Componentes de AWS Glue
AWS Glue proporciona una consola y operaciones de API para configurar y administrar su carga de flujo de trabajo de extracción, transformación y carga (ETL). Puede usar las operaciones de API a través de varios SDK específicos de lenguaje y la AWS Command Line Interface (AWS CLI). Para obtener información sobre el uso de AWS CLI, consulte Referencias de comandos de AWS CLI.
AWS Glue usa el AWS Glue Data Catalog para almacenar metadatos acerca de orígenes de datos, transformaciones y destinos. El Data Catalog es un reemplazo instantáneo para el Apache Hive Metastore. AWS Glue Jobs system proporciona una infraestructura administrada para definir, programar y ejecutar operaciones de ETL en sus datos. Para obtener más información sobre la API de AWS Glue, consulte API de AWS Glue.
Consola de AWS Glue
Use la consola de AWS Glue para definir y orquestar su flujo de flujo de trabajo de ETL. La consola llama a varias operaciones API en el AWS Glue Data Catalog y AWS Glue Jobs system para realizar las siguientes tareas:
-
Definir objetos de AWS Glue como trabajos, tablas, rastreadores y conexiones.
-
Programar cuándo se ejecutan los rastreadores.
-
Definir eventos o programaciones para los disparadores de trabajos.
-
Buscar y filtrar listas de objetos de AWS Glue.
-
Editar scripts de transformación.
AWS Glue Data Catalog
El AWS Glue Data Catalog es su almacén de metadatos técnicos persistente en la nube de AWS.
Cada cuenta de AWS tiene un AWS Glue Data Catalog por región de AWS. Cada catálogo de datos es una colección de tablas altamente escalable organizadas en bases de datos. Una tabla es la representación de metadatos de una colección de datos estructurados o semiestructurados almacenados en orígenes como Amazon RDS, Apache Hadoop Distributed File System, Amazon OpenSearch Service y otros. AWS Glue Data Catalog proporciona un repositorio uniforme donde sistemas dispares pueden almacenar y encontrar metadatos para hacer un seguimiento de los datos en silos de datos. A continuación, puede utilizar los metadatos para consultar y transformar esos datos de forma coherente en una amplia variedad de aplicaciones.
Utilice el catálogo de datos junto con políticas de AWS Identity and Access Management y Lake Formation para controlar el acceso a las tablas y bases de datos. Al hacer esto, permite a los diversos grupos de su empresa publicar datos de forma segura en toda la organización, al mismo tiempo que se protege la información confidencial de forma altamente granular.
El catálogo de datos, junto con CloudTrail y Lake Formation, también proporciona capacidades de auditoría y gobernanza completas, con seguimiento de cambios de esquema y controles de acceso de datos. Esto ayuda a garantizar que los datos no se modificaron incorrectamente o no se compartieron sin querer.
Para obtener información sobre cómo proteger y auditar el AWS Glue Data Catalog, consulte:
-
AWS Lake Formation: para obtener más información, consulte ¿Qué es AWS Lake Formation? en la Guía para desarrolladores de AWS Lake Formation.
-
CloudTrail: para obtener más información, consulte What Is CloudTrail? (¿Qué es CloudTrail?) en la Guía del usuario de AWS CloudTrail.
Los siguientes son otros servicios y proyectos de código abierto de AWS que utilizan el AWS Glue Data Catalog:
-
Amazon Athena: para obtener más información, consulte Descripción de las tablas, bases de datos y el catálogo de datos en la Guía del usuario de Amazon Athena.
-
Amazon Redshift Spectrum: para obtener más información, consulte Using Amazon Redshift Spectrum to Query External Data (Uso de Amazon Redshift Spectrum para consultar datos externos) en la Guía para desarrolladores de bases de datos Amazon Redshift.
-
Amazon EMR: para obtener más información, consulte Resource-Based Policies for Amazon EMR Access to AWS Glue Data Catalog (Uso de políticas basadas en recursos para acceso de Amazon EMR al ) en la Guía de administración de Amazon EMR.
-
Cliente de AWS Glue Data Catalog para el almacén de metadatos de Apache Hive: para obtener más información sobre este proyecto de GitHub, consulte Cliente de AWS Glue Data Catalog para el almacén de metadatos de Apache Hive
.
Rastreadores y clasificadores de AWS Glue
AWS Glue también le permite configurar rastreadores que pueden analizar datos en toda clase de repositorios, clasificarlos, extraer información de esquema de ellos y almacenar los metadatos de forma automática en el AWS Glue Data Catalog. El AWS Glue Data Catalog se puede usar para guiar las operaciones de ETL.
Para obtener información acerca de cómo configurar rastreadores y clasificadores, consulte Uso de rastreadores para completar el Catálogo de datos . Para obtener información acerca de cómo programar rastreadores y clasificadores mediante la API de AWS Glue, consulte API de rastreadores y clasificadores.
Operaciones de ETL de AWS Glue
Al usar los metadatos en el Data Catalog, AWS Glue puede generar automáticamente scripts de Scala o PySpark (la API de Python para Apache Spark) con extensiones de AWS Glue que puede usar y modificar para realizar diversas operaciones de ETL. Por ejemplo, puede extraer, limpiar y transformar datos sin formato y, a continuación, almacenar el resultado en un repositorio distinto, donde se puede consultar y analizar. Dicho script puede convertir un archivo CSV en un formato relacional y guardarlo en Amazon Redshift.
Para obtener más información acerca de cómo usar capacidades de ETL de AWS Glue, consulte Programación de scripts de Spark.
ETL de streaming en AWS Glue
AWS Glue le permite realizar operaciones de ETL en datos de streaming mediante trabajos en ejecución continua. ETL de streaming de AWS Glue se basa en el motor Apache Spark Structured Streaming, y puede capturar flujos de Amazon Kinesis Data Streams, Apache Kafka y Amazon Managed Streaming for Apache Kafka (Amazon MSK). ETL de streaming puede limpiar y transformar los datos de streaming y cargarlos en almacenes de datos de Amazon S3 o JDBC. Utilice ETL de streaming en AWS Glue para procesar datos de eventos como transmisiones de IoT, transmisiones de clics y registros de red.
Si conoce el esquema del origen de datos de streaming, puede especificarlo en una tabla del Data Catalog. De lo contrario, puede habilitar la detección de esquemas en el trabajo de ETL de streaming. El trabajo determinará en forma automática el esquema a partir de los datos entrantes.
El script de ETL puede usar las transformaciones incorporadas de AWS Glue y las transformaciones nativas de Apache Spark Structured Streaming. Para obtener más información, consulte Operaciones en DataFrames/conjuntos de datos de streaming
Para obtener más información, consulte Trabajos ETL de streaming en AWS Glue.
El sistema de trabajos de AWS Glue
AWS Glue Jobs system proporciona infraestructura administrada para orquestar su flujo de flujo de trabajo de ETL. Puede crear trabajos en AWS Glue que automaticen los scripts que usa para extraer, transformar y transferir datos a distintas ubicaciones. Los trabajos se pueden programar y encadenar, o bien eventos como la llegada de nuevos datos pueden activarlos.
Para obtener más información acerca del uso de AWS Glue Jobs system, consulte Supervisión de AWS Glue. Para obtener información acerca de la programación del uso de la API de AWS Glue Jobs system, consulte API de trabajos.
Componentes de ETL visuales
AWS Glue permite crear trabajos de ETL a través de un lienzo visual que pueda manipular.
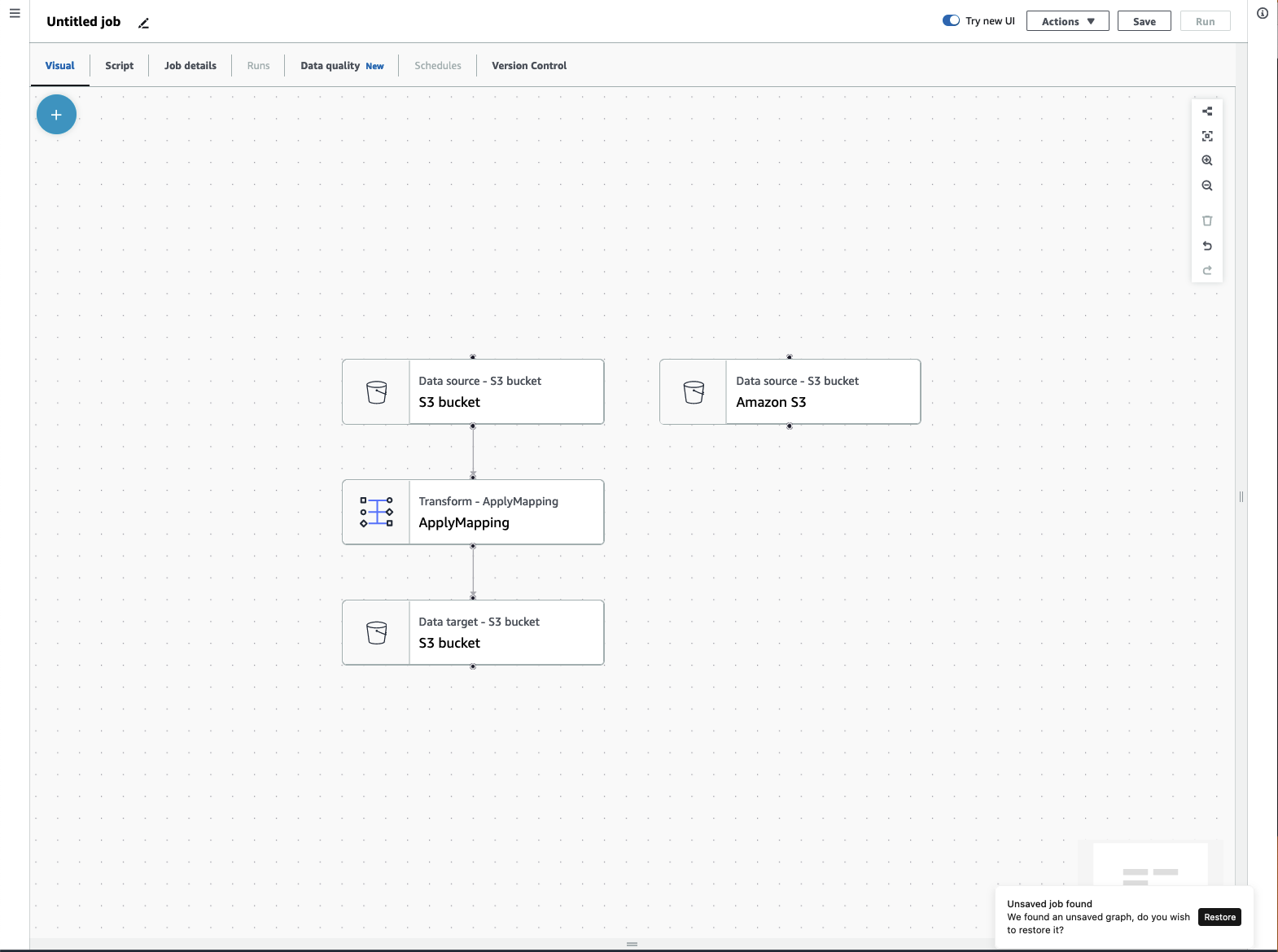
Menú de trabajos de ETL
Las opciones del menú en la parte superior del lienzo permiten acceder a las distintas vistas y detalles de configuración del trabajo.
-
Visual: el lienzo del editor de trabajos de Visual. Aquí es donde puede agregar nodos para crear un trabajo.
-
Script: la representación en script de su trabajo de ETL. AWS Glue genera el script en función de la representación visual de su trabajo. También puede editar el guion o descargarlo.
nota
Si decide editar el guion, la experiencia de creación de trabajos se convierte permanentemente en un modo de solo guion. Después ya no podrá utilizar el editor visual para editar el trabajo. Debe agregar todos los orígenes, transformaciones y destinos del trabajo y realizar todos los cambios que necesite con el editor visual antes de decidir editar el guion.
-
Detalles del trabajo: la pestaña Detalles del trabajo permite configurar el trabajo mediante la configuración de las propiedades del trabajo. Hay propiedades básicas, como el nombre y la descripción del trabajo, el rol de IAM, el tipo de trabajo, la versión de AWS Glue, el idioma, el tipo de trabajador, el número de trabajadores, el marcador del trabajo, la ejecución flexible, el número de retiros y el tiempo de espera del trabajo. También hay propiedades avanzadas, como las conexiones, las bibliotecas, los parámetros del trabajo y las etiquetas.
-
Ejecuciones: después de ejecutar el trabajo, se puede acceder a esta pestaña para ver las ejecuciones anteriores.
-
Calidad de datos: calidad de datos evalúa y supervisa la calidad de sus activos de datos. Puede obtener más información sobre cómo utilizar la calidad de los datos en esta pestaña y agregar una transformación de la calidad de los datos al trabajo.
-
Programas: Los trabajos que ha programado aparecen en esta pestaña. Si no hay ningún programa adjunto a este trabajo, no se puede acceder a esta pestaña.
-
Control de versiones: puede usar Git con el trabajo al configurarlo en un repositorio de Git.
Paneles de ETL visuales
Cuando trabaja en el lienzo, hay varios paneles disponibles para ayudarle a configurar los nodos o a obtener una vista previa de los datos y ver el esquema de salida.
-
Propiedades: el panel Propiedades aparece al elegir un nodo del lienzo.
-
Vista previa de datos: el panel de vista previa de datos proporciona una vista preliminar de la salida de datos para que pueda tomar decisiones antes de ejecutar el trabajo y examinar la salida.
-
Esquema de salida: la pestaña Esquema de salida permite ver y editar el esquema de los nodos de transformación.
Redimensionar los paneles
Puede cambiar el tamaño del panel de Propiedades situado en el lado derecho de la pantalla y en el panel inferior, que contiene las pestañas de Vista previa de datos y Esquema de salida al hacer clic en el borde del panel y arrastrarlo hacia la izquierda y hacia la derecha o hacia arriba y hacia abajo.
-
Panel de propiedades: cambie el tamaño del panel de propiedades al hacer clic y arrastrar el borde del lienzo situado en el lado derecho de la pantalla y arrastrándolo hacia la izquierda para ampliar el ancho. De forma predeterminada, el panel está contraído y, cuando se selecciona un nodo, el panel de propiedades se abre con un tamaño predeterminado.
-
Panel de vista previa de datos y esquema de salida: cambie el tamaño del panel inferior al hacer clic y arrastrar el borde inferior del lienzo en la parte inferior de la pantalla. Luego arrástrelo hacia arriba para ampliar la altura. De forma predeterminada, el panel está contraído y, cuando se selecciona un nodo, el panel inferior se abre con un tamaño predeterminado.
Lienzo de trabajo
Puede agregar, eliminar y mover o reordenar nodos directamente en el lienzo de ETL visuales. Considérelo su espacio de trabajo para crear un trabajo de ETL completamente funcional que comience con un origen de datos y termine con un destino de datos.
Cuando trabaja con nodos en el lienzo, cuenta con una barra de herramientas que puede ayudarle a acercar y alejar la imagen, eliminar nodos, establecer o editar conexiones entre nodos, cambiar la orientación del flujo de trabajo y deshacer o rehacer una acción.

La barra de herramientas flotante está anclada al tamaño superior derecho del lienzo y contiene varias imágenes que realizan acciones:
-
Icono de diseño: el primer icono de la barra de herramientas es el icono de diseño. La dirección de las tareas visuales es de arriba a abajo de forma predeterminada. Reorganiza la dirección de las tareas visuales al organizar los nodos horizontalmente de izquierda a derecha. Al volver a hacer clic en el icono de diseño, se cambia la dirección de arriba a abajo.
-
Icono de recentrar: el icono de recentrar cambia la vista del lienzo al centrarlo. Puede usarlo con trabajos grandes para volver a la posición central.
-
Ícono de zoom: el icono de zoom amplía el tamaño de los nodos del lienzo.
-
Ícono de alejar: el icono de zoom achica el tamaño de los nodos del lienzo.
-
Icono de papelera: el icono de papelera elimina un nodo del trabajo visual. Primero debe seleccionar un nodo.
-
Icono de deshacer: el icono de deshacer invierte la última acción realizada en el trabajo visual.
-
Icono de rehacer: el icono de rehacer repite la última acción realizada en el trabajo visual.
Uso del minimapa

Panel de recursos
El panel de recursos contiene todos los orígenes de datos, las acciones de transformación y las conexiones disponibles. Abre el panel de recursos en el lienzo mediante un clic en el icono “+”. Esto abrirá el panel de recursos.
Para cerrar el panel de recursos, haz clic en la X situada en la esquina superior derecha del panel de recursos. Esto ocultará el panel hasta que estés listo para volver a abrirlo.
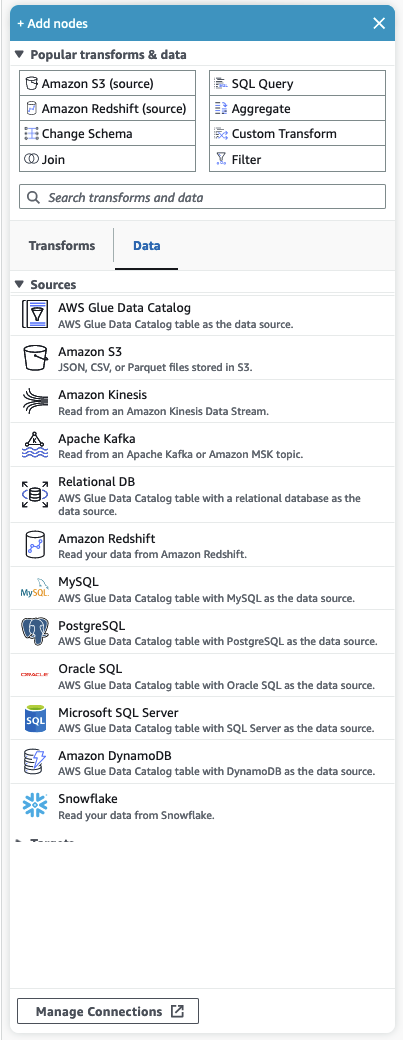
Transformaciones populares y datos
En la parte superior del panel hay una colección de transformaciones populares y datos. Estos nodos se utilizan habitualmente en AWS Glue. Elija uno para agregarlo al lienzo. También puede ocultar las Transformaciones populares y datos al hacer clic en el triángulo situado junto al encabezado Transformaciones populares y datos.
En la sección Transformaciones populares y datos, puede buscar transformaciones y nodos de orígenes de datos. Los resultados aparecen a medida que escribe. Cuantas más letras agregue a la búsqueda, la lista de resultados se reducirá. Los resultados de la búsqueda se llenan a partir del nombre o la descripción del nodo. Elija el nodo para agregarlo al lienzo.
Transformaciones y datos
Hay dos pestañas que organizan los nodos en transformaciones y datos.
Transformaciones: al elegir la pestaña Transformaciones, se pueden seleccionar todas las transformaciones disponibles. Elija una transformación para agregarla al lienzo. También puede elegir Agregar transformación en la parte inferior de la lista de transformaciones, lo que abrirá una nueva página con la documentación para crear transformaciones visuales personalizadas. Si sigue estos pasos, podrá crear sus propias transformaciones. Sus transformaciones aparecerán en la lista de transformaciones disponibles.
Datos: la pestaña de datos contiene todos los nodos de los orígenes y los destinos. Puede ocultar los orígenes y los destinos al hacer clic en el triángulo situado junto al encabezado Orígenes o destinos. Puede mostrar los orígenes y los destinos al hacer clic de nuevo en el triángulo. Elija un nodo de origen o de destino para agregarlo al lienzo. También puede elegir Administrar conexiones para agregar una nueva conexión. Esto abrirá la página de conectores en la consola.
