legibles por humanos, pero generalmente son más lentos que mongodump/mongorestore y producen un tamaño de datos mayor.
Enfoques de migraciónEn la siguiente sección se explica cuándo es mejor utilizar las utilidades de línea de comandos AWS DMS y las utilidades de línea de comandos en función de su caso de uso y sus requisitos.
Discovery
En cada una de las implementaciones de MongoDB, debe identificar y registrar dos conjuntos de datos: los detalles de la arquitectura y las características operativas. Esta información le ayudará a elegir el enfoque de migración adecuado y el tamaño de los clústeres.
Detalles de la arquitectura
-
Nombre
Elija un nombre único para realizar el seguimiento de esta implementación.
-
Versión
Registre la versión de MongoDB en la que se ejecuta su implementación. Para encontrar la versión, conéctese a un miembro del conjunto de réplicas con el intérprete de comandos de mongo y ejecute la operación
db.version(). -
Tipo
Registre si su implementación es una instancia de mongo independiente, un conjunto de réplicas o un clúster fragmentado.
-
Miembros
Registre los nombres de host, direcciones y puertos de cada clúster, conjunto de réplicas o miembro independiente.
En una implementación en clúster, puede encontrar los miembros de la partición conectándose a un host con el intérprete de comandos de mongo y ejecutando la operación
sh.status().En un conjunto de réplicas, para obtener los miembros, conéctese a un miembro del conjunto de réplicas con el intérprete de comandos de mongo y ejecute la operación
rs.status(). -
Tamaños de oplog
En conjuntos de réplicas o clústeres fragmentados, registre el tamaño del oplog para cada miembro del conjunto de réplicas. Para encontrar el tamaño de oplog de un miembro, conéctese al miembro del conjunto de réplicas con el intérprete de comandos de mongo y ejecute la operación
ps.printReplicationInfo(). -
Prioridades de los miembros del conjunto de réplicas
En conjuntos de réplicas o clústeres fragmentados, registre la prioridad para cada miembro del conjunto de réplicas. Para encontrar las prioridades de los miembros del conjunto de réplicas, conéctese a un miembro del conjunto de réplicas con el intérprete de comandos de mongo y ejecute la operación
rs.conf(). La prioridad es el valor de la clavepriority. -
Uso de TLS/SSL
Registre si se utiliza el protocolo Seguridad de la capa de transporte (TLS)/Capa de enlace segura (SSL) en cada nodo para realizar el cifrado en tránsito.
Características operativas
-
Estadísticas de la base de datos
Registre la siguiente información para cada colección:
-
Nombre
-
Tamaño de los datos
-
Número de colecciones
Para ver las estadísticas de la base de datos, conéctese a la base de datos con el intérprete de comandos de mongo y ejecute el comando
db.runCommand({dbstats: 1}). -
-
Estadísticas de la colección
Registre la siguiente información para cada colección:
-
Espacio de nombres
-
Tamaño de los datos
-
Número de índices
-
Si la colección está limitada
-
-
Estadísticas de índices
Registre la siguiente información de los índices para cada colección:
-
Espacio de nombres
-
ID
-
Tamaño
-
Claves
-
TTL
-
Sparse
-
Introducción
Para encontrar la información de los índices, conéctese a la base de datos con el intérprete de comandos de mongo y ejecute el comando
db.collection.getIndexes(). -
-
Opcounters
Esta información le ayuda a conocer los patrones de las cargas de trabajo actuales de MongoDB (uso intensivo de lecturas, uso intensivo de escrituras o uso equilibrado de ambas). También proporciona orientación sobre su selección inicial de instancias de Amazon DocumentDB.
Estos son los elementos de información clave que se deben recopilar durante el periodo de monitorización (en número/segundo):
-
Consultas
-
Inserciones
-
Actualizaciones
-
Eliminaciones
Puede obtener esta información realizando una representación gráfica de la salida del comando
db.serverStatus()a lo largo del tiempo. También puede utilizar la herramienta mongostat para obtener valores instantáneos para estas estadísticas. Sin embargo, con esta opción, corre el riesgo de planificar la migración en periodos de uso que no se corresponden con el pico de carga. -
-
Estadísticas de la red
Esta información le ayuda a conocer los patrones de las cargas de trabajo actuales de MongoDB (uso intensivo de lecturas, uso intensivo de escrituras o uso equilibrado de ambas). También proporciona orientación sobre su selección inicial de instancias de Amazon DocumentDB.
Estos son los elementos de información clave que se deben recopilar durante el periodo de monitorización (en número/segundo):
-
Conexiones
-
Bytes recibidos por la red
-
Bytes enviados por la red
Puede obtener esta información realizando una representación gráfica de la salida del comando
db.serverStatus()a lo largo del tiempo. También puede utilizar la herramienta mongostat para obtener valores instantáneos para estas estadísticas. Sin embargo, con esta opción, corre el riesgo de planificar la migración en periodos de uso que no se corresponden con el pico de carga. -
Planificación: requisitos de clúster de Amazon DocumentDB
Para realizar una migración correctamente, es necesario pensar cuidadosamente en la configuración de los clústeres de Amazon DocumentDB y en cómo obtendrán acceso las aplicaciones al clúster. Piense en cada una de las siguientes dimensiones a la hora de determinar los requisitos de los clústeres:
-
Disponibilidad.
Amazon DocumentDB proporciona alta disponibilidad mediante la implementación de instancias de réplicas, que se pueden promover a una instancia principal en un proceso que se conoce como conmutación por error. Puede lograr mayores niveles de disponibilidad mediante la implementación de instancias de réplicas en diferentes zonas de disponibilidad.
En la siguiente tabla, se proporcionan directrices para que las configuraciones de las implementaciones de Amazon DocumentDB cumplan objetivos de disponibilidad específicos.
Objetivo de disponibilidad Total de instancias Réplicas Zonas de disponibilidad 99% 1 0 1 99,9% 2 1 2 99,99% 3 2 3 En la fiabilidad general del sistema, se deben tener en cuenta todos los componentes, no solo la base de datos. Para conocer las mejores prácticas y recomendaciones para satisfacer las necesidades generales de fiabilidad del sistema, consulte el AWS documento técnico Well-Architected Reliability Pillar
. -
Rendimiento
Las instancias de Amazon DocumentDB le permiten leer y escribir en el volumen de almacenamiento del clúster. Hay instancias de clústeres de diversos tipos, con diferentes capacidades de memoria y vCPU, que afectan al rendimiento de lectura y escritura del clúster. Con la información que ha recopilado en la fase de detección, elija un tipo de instancia que admita los requisitos de rendimiento de su carga de trabajo. Para ver una lista de los tipos de instancia admitidos, consulte Administración de clases de instancias.
Cuando elija un tipo de instancia para el clúster de Amazon DocumentDB, tenga en cuenta los siguientes aspectos de los requisitos de rendimiento de su carga de trabajo:
-
vCPU: las arquitecturas que requieren un mayor número de conexiones podrían beneficiarse de las instancias con más vCPU.
-
Memoria: cuando sea posible, mantener el conjunto de datos de trabajo en la memoria proporciona el máximo rendimiento. Como pauta inicial, reserve un tercio de la memoria de la instancia para el motor de Amazon DocumentDB y deje dos tercios para el conjunto de datos en funcionamiento.
-
Conexiones: el recuento mínimo de conexiones óptimo es de ocho conexiones por vCPU de instancia de Amazon DocumentDB. Aunque el límite de conexiones de instancias de Amazon DocumentDB es mucho mayor, las ventajas para el rendimiento de las conexiones adicionales se reducen por encima de ocho conexiones por vCPU.
-
Red: las cargas de trabajo con una gran cantidad de clientes o conexiones deben tener en cuenta el rendimiento total de la red necesario para insertar y recuperar los datos. Las operaciones en bloque pueden utilizar los recursos de red de una forma más eficiente.
-
Rendimiento de inserción: las inserciones de un solo documento suelen ser la forma más lenta de insertar datos en Amazon DocumentDB. Las operaciones de inserción en bloque pueden ser muchísimo más rápidas que las inserciones individuales.
-
Rendimiento de lectura: las lecturas de la memoria de trabajo siempre son más rápidas que las devueltas desde el volumen de almacenamiento. Por lo tanto, es ideal optimizar el tamaño de la memoria de instancias para conservar el conjunto en funcionamiento en la memoria.
Además de servir lecturas desde la instancia principal, los clústeres de Amazon DocumentDB se configuran automáticamente como conjuntos de réplicas. A continuación, puede dirigir las consultas de solo lectura a réplicas de lectura configurando la preferencia de lectura en el controlador de MongoDB. Para escalar el tráfico de lectura, añada réplicas y reduzca la carga general en la instancia principal.
Es posible implementar réplicas de Amazon DocumentDB de diferentes tipos de instancias en el mismo clúster. Un caso de uso de ejemplo podría ser mantener una réplica con un tipo de instancia de mayor tamaño que se encargue del tráfico de análisis temporal. Si implementa un conjunto mixto de tipos de instancias, asegúrese de configurar la prioridad de conmutación por error de cada instancia. Esto ayuda a asegurarse de que un evento de conmutación por error siempre promueve una réplica de tamaño suficiente para gestionar la carga de escritura.
-
-
Recuperación
Amazon DocumentDB realiza copias de seguridad continuas de los datos mientras se escriben. Proporciona capacidades de point-in-time recuperación (PITR) en un período configurable de 1 a 35 días, conocido como período de retención de copias de seguridad. El período predeterminado de retención de copia de seguridad es de un día. Amazon DocumentDB también crea automáticamente instantáneas diarias del volumen de almacenamiento, que también se conservan durante el periodo de retención de copia de seguridad configurado.
Si desea conservar las instantáneas más allá del período de retención de la copia de seguridad, también puede iniciar las instantáneas manuales en cualquier momento utilizando las AWS Management Console teclas y (). AWS Command Line Interface AWS CLI Para obtener más información, consulte Backing Up and Restoring in Amazon DocumentDB.
Tenga en cuenta lo siguiente a la hora de planificar la migración:
-
Elija un periodo de retención de copia de seguridad de 1-35 días que cumpla su objetivo de punto de recuperación (RPO).
-
Decida si necesita instantáneas manuales y, en tal caso, a qué intervalo.
-
Enfoques de migración
Existen tres enfoques principales para migrar datos a Amazon DocumentDB.
nota
Aunque es posible crear los índices en cualquier momento en Amazon DocumentDB, en general es más rápido crearlos antes de importar conjuntos de datos de gran tamaño. Como práctica recomendada, recomendamos que, para cada uno de los enfoques siguientes, primero cree los índices en Amazon DocumentDB antes de realizar la migración. Para hacer esto, puede usar la Herramienta de índice de Amazon DocumentDB
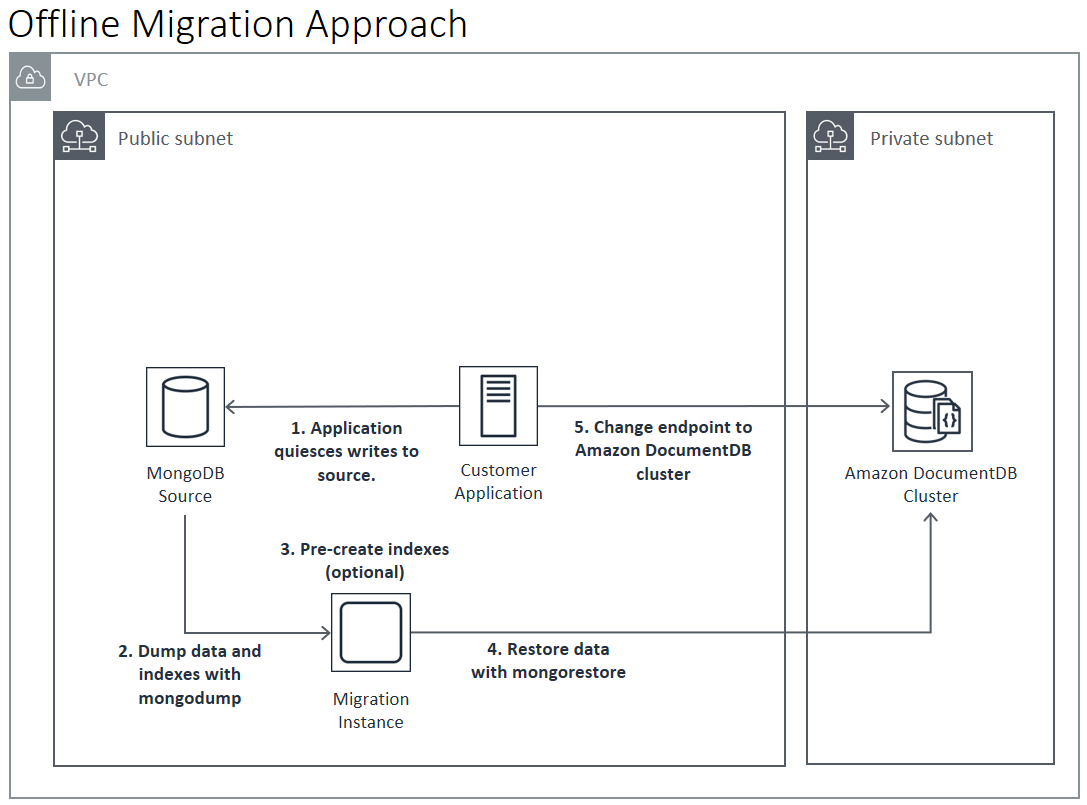
Sin conexión
El enfoque sin conexión utiliza mongodump y mongorestore las herramientas para migrar los datos desde la implementación de origen de MongoDB al clúster de Amazon DocumentDB. El método sin conexión es el enfoque de migración más sencillo, pero también el que produce un tiempo de inactividad más largo en el clúster.
El proceso básico para la migración sin conexión es el siguiente:
-
Desactivar la escritura en el origen de MongoDB.
-
Volcar los datos de la colección y los índices desde la implementación de origen de MongoDB.
-
Si va a migrar a un clúster elástico, cree sus colecciones con particiones mediante el comando
sh.shardCollection(). Si va a realizar la migración a un clúster basado en instancias, vaya al paso siguiente. -
Restaure los índices en el clúster de Amazon DocumentDB.
-
Restaurar los datos de la colección en el clúster de Amazon DocumentDB.
-
Cambiar el punto de conexión de la aplicación para que escriba en el clúster de Amazon DocumentDB .
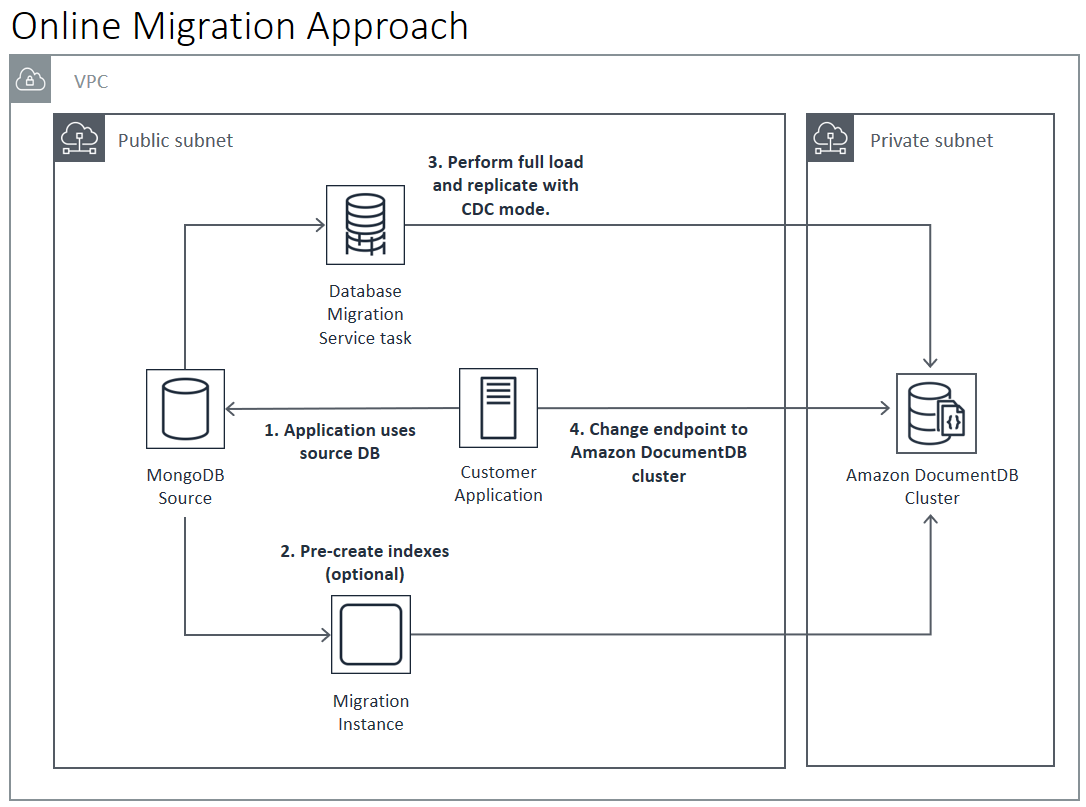
Online
El enfoque online utiliza AWS Database Migration Service (AWS DMS). Realiza una carga completa de los datos desde la implementación de origen de MongoDB al clúster de Amazon DocumentDB. A continuación, cambia al modo de captura de datos de cambios (CDC) para replicar los cambios. El enfoque online minimiza el tiempo de inactividad del clúster, pero es el más lento de los tres métodos.
El proceso básico para la migración online es el siguiente:
-
La aplicación utiliza la base de datos de origen normalmente.
-
Si va a migrar a un clúster elástico, cree sus colecciones con particiones mediante el comando
sh.shardCollection(). Si va a realizar la migración a un clúster basado en instancias, vaya al paso siguiente. -
Cree previamente índices en el clúster de Amazon DocumentDB.
-
Cree una AWS DMS tarea para realizar una carga completa y, a continuación, habilite CDC desde la implementación de MongoDB de origen hasta el clúster de Amazon DocumentDB.
-
Cuando la AWS DMS tarea haya completado una carga completa y esté replicando los cambios en Amazon DocumentDB, cambie el punto final de la aplicación al clúster de Amazon DocumentDB.
Para obtener más información sobre cómo AWS DMS migrar, consulte Uso de Amazon DocumentDB como destino AWS Database Migration Service y el tutorial relacionado en la Guía del AWS Database Migration Service usuario.
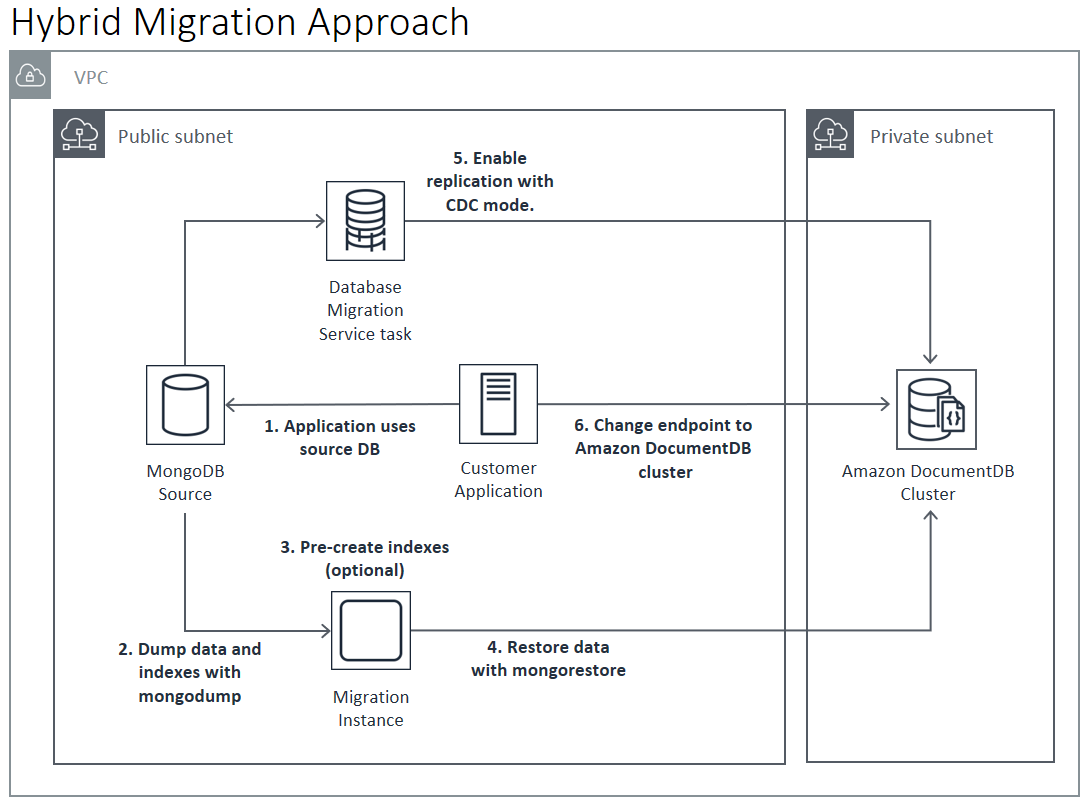
Híbrido
El enfoque híbrido utiliza las herramientas mongodump y mongorestore para migrar los datos desde la implementación de origen de MongoDB al clúster de Amazon DocumentDB. A continuación, se utiliza AWS DMS en modo CDC para replicar los cambios. El enfoque híbrido consigue una velocidad de migración y un tiempo de inactividad intermedios, pero es el más complejo de los tres enfoques.
El proceso básico para la migración híbrida es el siguiente:
-
La aplicación utiliza la implementación de origen de MongoDB normalmente.
-
Volcar los datos de la colección y los índices desde la implementación de origen de MongoDB.
-
Restaure los índices en el clúster de Amazon DocumentDB.
-
Si va a migrar a un clúster elástico, cree sus colecciones con particiones mediante el comando
sh.shardCollection(). Si va a realizar la migración a un clúster basado en instancias, vaya al paso siguiente. -
Restaurar los datos de la colección en el clúster de Amazon DocumentDB.
-
Cree una AWS DMS tarea para habilitar CDC desde la implementación de MongoDB de origen hasta el clúster de Amazon DocumentDB.
-
Cuando la AWS DMS tarea esté replicando los cambios dentro de un período aceptable, cambie el punto de enlace de la aplicación para escribir en el clúster de Amazon DocumentDB.
importante
Actualmente, una AWS DMS tarea solo puede migrar una única base de datos. Si el origen de MongoDB tiene un gran número de bases de datos, es posible que tenga que automatizar la creación de la tarea de migración o pensar en la posibilidad de utilizar el método sin enlace.
Independientemente del enfoque de migración que elija, lo más eficiente es crear previamente los índices en el clúster de Amazon DocumentDB antes de la migración de los datos. Esto se debe a que los índices de Amazon DocumentDB son datos insertados en paralelo, pero la creación de un índice en datos existentes es una operación con un solo subproceso.
Como AWS DMS no migra los índices (solo sus datos), no es necesario realizar ningún paso adicional para evitar crear índices por segunda vez.
Orígenes de migración
Si el origen de MongoDB es un proceso de mongo independiente y desea utilizar los enfoques de migración híbrido u online, primero convierta el mongo independiente en un conjunto de réplicas para crear el oplog y utilizarlo como origen de CDC.
Si va a realizar la migración desde un conjunto de réplicas de MongoDB o un clúster fragmentado, piense en la posibilidad de crear un secundario encadenado u oculto para cada conjunto de réplicas o fragmento para utilizarlo como origen de la migración. Los volcados de datos pueden obligar a sacar de la memoria los datos del conjunto en funcionamiento y eso afecta al rendimiento en las instancias de producción. Para reducir este riesgo, realice la migración desde un nodo que no sirva datos de producción.
Versiones de origen de la migración
Si su versión de la base de datos de MongoDB de origen es diferente a la versión de compatibilidad del clúster de Amazon DocumentDB de destino, es posible que tenga que realizar otros pasos de preparación para garantizar que la migración sea correcta. Los dos requisitos más comunes son la necesidad de actualizar la instalación de MongoDB de origen a una versión compatible para la migración (versión 3.0 o superior de MongoDB) y la actualización de los controladores de aplicaciones para admitir la versión de Amazon DocumentDB de destino.
Si su migración tiene alguno de estos requisitos, asegúrese de incluir estos pasos en el plan de migración para actualizar y probar cualquier cambio de controlador.
Conectividad de la migración
Puede realizar la migración a Amazon DocumentDB desde una implementación de MongoDB de origen que se ejecute en el centro de datos o desde una implementación de MongoDB que se ejecute en una instancia Amazon EC2. La migración desde MongoDB que se ejecuta en EC2 es sencilla y solo requiere configurar correctamente los grupos de seguridad y las subredes.
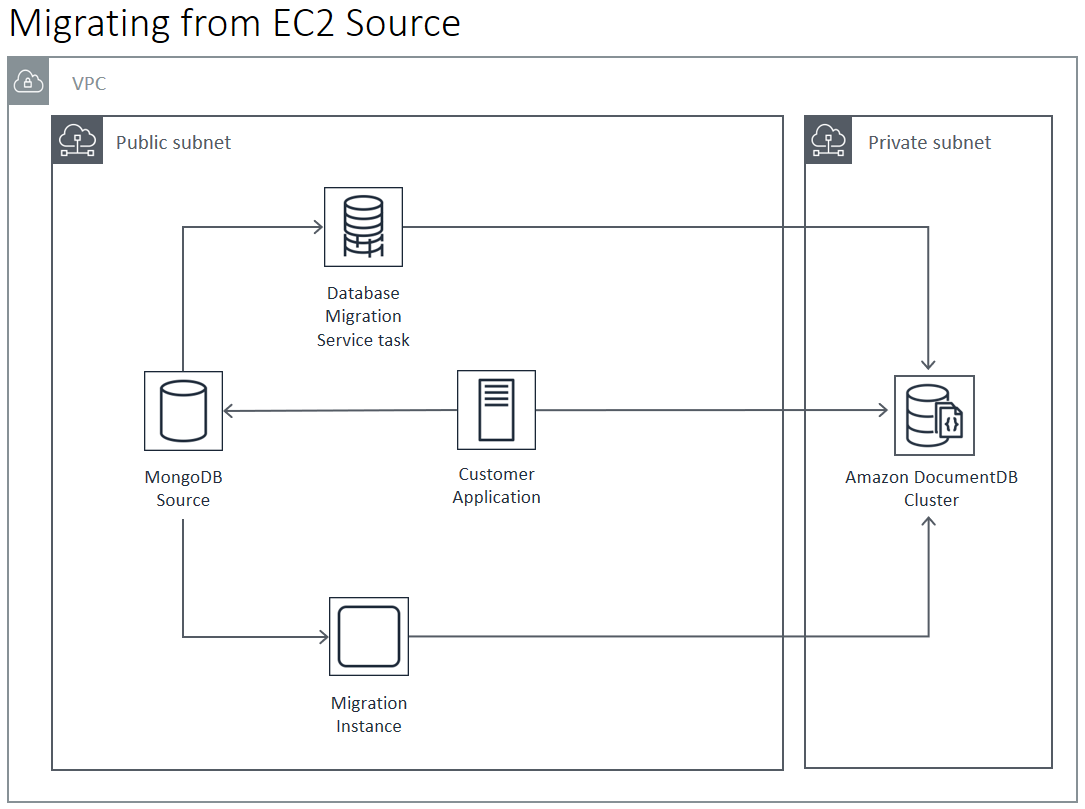
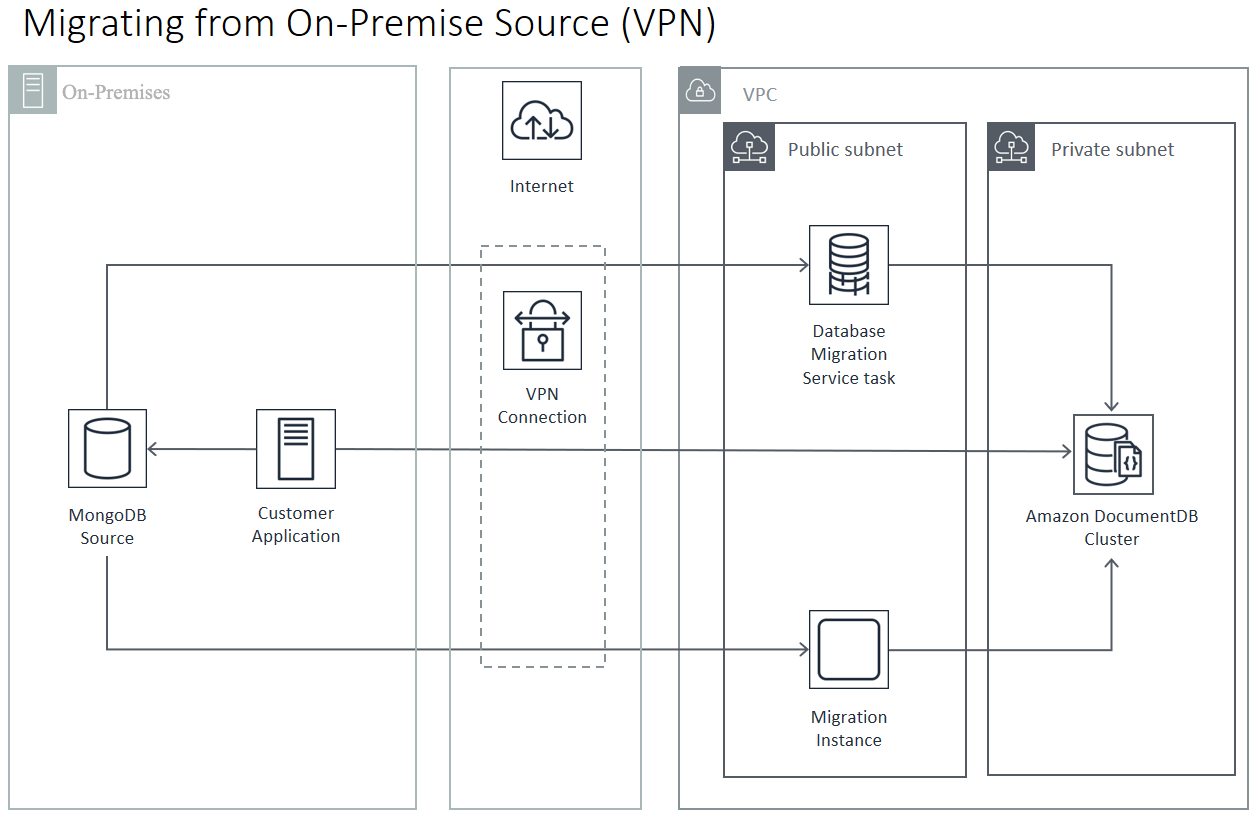
La migración desde una base de datos local requiere conectividad entre la implementación de MongoDB y la nube virtual privada (VPC). Puede hacerlo mediante una conexión de red privada virtual (VPN) o mediante el AWS Direct Connect servicio. Aunque puede realizar la migración a través de Internet a su VPC, este método de enlace es el menos conveniente desde el punto de vista de la seguridad.
El siguiente diagrama ilustra una migración a Amazon DocumentDB desde un origen en las instalaciones a través de una enlace de VPN.
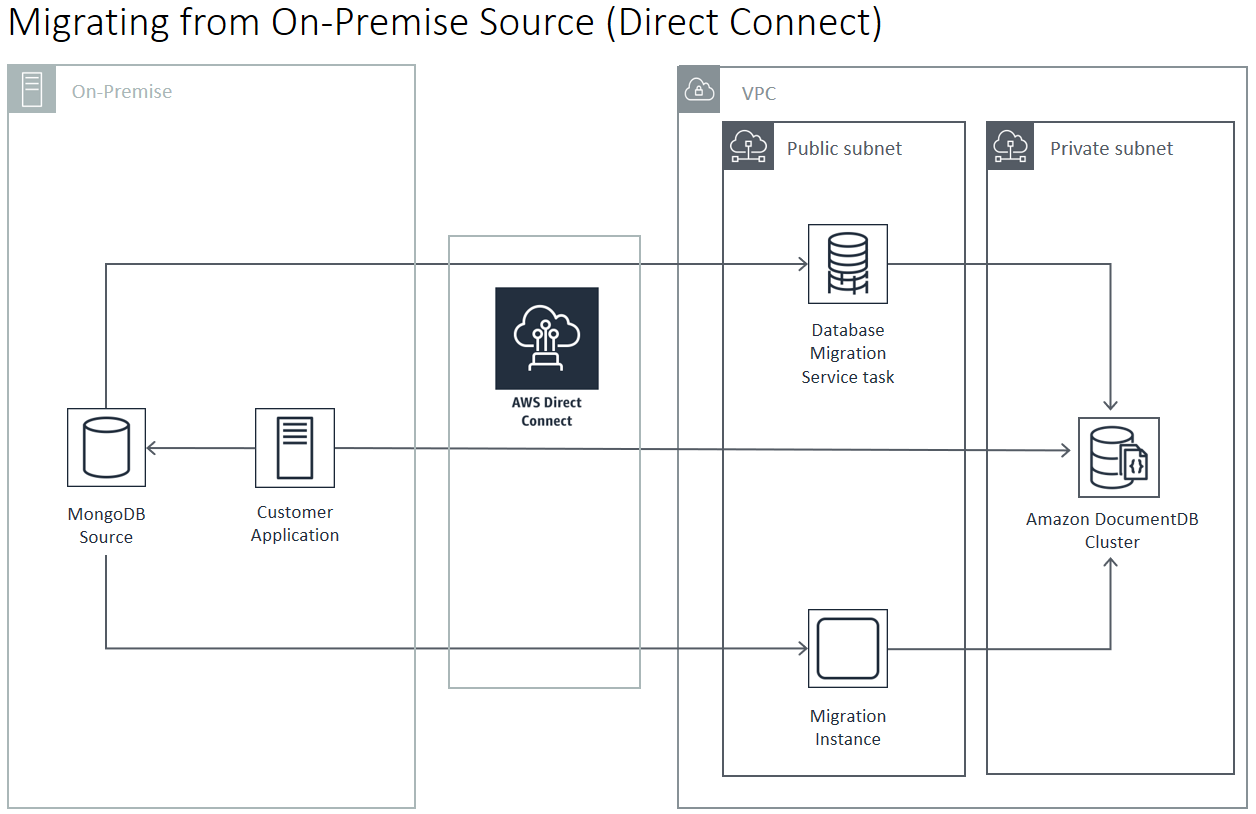
A continuación, vemos representada una migración a Amazon DocumentDB desde un origen en las instalaciones que utiliza AWS Direct Connect.
Los enfoques de migración online e híbrido requieren el uso de una instancia AWS DMS , que se debe ejecutar en Amazon EC2 en una Amazon VPC. Todos los enfoques requieren que un servidor de migración ejecute mongodump y mongorestore. Por lo general, es más fácil ejecutar el servidor de migración en una instancia Amazon EC2 de la VPC en la que se lanza el clúster de Amazon DocumentDB, ya que esto simplifica enormemente la conectividad al clúster de Amazon DocumentDB.
Pruebas
A continuación, se indican los objetivos de las pruebas previas a la migración:
-
Comprobar que el enfoque elegido logra el resultado de migración deseado.
-
Comprobar que el tipo de instancia y las opciones de preferencia de lectura se ajustan a los requisitos de rendimiento de su aplicación.
-
Comprobar el comportamiento de la aplicación durante la conmutación por error.
Aspectos a tener en cuenta en la prueba del plan de migración
Tenga en cuenta lo siguiente a la hora de probar el plan de migración a Amazon DocumentDB.
Temas
Restauración de índices
De forma predeterminada, mongorestore crea índices para colecciones volcadas, pero los crea una vez restaurados los datos. En general, es más rápido crear los índices en Amazon DocumentDB antes de que se restauren los datos en el clúster. Esto se debe a que las operaciones de indexación se paralelizan durante la carga de datos.
Si decide crear previamente los índices, puede omitir el paso de creación de índices al restaurar datos con mongorestore suministrando la opción -–noIndexRestore.
Volcado de datos
La herramienta mongodump es el método preferido para volcar datos desde la implementación de MongoDB de origen. En función de los recursos disponibles en la instancia de migración, es posible que pueda agilizar mongodump aumentando el número de conexiones en paralelo volcadas desde las 4 predeterminadas mediante la opción –-numParallelCollections.
Restauración de datos
La herramienta mongorestore es el método preferido para restaurar datos volcados en la instancia de Amazon DocumentDB. Para mejorar el rendimiento de la restauración, aumente el número de procesos de trabajo para cada colección durante la restauración con la opción -–numInsertionWorkersPerCollection. Para empezar, estaría bien utilizar un proceso de trabajo por vCPU en la instancia principal del clúster de Amazon DocumentDB.
Actualmente, Amazon DocumentDB no admite la opción mongorestore de la herramienta --oplogReplay.
De forma predeterminada, mongorestore omite los errores de inserción y continúa el proceso de restauración. Esto puede ocurrir si desea restaurar datos incompatibles en la instancia de Amazon DocumentDB. Por ejemplo, puede suceder si tiene un documento que contiene claves o valores con cadenas nulas. Si prefiere que la operación mongorestore falle por completo si se encuentra algún error de restauración, utilice la opción --stopOnError.
Tamaño de oplog
El registro de operaciones de MongoDB (oplog) es una colección limitada que contiene todas las modificaciones de datos que se han realizado en la base de datos. Puede ver el tamaño del oplog y el intervalo de tiempo que contiene mediante la ejecución de la operación db.printReplicationInfo() en un conjunto de réplicas o un miembro del fragmento.
Si utiliza los enfoques en línea o híbridos, asegúrese de que el registro de registro de cada conjunto de réplicas o fragmento sea lo suficientemente grande como para contener todos los cambios realizados durante todo el proceso de migración de datos (ya sea a plena carga mongodump o a plena carga de AWS DMS tareas), además de un búfer razonable. Para obtener más información, consulte el tema en el que se describe cómo comprobar el tamaño del Oplog en la documentación de MongoDB. Determine el tamaño mínimo requerido de oplog registrando el tiempo que ha tardado la primera ejecución de prueba del proceso mongodump o mongorestore o la tarea de carga completa de AWS DMS .
AWS Database Migration Service Configuración
La AWS Database Migration Service Guía del usuarioabarca los componentes y los pasos necesarios para migrar los datos de origen de MongoDB a su clúster de Amazon DocumentDB. El siguiente es el proceso básico que se utiliza AWS DMS para realizar una migración en línea o híbrida:
Para realizar una migración mediante AWS DMS
-
Cree un punto de conexión de origen de MongoDB. Para obtener más información, consulte Uso de MongoDB como origen para AWS DMS.
-
Crear un punto de conexión de Amazon DocumentDB. Para obtener más información, consulte Trabajo con AWS DMS puntos de conexión.
Si está configurando su punto de conexión de destino como un clúster elástico, tenga en cuenta que su certificado SSL de Amazon DocumentDB existente no funcionará con los clústeres elásticos y tendrá que adjuntar un nuevo certificado SSL a su punto de conexión mediante los siguientes pasos:
a. Visite https://www.amazontrust.com/repository/SFSRootCAG2.pem
y guarde el contenido como un archivo “SFSRootCAG2.pem”. Este es el archivo de certificado que necesitará importar en los siguientes pasos. b. Al crear el punto final del clúster elástico, en Configuración del punto de conexión, elija Agregar un nuevo certificado de CA.
En Identificador del certificado, escriba
SFSRootCAG2.pem.En Importar archivo de certificado, elija Seleccionar archivo y acceda al archivo
SFSRootCAG2.pemque descargó anteriormente. Seleccione el archivo y ábralo. Elija Importar certificado y seleccioneSFSRootCAG2.pemen la lista desplegable Elija un certificado.
-
Cree al menos una instancia de AWS DMS replicación. Para obtener más información, consulte Trabajar con una instancia de AWS DMS replicación.
-
Cree al menos una tarea de AWS DMS replicación. Para obtener más información, consulte Trabajar con tareas de AWS DMS.
En una migración online, la tarea de migración utiliza el tipo de migración Migrate existing data and replicate ongoing changes (Migrar datos existentes y replicar los cambios en curso).
En una migración híbrida, la tarea de migración utiliza el tipo de migración Replicate data changes only (Replicar solo los cambios en los datos). Puede elegir la hora de inicio del CDC para ajustarla a la hora de volcado de su operación
mongodump. El oplog de MongoDB es idempotent. Para no perder ningún cambio, es buena idea dejar que se solapen unos minutos entre la hora de finalización demongodumpy la hora de inicio de CDC.
Migración desde un clúster fragmentado
El proceso para migrar datos desde un clúster con particiones de MongoDB a la instancia de Amazon DocumentDB es básicamente el mismo que el que se utiliza para migrar varios conjuntos de réplicas en paralelo. Un aspecto clave que hay que tener en cuenta a la hora de probar una migración de clústeres fragmentados es que es posible que algunos fragmentos se utilicen mucho más que otros. Esta situación da lugar a diferentes tiempos transcurridos para la migración de datos. Asegúrese de evaluar los requisitos oplog de cada partición a la hora de planificar y realizar las pruebas.
A continuación, se muestran algunos problemas de configuración que se deben tener en cuenta a la hora de migrar un clúster fragmentado:
-
Antes de ejecutar
mongodumpo iniciar una tarea de migración de AWS DMS , debe deshabilitar el balanceador de clústeres fragmentados y esperar a que terminen las migraciones en curso. Para obtener más información, consulte el tema en el que se explica cómo deshabilitar el balanceador en la documentación de MongoDB. -
Si va AWS DMS a replicar datos, ejecute el
cleanupOrphanedcomando en cada fragmento antes de ejecutar las tareas de migración. Si no ejecuta este comando, las tareas podrían producir un error, debido a que los identificadores de documento podrían estar duplicados. Tenga en cuenta que este comando podría afectar al rendimiento. Para obtener más información, consulte cleanupOrphaned en la documentación de MongoDB. -
Si utiliza la herramienta
mongodumppara volcar datos, debería ejecutar un procesomongodumppor fragmento. El enfoque más rápido podría requerir varios servidores de migración para aumentar al máximo el rendimiento de volcado. -
Si lo utiliza AWS Database Migration Service para replicar datos, debe crear un punto final de origen para cada fragmento. Ejecute también al menos una tarea de migración para cada fragmento que vaya a migrar. El enfoque más rápido podría requerir varias instancias de replicación para aumentar al máximo el rendimiento de la migración.
Pruebas de rendimiento
Después de migrar correctamente los datos al clúster de Amazon DocumentDB de prueba, ejecute la carga de trabajo de prueba en el clúster. Compruebe mediante CloudWatch las métricas de Amazon que su rendimiento iguala o supera el rendimiento actual de su implementación de código fuente de MongoDB.
Compruebe las siguientes métricas clave de Amazon DocumentDB:
-
Network throughput
-
Velocidad de escritura
-
Velocidad de lectura
-
Retraso de réplica
Para obtener más información, consulte Monitorización de Amazon DocumentDB.
Prueba de conmutación por error
Compruebe que el comportamiento de la aplicación durante un evento de conmutación por error de Amazon DocumentDB cumple los requisitos de disponibilidad. Para iniciar una conmutación por error manual de un clúster de Amazon DocumentDB en la consola, en la página Clústeres, elija la acción Conmutación por error en el menú Acciones.
También puede iniciar una conmutación por error ejecutando la operación failover-db-cluster desde la AWS CLI. Para obtener más información, consulte failover-db-clusterla sección Amazon DocumentDB de la AWS CLI referencia.
Recursos adicionales
Consulte los siguientes temas en la Guía del usuario de AWS Database Migration Service :
