Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Problema RunBooks
La siguiente sección contiene los problemas que pueden producirse, cómo detectarlos y sugerencias para resolverlos.
-
Problemas de administración de identidades
Al iniciar sesión en el entorno, vuelvo inmediatamente a la página de inicio de sesión
Se produjo el error «Usuario no encontrado» al intentar iniciar sesión
El usuario se agregó en Active Directory, pero no aparece en RES
Se ha superado el límite de tamaño: error en el registro del administrador del CloudWatch clúster
-
-
Componente de escritorio virtual
La EC2 instancia de Amazon aparece repetidamente finalizada en la consola
El proyecto no aparece en el menú desplegable al editar la pila de software para añadirla
Problemas de opciones de DHCP con external/customer la configuración de AD
Error de Firefox MOZILLA_PKIX_ERROR_REQUIRED_TLS_FEATURE_MISSING
Problemas de instalación
Temas
........................
AWS CloudFormation la pila no se puede crear con el mensaje «se WaitCondition recibió el mensaje fallido». Error: estados. TaskFailed»
Para identificar el problema, examine el grupo de CloudWatch registros de Amazon denominado<stack-name>-InstallerTasksCreateTaskDefCreateContainerLogGroup<nonce>-<nonce>. Si hay varios grupos de registros con el mismo nombre, examine el primero disponible. Un mensaje de error en los registros proporcionará más información sobre el problema.
nota
Confirme que los valores de los parámetros no tengan espacios.
........................
No se recibió la notificación por correo electrónico después de que las AWS CloudFormation pilas se crearan correctamente
Si no se recibió una invitación por correo electrónico después de haber creado correctamente las AWS CloudFormation pilas, compruebe lo siguiente:
-
Confirme que el parámetro de dirección de correo electrónico se haya introducido correctamente.
Si la dirección de correo electrónico es incorrecta o no se puede acceder a ella, elimine y vuelva a implementar el entorno de Research and Engineering Studio.
-
Consulta la EC2 consola de Amazon para ver pruebas de casos de ciclismo.
Si hay EC2 instancias de Amazon con el
<envname>prefijo que aparecen como terminadas y, a continuación, se sustituyen por una nueva instancia, es posible que haya un problema con la configuración de la red o de Active Directory. -
Si implementó las recetas de computación de AWS alto rendimiento para crear sus recursos externos, confirme que la pila haya creado la VPC, las subredes públicas y privadas y otros parámetros seleccionados.
Si alguno de los parámetros es incorrecto, es posible que tengas que eliminar y volver a implementar el entorno RES. Para obtener más información, consulte Desinstalar el producto.
-
Si implementó el producto con sus propios recursos externos, confirme que la red y Active Directory coincidan con la configuración esperada.
Es fundamental confirmar que las instancias de infraestructura se han unido correctamente a Active Directory. Pruebe los pasos que se indican Instancias cíclicas o controladora de vdc en estado fallido a continuación para resolver el problema.
........................
Instancias cíclicas o controladora de vdc en estado fallido
La causa más probable de este problema es la incapacidad de los recursos para conectarse o unirse a Active Directory.
Para comprobar el problema:
-
Desde la línea de comandos, inicie una sesión con SSM en la instancia en ejecución del vdc-controller.
-
Ejecute
sudo su -. -
Ejecute
systemctl status sssd.
Si el estado es inactivo, ha fallado o aparecen errores en los registros, significa que la instancia no se ha podido unir a Active Directory.
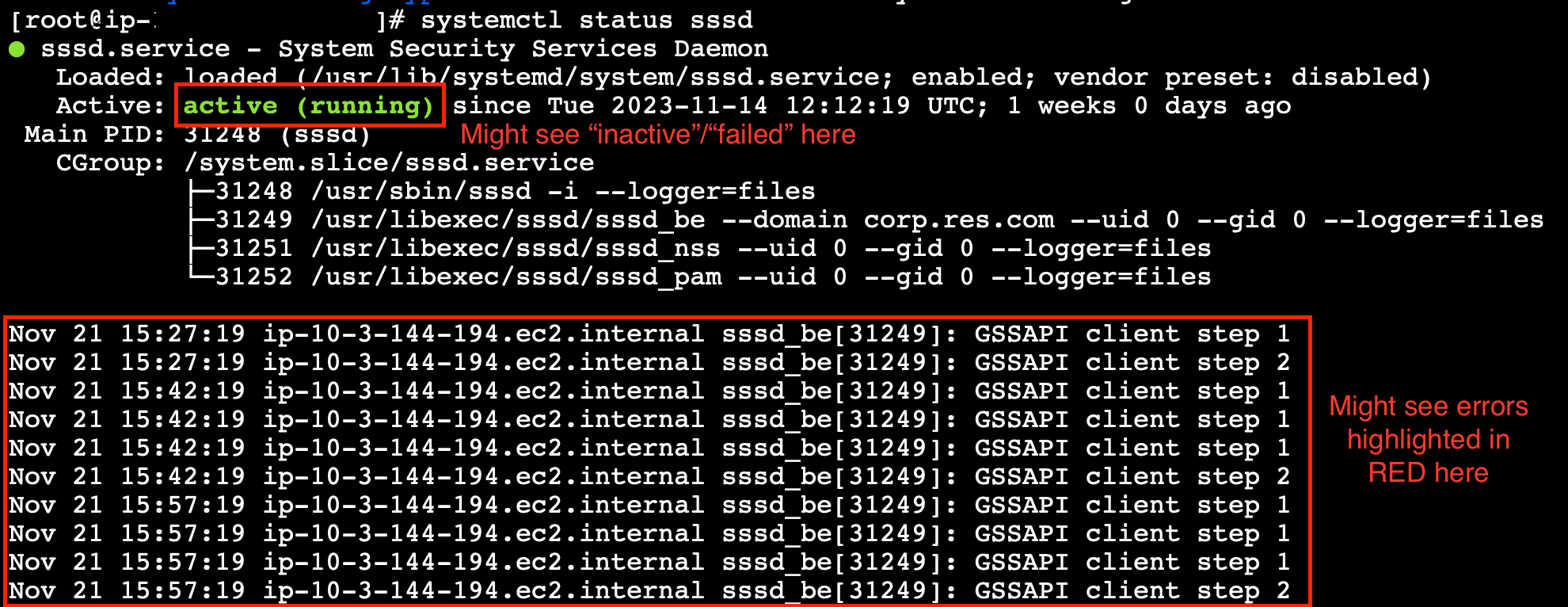
Registro de errores de SSM
Para resolver el problema:
-
Desde la misma instancia de línea de comandos, ejecuta
cat /root/bootstrap/logs/userdata.logpara investigar los registros.
El problema puede tener una de las tres causas principales posibles.
Revise los registros. Si ve que lo siguiente se repite varias veces, la instancia no ha podido unirse a Active Directory.
+ local AD_AUTHORIZATION_ENTRY= + [[ -z '' ]] + [[ 0 -le 180 ]] + local SLEEP_TIME=34 + log_info '(0 of 180) waiting for AD authorization, retrying in 34 seconds ...' ++ date '+%Y-%m-%d %H:%M:%S,%3N' + echo '[2024-01-16 22:02:19,802] [INFO] (0 of 180) waiting for AD authorization, retrying in 34 seconds ...' [2024-01-16 22:02:19,802] [INFO] (0 of 180) waiting for AD authorization, retrying in 34 seconds ... + sleep 34 + (( ATTEMPT_COUNT++ ))
-
Compruebe que los valores de los siguientes parámetros se hayan introducido correctamente durante la creación de la pila RES.
-
directoryservice.ldap_connection_uri
-
directoryservice.ldap_base
-
directoryservice.users.ou
-
directoryservice.groups.eu
-
directoryservice.sudoers.ou
-
directoryservice.computers.ou
-
directoryservice.name
-
-
Actualice los valores incorrectos de la tabla de DynamoDB. La tabla se encuentra en la consola de DynamoDB, en Tablas. El nombre de la tabla debe ser.
<stack name>.cluster-settings -
Tras actualizar la tabla, elimine el administrador de clústeres y el vdc-controller que actualmente ejecutan las instancias del entorno. El escalado automático iniciará nuevas instancias con los valores más recientes de la tabla de DynamoDB.
Si los registros vuelven a aparecerInsufficient permissions to modify computer account, es posible que el ServiceAccount nombre introducido durante la creación de la pila sea incorrecto.
-
Desde la AWS consola, abre Secrets Manager.
-
Busque la opción
directoryserviceServiceAccountUsername. El secreto debería ser<stack name>-directoryservice-ServiceAccountUsername -
Abre el secreto para ver la página de detalles. En Valor secreto, selecciona Recuperar valor secreto y selecciona Texto sin formato.
-
Si el valor se actualizó, elimine las instancias del entorno con el administrador de clústeres y el controlador de vdc que se estén ejecutando actualmente. El escalado automático iniciará nuevas instancias con el valor más reciente de Secrets Manager.
Si aparecen los registrosInvalid credentials, es posible que la ServiceAccount contraseña introducida durante la creación de la pila sea incorrecta.
-
Desde la AWS consola, abre Secrets Manager.
-
Busque la opción
directoryserviceServiceAccountPassword. El secreto debería ser<stack name>-directoryservice-ServiceAccountPassword -
Abre el secreto para ver la página de detalles. En Valor secreto, selecciona Recuperar valor secreto y selecciona Texto sin formato.
-
Si ha olvidado la contraseña o no está seguro de si es correcta, puede restablecerla en Active Directory y Secrets Manager.
-
Para restablecer la contraseña en AWS Managed Microsoft AD:
-
Abra la AWS consola y vaya a AWS Directory Service.
-
Seleccione el ID de directorio para su directorio RES y elija Acciones.
-
Elija Restablecer la contraseña de usuario.
-
Introduzca el ServiceAccount nombre de usuario.
-
Introduce una contraseña nueva y selecciona Restablecer contraseña.
-
-
Para restablecer la contraseña en Secrets Manager:
-
Abre la AWS consola y ve a Secrets Manager.
-
Busque la opción
directoryserviceServiceAccountPassword. El secreto debería ser<stack name>-directoryservice-ServiceAccountPassword -
Abre el secreto para ver la página de detalles. En Valor secreto, selecciona Recuperar valor secreto y elige Texto sin formato.
-
Seleccione Editar.
-
Establezca una nueva contraseña para el ServiceAccount usuario y seleccione Guardar.
-
-
-
Si actualizó el valor, elimine las instancias cluster-manager y vdc-controller del entorno que se estén ejecutando actualmente. El escalado automático iniciará nuevas instancias con el valor más reciente.
........................
La CloudFormation pila de entornos no se puede eliminar debido a un error en el objeto dependiente
Si la eliminación de la <env-name>-vdcvdcdcvhostsecuritygroup, podría deberse a que una EC2 instancia de Amazon se lanzó a una subred o grupo de seguridad creado por RES mediante la consola. AWS
Para resolver el problema, busca y cancela todas las EC2 instancias de Amazon lanzadas de esta manera. A continuación, puede reanudar la eliminación del entorno.
........................
Se encontró un error en el parámetro de bloque CIDR durante la creación del entorno
Al crear un entorno, aparece un error en el parámetro de bloque CIDR con un estado de respuesta de [FALLIDO].
Ejemplo de error:
Failed to update cluster prefix list: An error occurred (InvalidParameterValue) when calling the ModifyManagedPrefixList operation: The specified CIDR (52.94.133.132/24) is not valid. For example, specify a CIDR in the following form: 10.0.0.0/16.
Para resolver el problema, el formato esperado es x.x.x.0/24 o x.x.x.0/32.
........................
CloudFormation error al crear la pila durante la creación del entorno
La creación de un entorno implica una serie de operaciones de creación de recursos. En algunas regiones, puede producirse un problema de capacidad que provoque un error al crear una CloudFormation pila.
Si esto ocurre, elimine el entorno y vuelva a intentar la creación. Como alternativa, puede volver a intentar la creación en una región diferente.
........................
La creación de una pila de recursos externos (demostración) falla con AdDomainAdminNode CREATE_FAILED
Si la creación de la pila del entorno de demostración falla y aparece el siguiente error, es posible que se deba a que Amazon ha aplicado EC2 parches de forma inesperada durante el aprovisionamiento tras el lanzamiento de la instancia.
AdDomainAdminNode CREATE_FAILED Failed to receive 1 resource signal(s) within the specified duration
Para determinar la causa del error:
-
En el SSM State Manager, compruebe si la aplicación de parches está configurada y si está configurada para todas las instancias.
-
En el historial de ejecuciones del SSM, compruebe si la RunCommand/Automation ejecución de un documento SSM relacionado con la aplicación de parches coincide con el lanzamiento de una instancia.
-
En los archivos de registro de las instancias de Amazon del entorno, revisa el registro de EC2 instancias locales para determinar si la instancia se reinició durante el aprovisionamiento.
Si el problema se debió a la aplicación de parches, retrase la aplicación de los parches a las instancias de RES al menos 15 minutos después del lanzamiento.
........................
Problemas de administración de identidades
La mayoría de los problemas relacionados con el inicio de sesión único (SSO) y la administración de identidades se deben a una configuración incorrecta. Para obtener información sobre cómo configurar tu configuración de SSO, consulta:
Para solucionar otros problemas relacionados con la administración de identidades, consulta los siguientes temas de solución de problemas:
Temas
Al iniciar sesión en el entorno, vuelvo inmediatamente a la página de inicio de sesión
Se produjo el error «Usuario no encontrado» al intentar iniciar sesión
El usuario se agregó en Active Directory, pero no aparece en RES
Se ha superado el límite de tamaño: error en el registro del administrador del CloudWatch clúster
........................
No estoy autorizado a realizar iam: PassRole
Si recibe un mensaje de error que indica que no está autorizado a realizar la PassRole acción iam:, sus políticas deben actualizarse para que pueda transferir una función a RES.
Algunos AWS servicios le permiten transferir una función existente a ese servicio en lugar de crear una nueva función de servicio o una función vinculada a un servicio. Para ello, debe tener permisos para transferir el rol al servicio.
El siguiente ejemplo de error se produce cuando un usuario de IAM llamado marymajor intenta usar la consola para realizar una acción en RES. Sin embargo, la acción requiere que el servicio cuente con permisos que otorguen un rol de servicio. Mary no tiene permisos para transferir el rol al servicio.
User: arn:aws:iam::123456789012:user/marymajor is not authorized to perform: iam:PassRole
En este caso, las políticas de Mary deben actualizarse para que pueda realizar la acción iam:. PassRole Si necesitas ayuda, ponte en contacto con tu AWS administrador. El gestionador es la persona que le proporcionó las credenciales de inicio de sesión.
........................
Quiero permitir que personas ajenas a mi AWS cuenta accedan a los AWS recursos de mi Estudio de Investigación e Ingeniería
Puede crear un rol que los usuarios de otras cuentas o las personas externas a la organización puedan utilizar para acceder a sus recursos. Puede especificar una persona de confianza para que asuma el rol. En el caso de los servicios que admiten políticas basadas en recursos o listas de control de acceso (ACLs), puedes usar esas políticas para permitir que las personas accedan a tus recursos.
Para obtener más información, consulte lo siguiente:
-
Para obtener información sobre cómo proporcionar acceso a sus recursos en todas AWS las cuentas de su propiedad, consulte Proporcionar acceso a un usuario de IAM en otra AWS cuenta de su propiedad en la Guía del usuario de IAM.
-
Para obtener información sobre cómo proporcionar acceso a tus recursos a AWS cuentas de terceros, consulta Cómo proporcionar acceso a AWS cuentas propiedad de terceros en la Guía del usuario de IAM.
-
Para obtener información sobre cómo proporcionar acceso mediante la federación de identidades, consulte Proporcionar acceso a usuarios autenticados externamente (federación de identidades) en la Guía del usuario de IAM.
-
Para conocer la diferencia entre el uso de funciones y políticas basadas en recursos para el acceso entre cuentas, consulte en qué se diferencian las funciones de IAM de las políticas basadas en recursos en la Guía del usuario de IAM.
........................
Al iniciar sesión en el entorno, vuelvo inmediatamente a la página de inicio de sesión
Este problema se produce cuando la integración del SSO está mal configurada. Para determinar el problema, consulta los registros de las instancias del controlador y revisa los ajustes de configuración para ver si hay errores.
Para comprobar los registros:
-
Abra la consola de CloudWatch
. -
En Grupos de registros, busque el nombre del grupo
/.<environment-name>/cluster-manager -
Abra el grupo de registros para buscar cualquier error en las secuencias de registros.
Para comprobar los ajustes de configuración:
-
Abra la consola de DynamoDB
-
En Tablas, busque la tabla denominada.
<environment-name>.cluster-settings -
Abre la tabla y selecciona Explorar los elementos de la tabla.
-
Amplíe la sección de filtros e introduzca las siguientes variables:
-
Nombre del atributo: clave
-
Condición: contiene
-
Valor: sso
-
-
Seleccione Ejecución.
-
En la cadena devuelta, compruebe que los valores de configuración del SSO son correctos. Si son incorrectos, cambie el valor de la clave sso_enabled a False.
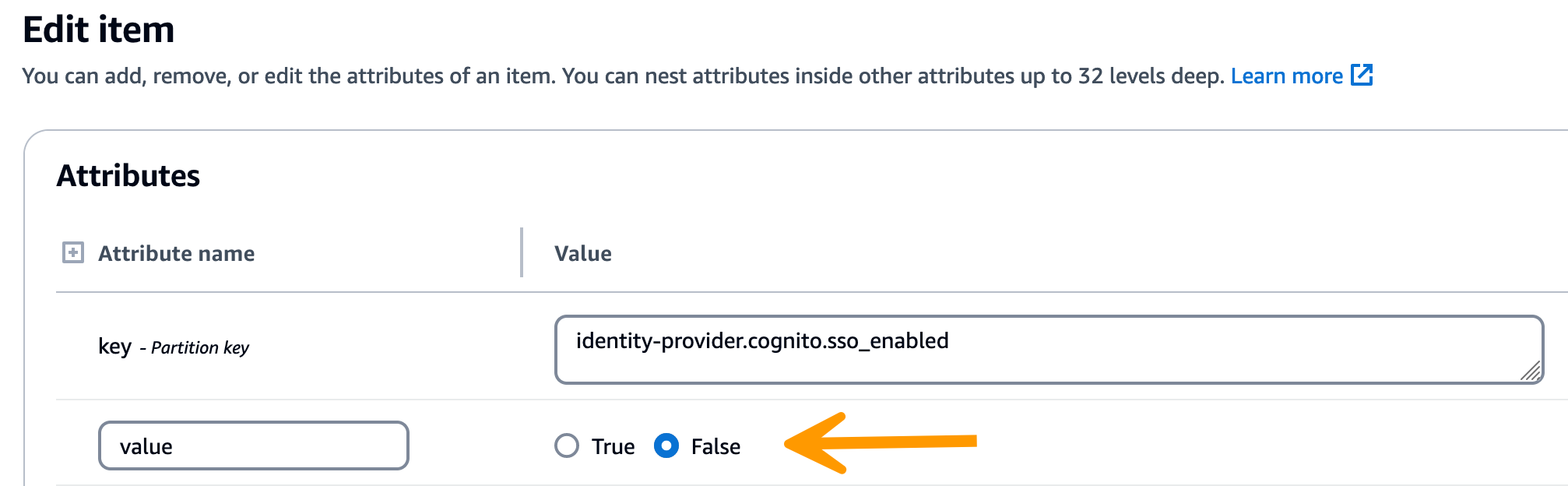
-
Vuelva a la interfaz de usuario de RES para volver a configurar el SSO.
........................
Se produjo el error «Usuario no encontrado» al intentar iniciar sesión
Si un usuario recibe el error «Usuario no encontrado» al intentar iniciar sesión en la interfaz RES y el usuario está presente en Active Directory:
-
Si el usuario no está presente en RES y usted lo agregó recientemente a AD
-
Es posible que el usuario aún no esté sincronizado con RES. RES se sincroniza cada hora, por lo que es posible que tengas que esperar y comprobar que el usuario se ha añadido después de la siguiente sincronización. Para sincronizar inmediatamente, sigue los pasos que se indican. El usuario se agregó en Active Directory, pero no aparece en RES
-
-
Si el usuario está presente en RES:
-
Asegúrese de que la asignación de atributos esté configurada correctamente. Para obtener más información, consulte Configuración del proveedor de identidad para el inicio de sesión único (SSO).
-
Asegúrese de que tanto el asunto SAML como el correo electrónico SAML coincidan con la dirección de correo electrónico del usuario.
-
........................
El usuario se agregó en Active Directory, pero no aparece en RES
Si ha agregado un usuario a Active Directory pero no aparece en RES, debe activarse la sincronización de AD. La sincronización de AD se realiza cada hora mediante una función Lambda que importa las entradas de AD al entorno RES. En ocasiones, se produce un retraso hasta que se ejecute el siguiente proceso de sincronización después de añadir nuevos usuarios o grupos. Puede iniciar la sincronización manualmente desde Amazon Simple Queue Service.
Inicie el proceso de sincronización manualmente:
-
Abra la consola de Amazon SQS
. -
En Colas, selecciona
<environment-name>-cluster-manager-tasks.fifo. -
Selecciona Enviar y recibir mensajes.
-
En Cuerpo del mensaje, ingresa:
{ "name": "adsync.sync-from-ad", "payload": {} } -
Para el ID del grupo de mensajes, introduzca:
adsync.sync-from-ad -
En el campo ID de deduplicación de mensajes, introduce una cadena alfanumérica aleatoria. Esta entrada debe ser diferente de todas las llamadas realizadas en los cinco minutos anteriores o se ignorará la solicitud.
........................
El usuario no estaba disponible al crear una sesión
Si es un administrador que está creando una sesión, pero descubre que un usuario que está en Active Directory no está disponible al crear una sesión, es posible que el usuario tenga que iniciar sesión por primera vez. Las sesiones solo se pueden crear para usuarios activos. Los usuarios activos deben iniciar sesión en el entorno al menos una vez.
........................
Se ha superado el límite de tamaño: error en el registro del administrador del CloudWatch clúster
2023-10-31T18:03:12.942-07:00 ldap.SIZELIMIT_EXCEEDED: {'msgtype': 100, 'msgid': 11, 'result': 4, 'desc': 'Size limit exceeded', 'ctrls': []}
Si recibe este error en el registro del CloudWatch administrador del clúster, es posible que la búsqueda de LDAP haya devuelto demasiados registros de usuario. Para solucionar este problema, aumente el límite de resultados de búsqueda de LDAP de su IDP.
........................
Almacenamiento
Temas
........................
Creé el sistema de archivos a través de RES, pero no se monta en los hosts VDI
Los sistemas de archivos deben estar en el estado «Disponible» antes de que los hosts VDI puedan montarlos. Siga los pasos que se indican a continuación para validar que el sistema de archivos se encuentra en el estado requerido.
Amazon EFS
-
Vaya a la consola de Amazon EFS
. -
Compruebe que el estado del sistema de archivos esté disponible.
-
Si el estado del sistema de archivos no está disponible, espere antes de iniciar los hosts VDI.
-
Ve a la FSx consola de Amazon
. -
Comprueba que el estado esté disponible.
-
Si el estado no está disponible, espere antes de lanzar los hosts de VDI.
........................
He incorporado un sistema de archivos mediante RES, pero no se monta en los hosts VDI
Los sistemas de archivos integrados en RES deben tener configuradas las reglas de grupo de seguridad requeridas para permitir que los hosts de VDI monten los sistemas de archivos. Como estos sistemas de archivos se crean de forma externa a RES, RES no administra las reglas de los grupos de seguridad asociados.
El grupo de seguridad asociado a los sistemas de archivos integrados debe permitir el siguiente tráfico entrante:
Tráfico NFS (puerto: 2049) desde los hosts VDC de Linux
Tráfico SMB (puerto: 445) desde los hosts VDC de Windows
........................
No puedo iniciar sesión desde los hosts read/write VDI
ONTAP admite los estilos de seguridad UNIX, NTFS y MIXED para los volúmenes. Los estilos de seguridad determinan el tipo de permisos que ONTAP utiliza para controlar el acceso a los datos y qué tipo de cliente puede modificar estos permisos.
Por ejemplo, si un volumen utiliza el estilo de seguridad UNIX, los clientes SMB pueden seguir accediendo a los datos (siempre que se autentiquen y autoricen correctamente) debido a la naturaleza multiprotocolo de ONTAP. Sin embargo, ONTAP utiliza permisos de UNIX que solo los clientes de UNIX pueden modificar mediante herramientas nativas.
Ejemplo de casos de uso de la gestión de permisos
Uso de volúmenes de estilo UNIX con cargas de trabajo de Linux
El sudoer puede configurar los permisos para otros usuarios. Por ejemplo, lo siguiente daría a todos los miembros todos <group-ID> los read/write permisos en el /<project-name> directorio:
sudo chown root:<group-ID>/<project-name>sudo chmod 770 /<project-name>
Uso de un volumen de estilo NTFS con cargas de trabajo de Linux y Windows
Los permisos de uso compartido se pueden configurar mediante las propiedades de uso compartido de una carpeta en particular. Por ejemplo, en función de un usuario user_01 y una carpetamyfolder, puedes establecer los permisos de Full ControlChange, Allow o Read paraDeny:
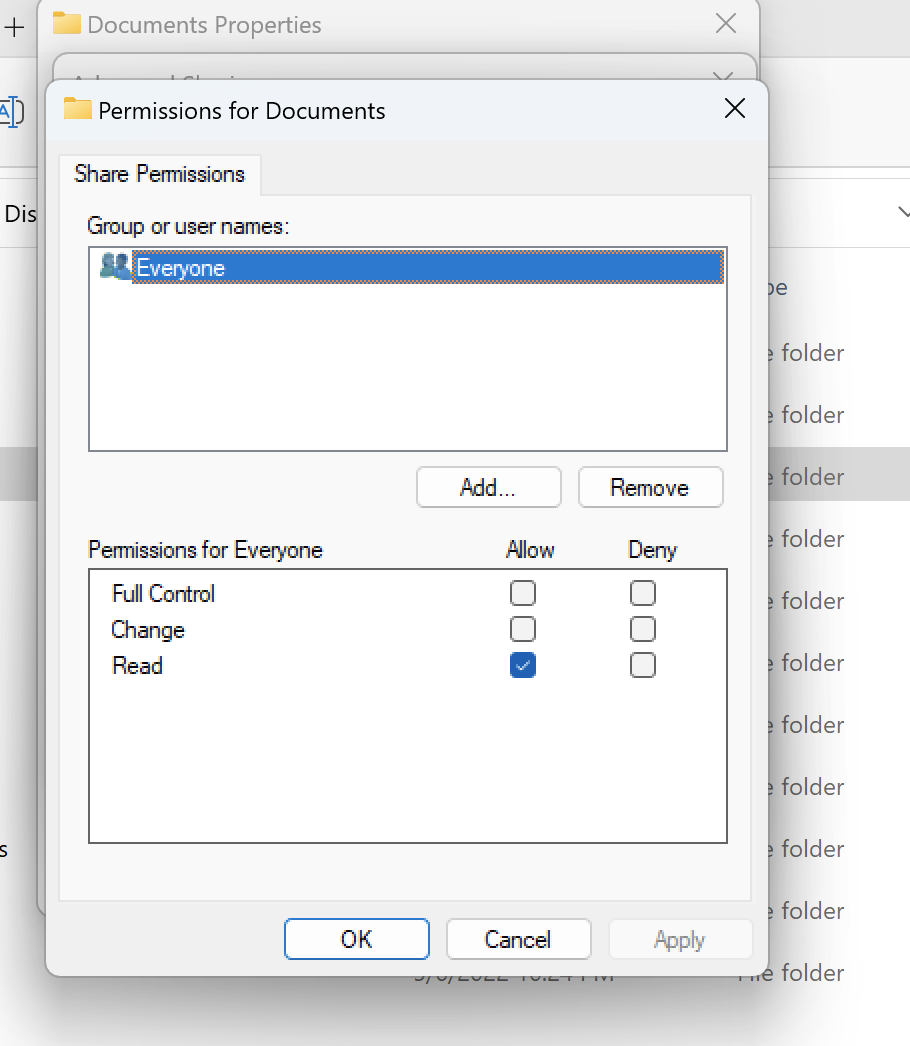
Si los clientes de Linux y Windows van a utilizar el volumen, necesitamos configurar una asignación de nombres en SVM que asocie cualquier nombre de usuario de Linux al mismo nombre de usuario con el formato de nombre de dominio de NetBIOS domain\ username. Esto es necesario para traducir entre usuarios de Linux y Windows. Como referencia, consulte Habilitar cargas de trabajo multiprotocolo con Amazon FSx for NetApp
........................
He creado Amazon FSx for NetApp ONTAP desde RES pero no se ha unido a mi dominio
Actualmente, al crear Amazon FSx para NetApp ONTAP desde la consola RES, el sistema de archivos se aprovisiona pero no se une al dominio. Para unir el SVM del sistema de archivos ONTAP creado a tu dominio, consulta Cómo unirse SVMs a un Microsoft Active Directory y sigue los pasos de la consola de Amazon FSx
Una vez unida al dominio, edite la clave de configuración de DNS SMB en la tabla DynamoDB de configuración del clúster:
-
Vaya a la consola de Amazon DynamoDB
. -
Seleccione Tablas y, a continuación, elija.
<stack-name>-cluster-settings -
En Explorar los elementos de la tabla, expanda Filtros e introduzca el siguiente filtro:
Nombre del atributo: clave
Condición: igual a
-
Valor -
shared-storage.<file-system-name>.fsx_netapp_ontap.svm.smb_dns
-
Selecciona el artículo devuelto y, a continuación, Acciones y Editar artículo.
-
Actualice el valor con el nombre DNS SMB que copió anteriormente.
-
Selecciona Guardar y cerrar.
Además, asegúrese de que el grupo de seguridad asociado al sistema de archivos permita el tráfico tal y como se recomienda en el Control de acceso al sistema de archivos con Amazon VPC. Los nuevos hosts de VDI que utilicen el sistema de archivos ahora podrán montar el SVM y el sistema de archivos unidos al dominio.
Como alternativa, puede incorporar un sistema de archivos existente que ya esté unido a su dominio mediante la función RES Onboard File System (en Environment Management, seleccione File Systems, Onboard File System).
........................
Instantáneas
Temas
........................
Una instantánea tiene el estado Fallido
En la página de instantáneas de RES, si una instantánea tiene el estado Fallido, se puede determinar la causa yendo al grupo de CloudWatch registros de Amazon del administrador de clústeres correspondiente al momento en que se produjo el error.
[2023-11-19 03:39:20,208] [INFO] [snapshots-service] creating snapshot in S3 Bucket: asdf at path s31 [2023-11-19 03:39:20,381] [ERROR] [snapshots-service] An error occurred while creating the snapshot: An error occurred (TableNotFoundException) when calling the UpdateContinuousBackups operation: Table not found: res-demo.accounts.sequence-config
........................
No se puede aplicar una instantánea y los registros indican que las tablas no se pudieron importar.
Si una instantánea tomada de un entorno anterior no se aplica a un entorno nuevo, busque en los CloudWatch registros el administrador de clústeres para identificar el problema. Si el problema menciona que la nube de tablas requerida no se puede importar, compruebe que la instantánea esté en un estado válido.
-
Descargue el archivo metadata.json y compruebe que el estado de ExportStatus las distintas tablas esté completado. Asegúrese de que las distintas tablas tengan el
ExportManifestcampo establecido. Si no encuentra configurados los campos anteriores, la instantánea se encuentra en un estado no válido y no se puede utilizar con la funcionalidad de aplicación de instantáneas. -
Tras iniciar la creación de una instantánea, asegúrese de que el estado de la instantánea pase a ser COMPLETADA en RES. El proceso de creación de la instantánea tarda entre 5 y 10 minutos. Vuelva a cargar o vuelva a visitar la página de administración de instantáneas para asegurarse de que la instantánea se creó correctamente. Esto garantizará que la instantánea creada esté en un estado válido.
........................
Infraestructura
........................
Grupos objetivo del balanceador de carga sin instancias en buen estado
Si aparecen problemas como mensajes de error del servidor en la interfaz de usuario o si las sesiones de escritorio no se pueden conectar, eso puede indicar un problema en la infraestructura de las EC2 instancias de Amazon.
Los métodos para determinar el origen del problema consisten en comprobar primero en la EC2 consola de Amazon cualquier EC2 instancia de Amazon que parezca estar finalizando repetidamente y siendo sustituida por instancias nuevas. Si ese es el caso, comprobar los CloudWatch registros de Amazon puede determinar la causa.
Otro método consiste en comprobar los balanceadores de carga del sistema. Un indicio de que puede haber problemas en el sistema es si algún balanceador de carga, que se encuentra en la EC2 consola de Amazon, no muestra ninguna instancia en buen estado registrada.
A continuación se muestra un ejemplo de aspecto normal:
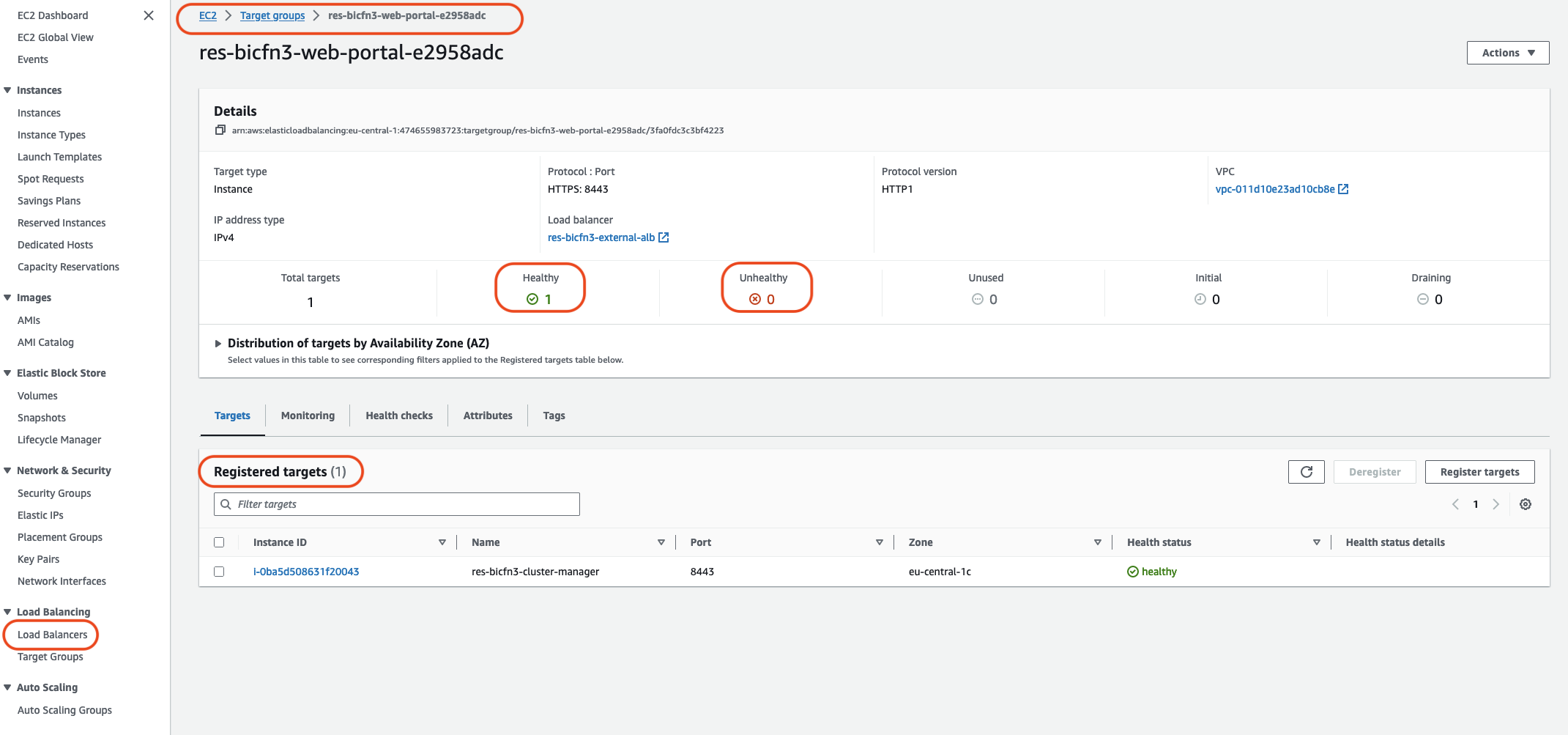
Si la entrada Healthy es 0, indica que no hay ninguna EC2 instancia de Amazon disponible para procesar las solicitudes.
Si la entrada Unhealthy no es 0, eso indica que es posible que una EC2 instancia de Amazon esté circulando. Esto puede deberse a que el software de las aplicaciones instaladas no pasa los controles de estado.
Si las entradas en buen estado y en mal estado son 0, eso indica un posible error de configuración de la red. Por ejemplo, es posible que las subredes pública y privada no tengan las correspondientes. AZs Si se produce esta condición, es posible que haya texto adicional en la consola que indique que existe un estado de red.
........................
Lanzamiento de escritorios virtuales
........................
Un escritorio virtual que funcionaba anteriormente ya no se puede conectar correctamente
Si se cierra una conexión de escritorio o ya no puedes conectarte a ella, el problema puede deberse a un error en la EC2 instancia de Amazon subyacente o a que la EC2 instancia de Amazon se haya cerrado o detenido fuera del entorno RES. Es posible que el estado de la interfaz de usuario del administrador siga mostrando un estado preparado, pero los intentos de conectarse a ella fallan.
Se debe usar Amazon EC2 Console para determinar si la instancia se ha cerrado o detenido. Si está detenida, intenta iniciarla de nuevo. Si el estado finaliza, será necesario crear otro escritorio. Todos los datos almacenados en el directorio principal del usuario deberían seguir estando disponibles cuando se inicie la nueva instancia.
Si la instancia que falló anteriormente sigue apareciendo en la interfaz de usuario del administrador, es posible que sea necesario cerrarla mediante la interfaz de usuario del administrador.
........................
Solo puedo iniciar 5 escritorios virtuales
El límite predeterminado de la cantidad de escritorios virtuales que un usuario puede lanzar es de 5. Un administrador puede cambiarlo mediante la interfaz de usuario de administración de la siguiente manera:
Ve a la configuración del escritorio.
Seleccione la pestaña Servidor.
En el panel Sesión de DCV, haga clic en el icono de edición de la derecha.
Cambie el valor de Sesiones permitidas por usuario al nuevo valor deseado.
Seleccione Enviar.
Actualice la página para confirmar que se ha establecido la nueva configuración.
........................
Los intentos de conexión a Windows desde un escritorio fallan y muestran el mensaje «Se ha cerrado la conexión». «Error de transporte»
Si se produce un error en la conexión de escritorio de Windows y aparece el error de interfaz de usuario «Se ha cerrado la conexión». Error de transporte», la causa puede deberse a un problema en el software del servidor DCV relacionado con la creación del certificado en la instancia de Windows.
El grupo de CloudWatch registros de Amazon <envname>/vdc/dcv-connection-gateway puede registrar el error de intento de conexión con mensajes similares a los siguientes:
Nov 24 20:24:27.631 DEBUG HTTP:Splicer Connection{id=9}: Websocket{session_id="1291e75f-7816-48d9-bbb2-7371b3b911cd"}: Resolver lookup{client_ip=Some(52.94.36.19) session_id="1291e75f-7816-48d9-bbb2-7371b3b911cd" protocol_type=WebSocket extension_data=None}:NoStrictCertVerification: Additional stack certificate (0): [s/n: 0E9E9C4DE7194B37687DC4D2C0F5E94AF0DD57E] Nov 24 20:25:15.384 INFO HTTP:Splicer Connection{id=21}:Websocket{ session_id="d1d35954-f29d-4b3f-8c23-6a53303ebc3f"}: Connection initiated error: unreachable, server io error Custom { kind: InvalidData, error: General("Invalid certificate: certificate has expired (code: 10)") } Nov 24 20:25:15.384 WARN HTTP:Splicer Connection{id=21}: Websocket{session_id="d1d35954-f29d-4b3f-8c23-6a53303ebc3f"}: Error in websocket connection: Server unreachable: Server error: IO error: unexpected error: Invalid certificate: certificate has expired (code: 10)
Si esto ocurre, una solución podría ser utilizar el administrador de sesiones SSM para abrir una conexión a la instancia de Windows y eliminar los dos archivos relacionados con los certificados siguientes:
PS C:\Windows\system32\config\systemprofile\AppData\Local\NICE\dcv> dir Directory: C:\Windows\system32\config\systemprofile\AppData\Local\NICE\dcv Mode LastWriteTime Length Name ---- ------------- ------ ---- -a---- 8/4/2022 12:59 PM 1704 dcv.key -a---- 8/4/2022 12:59 PM 1265 dcv.pem
Los archivos deberían volver a crearse automáticamente y es posible que un intento de conexión posterior se realice correctamente.
Si este método resuelve el problema y si los nuevos lanzamientos de escritorios Windows producen el mismo error, utilice la función Crear pila de software para crear una nueva pila de software de Windows de la instancia fija con los archivos de certificado regenerados. Esto puede producir una pila de software de Windows que se puede utilizar para iniciar y establecer conexiones satisfactorias.
........................
VDIs atascado en estado de aprovisionamiento
Si el inicio de un escritorio permanece en el estado de aprovisionamiento en la interfaz de usuario del administrador, puede deberse a varios motivos.
Para determinar la causa, examina los archivos de registro de la instancia de escritorio y busca errores que puedan estar causando el problema. Este documento contiene una lista de archivos de registro y grupos de CloudWatch registros de Amazon que contienen información relevante en la sección denominada Fuentes útiles de información de registros y eventos.
Las posibles causas de este problema son las siguientes.
-
El identificador de AMI utilizado se registró como una pila de software, pero RES no lo admite.
No se pudo completar el script de aprovisionamiento de bootstrap porque la AMI no tiene la configuración o las herramientas necesarias esperadas. Los archivos de registro de la instancia, como
/root/bootstrap/logs/los de una instancia de Linux, pueden contener información útil al respecto. AMIs Es posible que los identificadores tomados del AWS Marketplace no funcionen para las instancias de escritorio de RES. Es necesario probarlas para confirmar si son compatibles. -
Los scripts de datos de usuario no se ejecutan cuando la instancia de escritorio virtual de Windows se lanza desde una AMI personalizada.
De forma predeterminada, los scripts de datos de usuario se ejecutan una vez cuando se lanza una EC2 instancia de Amazon. Si crea una AMI a partir de una instancia de escritorio virtual existente, registra una pila de software con la AMI e intenta lanzar otro escritorio virtual con esta pila de software, los scripts de datos de usuario no se ejecutarán en la nueva instancia de escritorio virtual.
Para solucionar el problema, abra una ventana de PowerShell comandos como administrador en la instancia de escritorio virtual original que utilizó para crear la AMI y ejecute el siguiente comando:
C:\ProgramData\Amazon\EC2-Windows\Launch\Scripts\InitializeInstance.ps1 –ScheduleA continuación, cree una AMI nueva a partir de la instancia. Puede utilizar la nueva AMI para registrar pilas de software y lanzar nuevos escritorios virtuales posteriormente. Tenga en cuenta que también puede ejecutar el mismo comando en la instancia que permanece en el estado de aprovisionamiento y reiniciar la instancia para corregir la sesión del escritorio virtual, pero volverá a tener el mismo problema al lanzar otro escritorio virtual desde la AMI mal configurada.
........................
VDIs pasar al estado de error después de iniciar
- Posible problema 1: el sistema de archivos principal tiene un directorio para el usuario con diferentes permisos POSIX.
-
Este podría ser el problema al que te enfrentas si se dan las siguientes situaciones:
-
La versión RES implementada es la 2024.01 o superior.
-
Durante el despliegue de la pila RES, el atributo para
EnableLdapIDMappingse estableció en.True -
El sistema de archivos principal especificado durante el despliegue de la pila RES se usó en una versión anterior a la RES 2024.01 o se usó en un entorno anterior con el valor establecido en.
EnableLdapIDMappingFalse
Pasos de resolución: elimine los directorios de usuarios del sistema de archivos.
-
Envíe un SMS al host del administrador del clúster.
-
cd /home. -
ls- debería enumerar los directorios con nombres de directorio que coincidan con los nombres de usuario, comoadmin1,.. y así sucesivamente.admin2 -
Elimine los directorios,.
sudo rm -r 'dir_name'No elimine los directorios ssm-user y ec2-user. -
Si los usuarios ya están sincronizados con el nuevo entorno, elimínelos de la tabla DDB del usuario (excepto clusteradmin).
-
Inicie la sincronización de AD:
sudo /opt/idea/python/3.9.16/bin/resctl ldap sync-from-adejecútela en el administrador de clústeres Amazon. EC2 -
Reinicie la instancia de VDI en el
Errorestado desde la página web de RES. Valide que la VDI pase alReadyestado en unos 20 minutos.
-
........................
Componente de escritorio virtual
Temas
La EC2 instancia de Amazon aparece repetidamente finalizada en la consola
El proyecto no aparece en el menú desplegable al editar la pila de software para añadirla
Problemas de opciones de DHCP con external/customer la configuración de AD
Error de Firefox MOZILLA_PKIX_ERROR_REQUIRED_TLS_FEATURE_MISSING
........................
La EC2 instancia de Amazon aparece repetidamente finalizada en la consola
Si una instancia de infraestructura aparece repetidamente como terminada en la EC2 consola de Amazon, la causa puede estar relacionada con su configuración y depender del tipo de instancia de infraestructura. Los siguientes son métodos para determinar la causa.
Si la instancia de vdc-controller muestra estados terminados repetidamente en la EC2 consola de Amazon, esto puede deberse a una etiqueta secreta incorrecta. Los secretos que mantiene RES tienen etiquetas que se utilizan como parte de las políticas de control de acceso de IAM asociadas a la infraestructura de las EC2 instancias de Amazon. Si el controlador vdc está circulando y aparece el siguiente error en el grupo de CloudWatch registros, es posible que el secreto no se haya etiquetado correctamente. Tenga en cuenta que el secreto debe estar etiquetado con lo siguiente:
{ "res:EnvironmentName": "<envname>" # e.g. "res-demo" "res:ModuleName": "virtual-desktop-controller" }
El mensaje de CloudWatch registro de Amazon correspondiente a este error tendrá un aspecto similar al siguiente:
An error occurred (AccessDeniedException) when calling the GetSecretValue operation: User: arn:aws:sts::160215750999:assumed-role/<envname>-vdc-gateway-role-us-east-1/i-043f76a2677f373d0 is not authorized to perform: secretsmanager:GetSecretValue on resource: arn:aws:secretsmanager:us-east-1:160215750999:secret:Certificate-res-bi-Certs-5W9SPUXF08IB-F1sNRv because no identity-based policy allows the secretsmanager:GetSecretValue action
Comprueba las etiquetas de la EC2 instancia de Amazon y confirma que coinciden con la lista anterior.
........................
La instancia de vdc-controller está en ciclo debido a que no se pudo unir al módulo AD/eVDI muestra un error en la comprobación de estado de la API
Si el módulo eVDI no pasa la comprobación de estado, mostrará lo siguiente en la sección Estado del entorno.
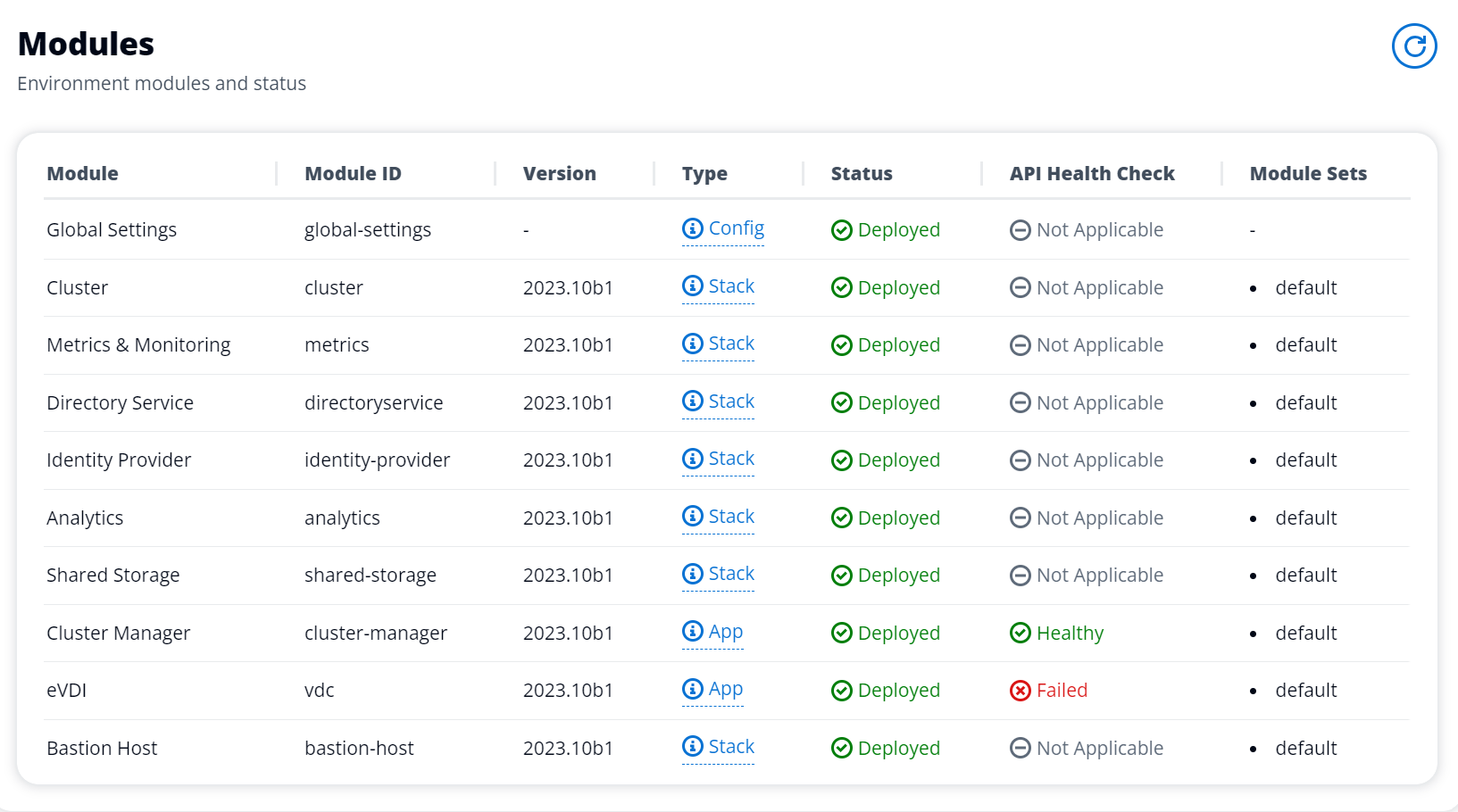
En este caso, la ruta general para la depuración consiste en consultar los registros del administrador del clúster CloudWatch<env-name>/cluster-manager
Posibles problemas:
-
Si los registros contienen el texto
Insufficient permissions, asegúrese de que el ServiceAccount nombre de usuario indicado al crear la pila de resoluciones esté escrito correctamente.Ejemplo de línea de registro:
Insufficient permissions to modify computer account: CN=IDEA-586BD25043,OU=Computers,OU=RES,OU=CORP,DC=corp,DC=res,DC=com: 000020E7: AtrErr: DSID-03153943, #1: 0: 000020E7: DSID-03153943, problem 1005 (CONSTRAINT_ATT_TYPE), data 0, Att 90008 (userAccountControl):len 4 >> 432 ms - request will be retried in 30 seconds-
Puede acceder al ServiceAccount nombre de usuario proporcionado durante la implementación de RES desde la SecretsManager consola
. Busque el secreto correspondiente en el administrador de secretos y seleccione Recuperar texto sin formato. Si el nombre de usuario es incorrecto, selecciona Editar para actualizar el valor secreto. Finalice las instancias actuales de cluster-manager y vdc-controller. Las nuevas instancias aparecerán en un estado estable. -
El nombre de usuario debe ser ServiceAccount «» si utiliza los recursos creados por la pila de recursos externos proporcionada. Si el
DisableADJoinparámetro se estableció en False durante la implementación de RES, asegúrese de que el usuario ServiceAccount «» tenga permisos para crear objetos informáticos en el AD.
-
-
Si el nombre de usuario utilizado es correcto, pero los registros contienen el texto
Invalid credentials, es posible que la contraseña que ingresó sea incorrecta o haya caducado.Ejemplo de línea de registro:
{'msgtype': 97, 'msgid': 1, 'result': 49, 'desc': 'Invalid credentials', 'ctrls': [], 'info': '80090308: LdapErr: DSID-0C090569, comment: AcceptSecurityContext error, data 532, v4563'}-
Puede leer la contraseña que ingresó durante la creación del entorno accediendo al secreto que almacena la contraseña en la consola de Secrets Manager
. Seleccione el secreto (por ejemplo, <env_name>directoryserviceServiceAccountPassword) y seleccione Recuperar texto sin formato. -
Si la contraseña del secreto es incorrecta, selecciona Editar para actualizar su valor en el secreto. Finalice las instancias actuales de cluster-manager y vdc-controller. Las nuevas instancias usarán la contraseña actualizada y aparecerán en un estado estable.
-
Si la contraseña es correcta, es posible que haya caducado en el Active Directory conectado. Primero tendrá que restablecer la contraseña en Active Directory y, a continuación, actualizar el secreto. Puede restablecer la contraseña del usuario en Active Directory desde la consola de Directory Service
: -
Elija el ID de directorio adecuado
-
Seleccione Acciones, Restablecer la contraseña del usuario y, a continuación, rellene el formulario con el nombre de usuario (por ejemplo, "ServiceAccount«) y la nueva contraseña.
-
Si la contraseña recién establecida es diferente de la contraseña anterior, actualice la contraseña en el secreto de Secret Manager correspondiente (por ejemplo,
<env_name>directoryserviceServiceAccountPassword. -
Finalice las instancias actuales de cluster-manager y vdc-controller. Las nuevas instancias aparecerán en un estado estable.
-
-
........................
El proyecto no aparece en el menú desplegable al editar la pila de software para añadirla
Este problema puede estar relacionado con el siguiente problema relacionado con la sincronización de la cuenta de usuario con AD. Si aparece este problema, busca el error <user-home-init> account not available yet. waiting for user to be synced "" en el grupo de registros de CloudWatch Amazon, administrador del clúster, para determinar si la causa es la misma o está relacionada.
........................
El registro de CloudWatch Amazon del administrador de clústeres muestra «user-home-init< > la cuenta aún no está disponible. En espera de que se sincronice el usuario» (donde la cuenta es un nombre de usuario)
El suscriptor de SQS está ocupado y atrapado en un bucle infinito porque no puede acceder a la cuenta de usuario. Este código se activa cuando se intenta crear un sistema de archivos doméstico para un usuario durante la sincronización del usuario.
La razón por la que no puede acceder a la cuenta de usuario puede deberse a que RES no se configuró correctamente para el AD en uso. Un ejemplo podría ser que el ServiceAccountUsername parámetro utilizado en la creación del BI/RES entorno no fuera el valor correcto, por ejemplo, utilizando «ServiceAccount» en lugar de «Admin».
........................
Al intentar iniciar sesión en el escritorio de Windows, aparece el mensaje «Tu cuenta ha sido deshabilitada». Consulte a su administrador»
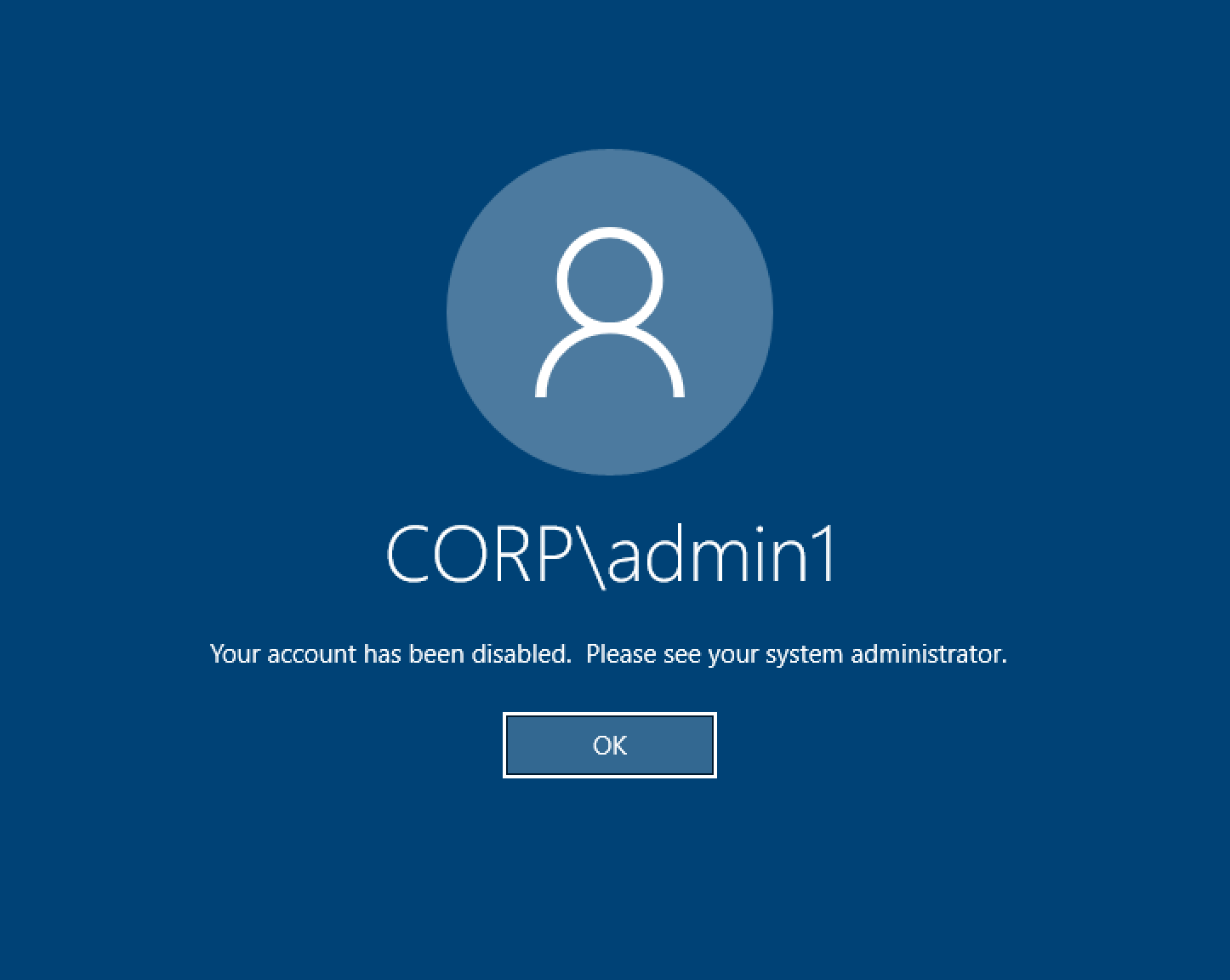
Si el usuario no puede volver a iniciar sesión en una pantalla bloqueada, esto puede indicar que el usuario se ha desactivado en el AD configurado para RES tras haber iniciado sesión correctamente mediante el inicio de sesión único.
El inicio de sesión único debería fallar si la cuenta de usuario se ha desactivado en AD.
........................
Problemas de opciones de DHCP con external/customer la configuración de AD
Si encuentra un error relacionado "The connection has been closed. Transport
error" con los escritorios virtuales de Windows al usar RES con su propio Active Directory, consulte el CloudWatch registro de dcv-connection-gateway Amazon para ver algo similar a lo siguiente:
Oct 28 00:12:30.626 INFO HTTP:Splicer Connection{id=263}: Websocket{session_id="96cffa6e-cf2e-410f-9eea-6ae8478dc08a"}: Connection initiated error: unreachable, server io error Custom { kind: Uncategorized, error: "failed to lookup address information: Name or service not known" } Oct 28 00:12:30.626 WARN HTTP:Splicer Connection{id=263}: Websocket{session_id="96cffa6e-cf2e-410f-9eea-6ae8478dc08a"}: Error in websocket connection: Server unreachable: Server error: IO error: failed to lookup address information: Name or service not known Oct 28 00:12:30.627 DEBUG HTTP:Splicer Connection{id=263}: ConnectionGuard dropped
Si utiliza un controlador de dominio de AD para las opciones de DHCP de su propia VPC, debe:
-
Agregue AmazonProvided DNS a los dos controladores de dominio. IPs
-
Establezca el nombre de dominio en ec2.internal.
Aquí se muestra un ejemplo. Sin esta configuración, el escritorio de Windows generará un error de transporte, ya que RES/DCV busca el nombre de host ip-10-0-x-xx.ec2.internal.

........................
Error de Firefox MOZILLA_PKIX_ERROR_REQUIRED_TLS_FEATURE_MISSING
Cuando utilizas el navegador web Firefox, es posible que aparezca el mensaje de error MOZILLA_PKIX_ERROR_REQUIRED_TLS_FEATURE_MISSING cuando intentes conectarte a un escritorio virtual.
........................
Eliminación de Env
........................
res-xxx-cluster se apilan en el estado «DELETE_FAILED» y no se pueden eliminar manualmente debido al error «El rol no es válido o no se puede asumir»
Si observa que la pila «res-xxx-cluster" está en el estado «DELETE_FAILED» y no se puede eliminar manualmente, puede realizar los siguientes pasos para eliminarla.
Si ves la pila en el estado «DELETE_FAILED», primero intenta eliminarla manualmente. Es posible que aparezca un cuadro de diálogo confirmando la opción Eliminar pila. Seleccione Eliminar.
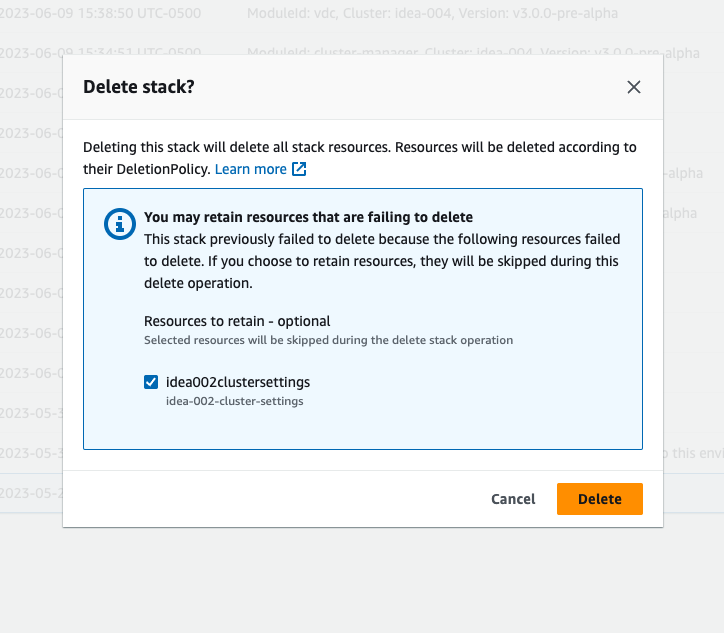
A veces, incluso si eliminas todos los recursos de la pila necesarios, es posible que sigas viendo el mensaje para seleccionar los recursos que deseas conservar. En ese caso, selecciona todos los recursos como «recursos a conservar» y selecciona Eliminar.
Es posible que veas un error parecido a Role: arn:aws:iam::... is Invalid or cannot
be assumed
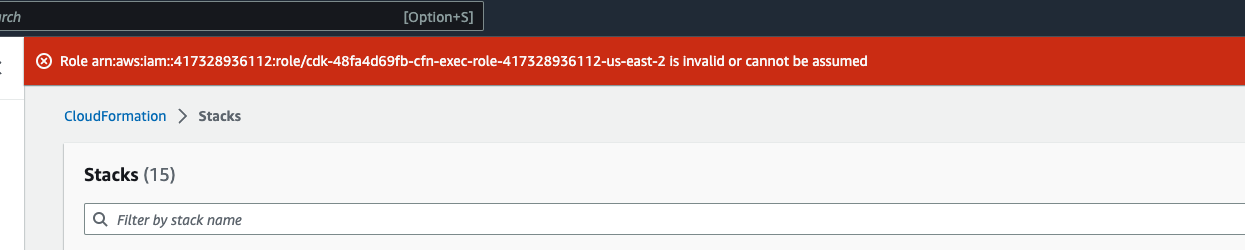
Esto significa que la función necesaria para eliminar la pila se eliminó primero antes que la pila. Para evitar esto, copia el nombre del rol. Vaya a la consola de IAM y cree un rol con ese nombre utilizando los parámetros que se muestran aquí, que son:
-
Para el tipo de entidad de confianza, seleccione AWS servicio.
-
En Caso de uso,
Use cases for other AWS servicesseleccioneCloudFormation.
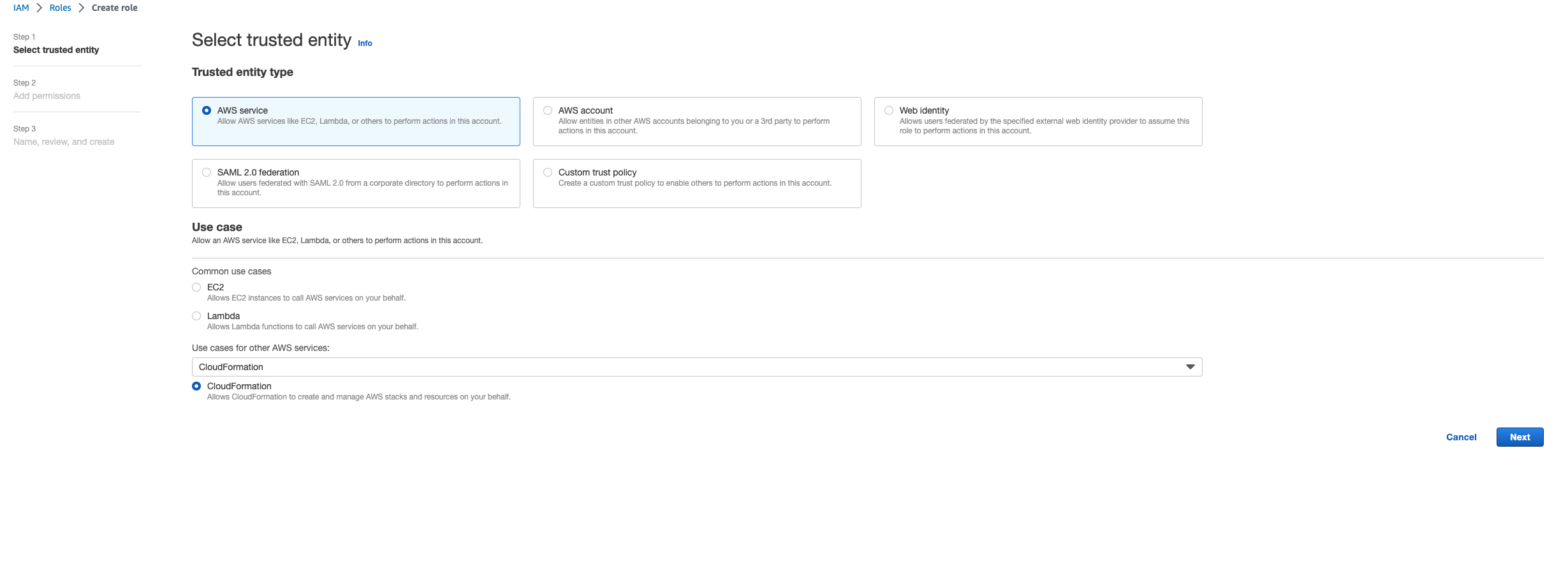
Seleccione Siguiente. Asegúrese de conceder los permisos «» y AWSCloudFormationFullAccess «AdministratorAccess» al rol. Tu página de reseñas debería tener este aspecto:
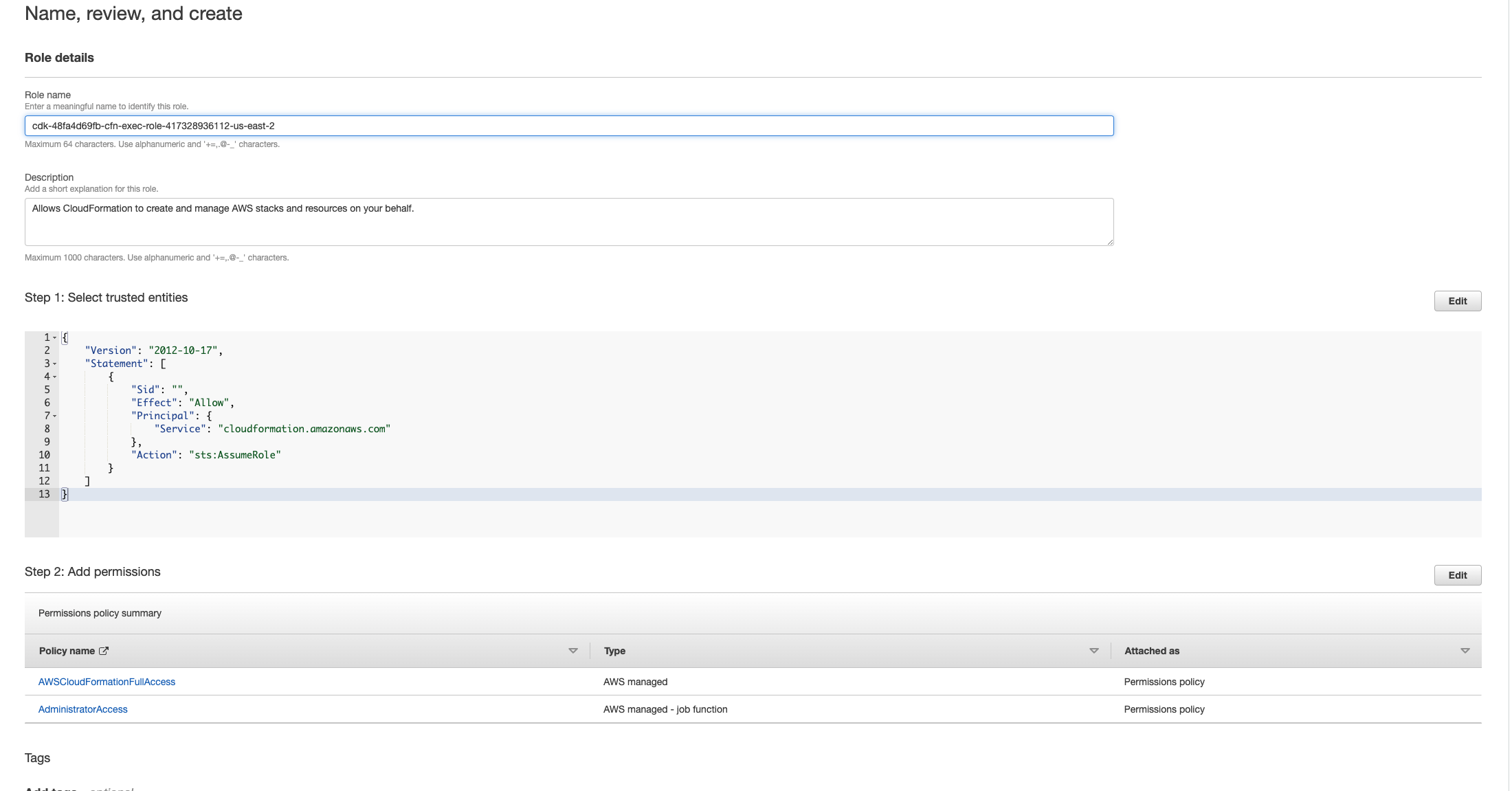
A continuación, vuelva a la CloudFormation consola y elimine la pila. Ahora deberías poder eliminarlo desde que creaste el rol. Por último, vaya a la consola de IAM y elimine el rol que creó.
........................
Recopilación de registros
Iniciar sesión en una EC2 instancia desde la EC2 consola
-
Sigue estas instrucciones para iniciar sesión en tu EC2 instancia de Linux.
-
Sigue estas instrucciones para iniciar sesión en tu EC2 instancia de Windows. A continuación, abre Windows PowerShell para ejecutar cualquier comando.
Recopilación de registros del host de Infrastructure
-
Administrador de clústeres: obtenga los registros para el administrador de clústeres de los siguientes lugares y adjúntelos al ticket.
-
Todos los registros del grupo de registros. CloudWatch
<env-name>/cluster-manager -
Todos los registros del
/root/bootstrap/logsdirectorio de la<env-name>-cluster-managerEC2 instancia. Sigue las instrucciones que aparecen en el enlace «Iniciar sesión en una EC2 instancia desde la EC2 consola» al principio de esta sección para iniciar sesión en tu instancia.
-
-
Controlador de VDC: Obtenga los registros del controlador de VDC de los siguientes lugares y adjúntelos al ticket.
-
Todos los registros del grupo de registros. CloudWatch
<env-name>/vdc-controller -
Todos los registros del
/root/bootstrap/logsdirectorio de la<env-name>-vdc-controllerEC2 instancia. Sigue las instrucciones que aparecen en el enlace «Iniciar sesión en una EC2 instancia desde la EC2 consola» al principio de esta sección para iniciar sesión en tu instancia.
-
Una de las maneras de obtener los registros fácilmente es seguir las instrucciones de la Descarga de registros de instancias de Linux EC2 sección. El nombre del módulo sería el nombre de la instancia.
Recopilación de registros de VDI
- Identifica la EC2 instancia de Amazon correspondiente
-
Si un usuario lanzara una VDI con un nombre de sesión
VDI1, sería<env-name>-VDI1-<user name>el nombre correspondiente de la instancia en la EC2 consola de Amazon. - Recopile los registros de VDI de Linux
-
Inicia sesión en la EC2 instancia de Amazon correspondiente desde la EC2 consola de Amazon siguiendo las instrucciones que aparecen en «Iniciar sesión en una EC2 instancia desde la EC2 consola» al principio de esta sección. Obtenga todos los registros de los
/var/log/dcv/directorios/root/bootstrap/logsy de la EC2 instancia de Amazon de VDI.Una de las formas de obtener los registros sería subirlos a s3 y luego descargarlos desde allí. Para ello, puedes seguir estos pasos para obtener todos los registros de un directorio y luego subirlos:
-
Siga estos pasos para copiar los registros dcv del
/root/bootstrap/logsdirectorio:sudo su - cd /root/bootstrap mkdir -p logs/dcv_logs cp -r /var/log/dcv/* logs/dcv_logs/ -
Ahora, siga los pasos que se indican en la siguiente sección Descarga de registros de VDI para descargar los registros.
-
- Recopile los registros de VDI de Windows
-
Inicia sesión en la EC2 instancia de Amazon correspondiente desde la EC2 consola de Amazon siguiendo las instrucciones que aparecen en «Iniciar sesión en una EC2 instancia desde la EC2 consola» al principio de esta sección. Coloca todos los registros en el
$env:SystemDrive\Users\Administrator\RES\Bootstrap\Log\directorio de la EC2 instancia de VDI.Una de las formas de obtener los registros sería subirlos a S3 y, a continuación, descargarlos desde allí. Para hacerlo, siga los pasos que se enumeran en la siguiente sección:Descarga de registros de VDI.
........................
Descarga de registros de VDI
Actualice la función de IAM de la EC2 instancia de VDI para permitir el acceso a S3.
Ve a la EC2 consola y selecciona tu instancia de VDI.
Seleccione el rol de IAM que está utilizando.
-
En la sección Políticas de permisos del menú desplegable Añadir permisos, seleccione Adjuntar políticas y, a continuación, elija la política de FullAccessAmazonS3.
Seleccione Añadir permisos para adjuntar esa política.
-
Después, siga los pasos que se indican a continuación en función del tipo de VDI para descargar los registros. El nombre del módulo sería el nombre de la instancia.
-
Descarga de registros de instancias de Linux EC2 para Linux.
-
Descargar registros de EC2 instancias de Windowspara Windows.
-
-
Por último, edite el rol para eliminar la
AmazonS3FullAccesspolítica.
nota
Todos VDIs utilizan el mismo rol de IAM, que es <env-name>-vdc-host-role-<region>
........................
Descarga de registros de instancias de Linux EC2
Inicia sesión en la EC2 instancia desde la que quieres descargar los registros y ejecuta los siguientes comandos para cargar todos los registros en un bucket de s3:
sudo su - ENV_NAME=<environment_name>REGION=<region>ACCOUNT=<aws_account_number>MODULE=<module_name>cd /root/bootstrap tar -czvf ${MODULE}_logs.tar.gz logs/ --overwrite aws s3 cp ${MODULE}_logs.tar.gz s3://${ENV_NAME}-cluster-${REGION}-${ACCOUNT}/${MODULE}_logs.tar.gz
Después, vaya a la consola S3, seleccione el bucket con su nombre <environment_name>-cluster-<region>-<aws_account_number> y descargue el <module_name>_logs.tar.gz archivo cargado anteriormente.
........................
Descargar registros de EC2 instancias de Windows
Inicie sesión en la EC2 instancia desde la que desee descargar los registros y ejecute los siguientes comandos para cargar todos los registros en un bucket de S3:
$ENV_NAME="<environment_name>" $REGION="<region>" $ACCOUNT="<aws_account_number>" $MODULE="<module_name>" $logDirPath = Join-Path -Path $env:SystemDrive -ChildPath "Users\Administrator\RES\Bootstrap\Log" $zipFilePath = Join-Path -Path $env:TEMP -ChildPath "logs.zip" Remove-Item $zipFilePath Compress-Archive -Path $logDirPath -DestinationPath $zipFilePath $bucketName = "${ENV_NAME}-cluster-${REGION}-${ACCOUNT}" $keyName = "${MODULE}_logs.zip" Write-S3Object -BucketName $bucketName -Key $keyName -File $zipFilePath
Después, vaya a la consola S3, seleccione el bucket con su nombre <environment_name>-cluster-<region>-<aws_account_number> y descargue el <module_name>_logs.zip archivo cargado anteriormente.
........................
Recopilación de registros de ECS para detectar el WaitCondition error
-
Ve a la pila implementada y selecciona la pestaña Recursos.
-
Expanda Implementar ResearchAndEngineeringStudio→ Instalador → Tareas CreateTaskDef→ CreateContainer→ → LogGroupy seleccione el grupo de registros para abrir CloudWatch los registros.
-
Obtenga el registro más reciente de este grupo de registros.
........................
Entorno de demostración
........................
Error de inicio de sesión en el entorno de demostración al gestionar la solicitud de autenticación al proveedor de identidad
Problema
Si intentas iniciar sesión y aparece un «error inesperado al tramitar la solicitud de autenticación al proveedor de identidad», es posible que tus contraseñas estén caducadas. Puede ser la contraseña del usuario con el que intenta iniciar sesión o su cuenta de Active Directory Service.
Mitigación
-
Restablezca las contraseñas de usuario y cuenta de servicio en la consola de servicio de Directory
. -
Actualice las contraseñas de las cuentas de servicio en Secrets Manager
para que coincidan con la nueva contraseña que ingresó anteriormente: -
para la pila Keycloak: -... PasswordSecret - -... RESExternal - DirectoryService-... con descripción: Contraseña para Microsoft Active Directory
-
para RES: res- ServiceAccountPassword -... con descripción: contraseña de la cuenta de Active Directory Service
-
-
Vaya a la EC2 consola
y finalice la instancia del administrador de clústeres. Las reglas de Auto Scaling activarán automáticamente el despliegue de una nueva instancia.
........................
