OPS10-BP02 Implementación de un proceso por alerta
Establecer un proceso claro y definido para cada alerta de su sistema es esencial para una administración de incidentes eficaz y eficiente. Esta práctica garantiza que cada alerta genere una respuesta específica y procesable, lo que mejora la fiabilidad y la capacidad de respuesta de sus operaciones.
Resultado deseado: cada alerta inicia un plan de respuesta específico y bien definido. Siempre que sea posible, las respuestas se automatizan, con una propiedad clara y una ruta de escalado definida. Las alertas están vinculadas a una base de conocimientos actualizada para que cualquier operador pueda responder de forma coherente y eficaz. Las respuestas son rápidas y uniformes en todos los ámbitos, lo que mejora la eficiencia y la fiabilidad operativas.
Patrones comunes de uso no recomendados:
-
Las alertas no tienen un proceso de respuesta predefinido, lo que lleva a resoluciones improvisadas y tardías.
-
La sobrecarga de alertas hace que se pasen por alto alertas importantes.
-
Las alertas se gestionan de forma incoherente debido a la falta de propiedad y responsabilidad claras.
Beneficios de establecer esta práctica recomendada:
-
Se ha reducido la fatiga de las alertas al generar solo alertas procesables.
-
Disminución del tiempo medio de resolución (MTTR) de los problemas operativos.
-
Disminución del tiempo medio de investigación (MTTI), lo que ayuda a reducir el MTTR.
-
Mejora de la capacidad para escalar las respuestas operativas.
-
Mejora de la coherencia y la fiabilidad en la gestión de los eventos operativos.
Por ejemplo, cuenta con un proceso definido para eventos de AWS Health para cuentas críticas, incluidas las alarmas de operaciones, los problemas operativos, los eventos de ciclo de vida planificados (como actualizar las versiones de Amazon EKS antes de que los clústeres se actualicen automáticamente) y ofrece a sus equipos la capacidad para monitorear activamente estos eventos, comunicarse y responder al respecto. Estas acciones lo ayudan a evitar las interrupciones del servicio causadas por cambios en AWS o mitigarlas más rápidamente cuando se producen problemas inesperados.
Nivel de riesgo expuesto si no se establece esta práctica recomendada: alto
Guía para la implementación
Tener un proceso por alerta implica establecer un plan de respuesta claro para cada alerta, automatizar las respuestas siempre que sea posible y perfeccionar continuamente estos procesos en función de los comentarios operativos y los requisitos en evolución.
Pasos para la implementación
El siguiente diagrama muestra el flujo de trabajo de administración de incidentes en Administrador de incidentes de AWS Systems Manager
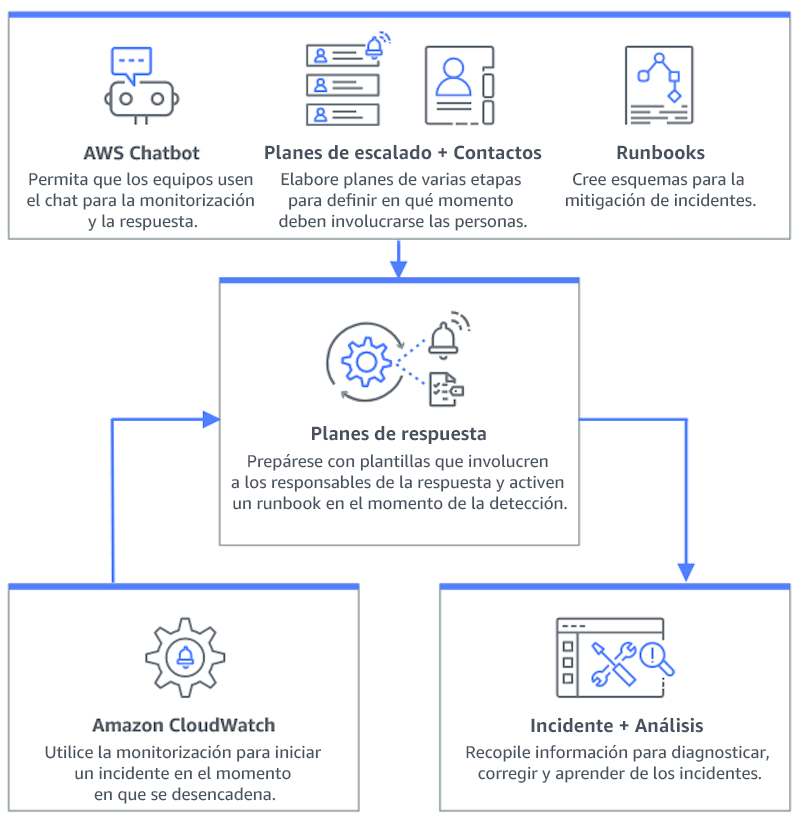
-
Uso de alarmas compuestas: cree alarmas compuestas en CloudWatch para agrupar las alarmas relacionadas, reducir el ruido y permitir respuestas más significativas.
-
Manténgase informado con AWS Health: AWS Health es la fuente autorizada de información sobre el estado de los recursos de Nube de AWS. Utilice AWS Health para visualizar y recibir notificaciones de cualquier evento de servicio actual y de los próximos cambios, como los eventos de ciclo de vida planificados, de forma que pueda tomar medidas para mitigar los impactos.
-
Cree notificaciones de eventos de AWS Health adaptadas al propósito para el correo electrónico y los canales de chat a través de AWS User Notifications e intégrelas mediante programación con las herramientas de supervisión y alerta a través de Amazon EventBridge o la API de AWS Health.
-
Planifique y realice un seguimiento del progreso de los eventos de estado que requieran una acción mediante la integración con herramientas de administración de cambios o ITSM (como Jira o ServiceNow) que ya pueda utilizar a través de Amazon EventBridge o la API de AWS Health.
-
Si usa AWS Organizations, habilite la vista de organización para AWS Health a fin de agregar eventos de AWS Health en todas las cuentas.
-
-
Integración de las alarmas de Amazon CloudWatch con el Administrador de incidentes: configure las alarmas de CloudWatch para crear incidentes automáticamente en Administrador de incidentes de AWS Systems Manager.
-
Integración de Amazon EventBridge con el Administrador de incidentes: cree reglas de EventBridge para reaccionar ante los eventos y crear incidentes mediante planes de respuesta definidos.
-
Preparación para incidentes en el Administrador de incidentes:
-
Establezca planes de respuesta detallados en el Administrador de incidentes para cada tipo de alerta.
-
Establezca canales de chat mediante Amazon Q Developer en aplicaciones de chat conectadas a los planes de respuesta del Administrador de incidentes, lo que facilita la comunicación en tiempo real durante los incidentes en plataformas como Slack, Microsoft Teams y Amazon Chime.
-
Incorpore manuales de procedimientos de Automatización de Systems Manager en el Administrador de incidentes para impulsar respuestas automatizadas a los incidentes.
-
Recursos
Prácticas recomendadas relacionadas:
Documentos relacionados:
Videos relacionados:
Ejemplos relacionados:
